
Scaling GenAI for 200M users: How SNOW Corp. orchestrates 1000+ GPUs to handle 700% viral traffic spikes
Challenge
SNOW Corp., a subsidiary of NAVER from South Korea, operates a fleet of 1,000+ A100 GPUs serving GenAI features for 200M+ global users across three top-ranked apps (SNOW, EPIK, B612). [1] The infrastructure serves 1,200+ AI workflows and 400+ models. The organization experienced 700% viral traffic spikes – meaning traffic patterns were unpredictable and highly volatile. The scale combined with volatility created an operational nightmare for resource allocation.
The core problem: Kubernetes’ native GPU scheduling treats GPUs as atomic resources. A pod either gets a full GPU or nothing. This model breaks down under two conditions:
- Heterogeneous workload demands: Training pipelines, inference services, and batch processing have vastly different GPU utilization profiles. A training job might consume 80% of GPU compute but only 20% of memory, while an inference service might have the opposite profile.
- Traffic unpredictability: Due to extreme traffic volatility from viral AI trends and heterogeneous inference workflows, the system needed to scale elastically. But without visibility into actual GPU utilization, scaling decisions were either manual (operational hell) or based on crude CPU/memory metrics that don’t reflect GPU saturation.
Before Kubernetes adoption, Snow Corp ran Docker-based infrastructure with manual GPU assignment. This approach had fundamental flaws:
Previous infrastructure limitations
- Scheduling blindness: 2-3 containers in the same pod competed for GPU resources with no coordination
- Manual scaling: Humans manually provisioned GPUs based on load predictions, not actual demand
Kubernetes migration issues
- No GPU sharing: Multiple containers could not efficiently share a single GPU
- Cost explosion: To handle peak loads, the organization had to over-provision by approximately 2x (one GPU for training, one for inference, when one could theoretically suffice)
The observability gap
- The organization lacked GPU-level observability. Kubernetes’ HPA could scale based on CPU and memory metrics, but these are poor proxies for GPU saturation.

Projects used







Solution
Cloud Native Computing Foundation (CNCF)
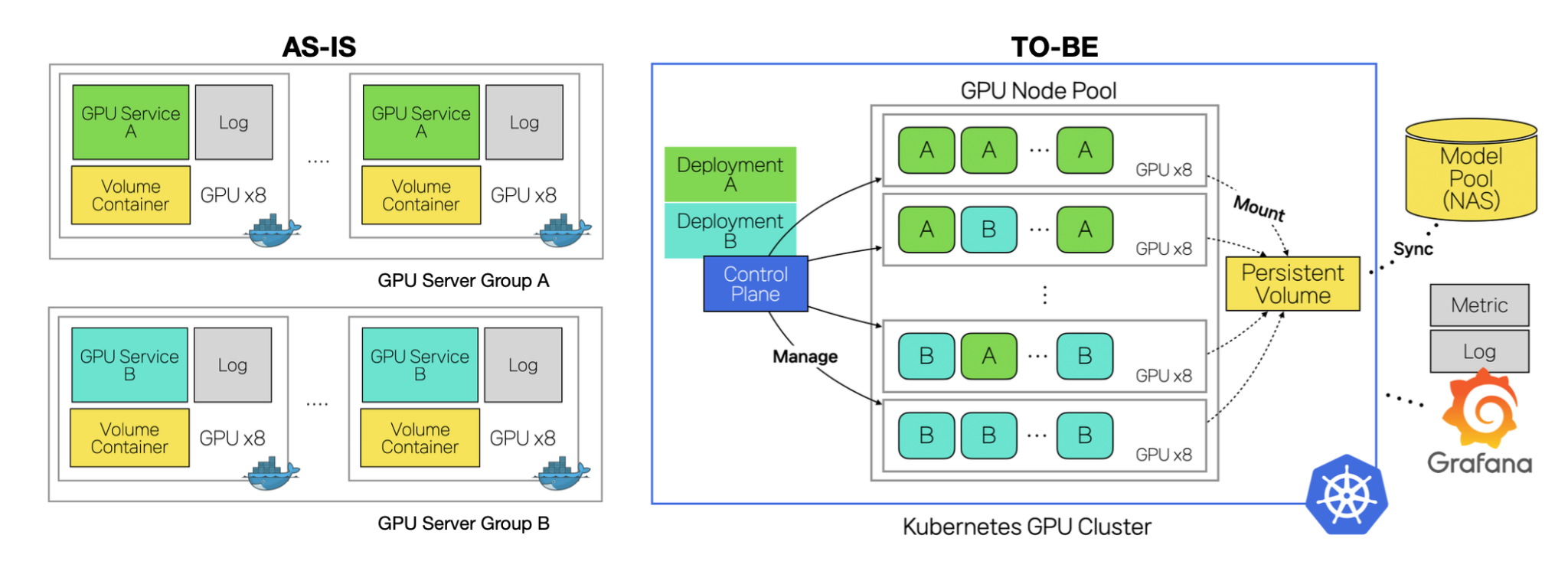
SNOW migrated to a multi-region on-premise Kubernetes platform with decoupled External ETCD topology for high availability. The CNCF ecosystem underpins the entire stack: Cilium for CNI, Helm for GitOps-based deployment, Traefik for ingress, Prometheus/Loki/Grafana for observability, HAMi for GPU sharing, [2] and KEDA for autoscaling. [3]
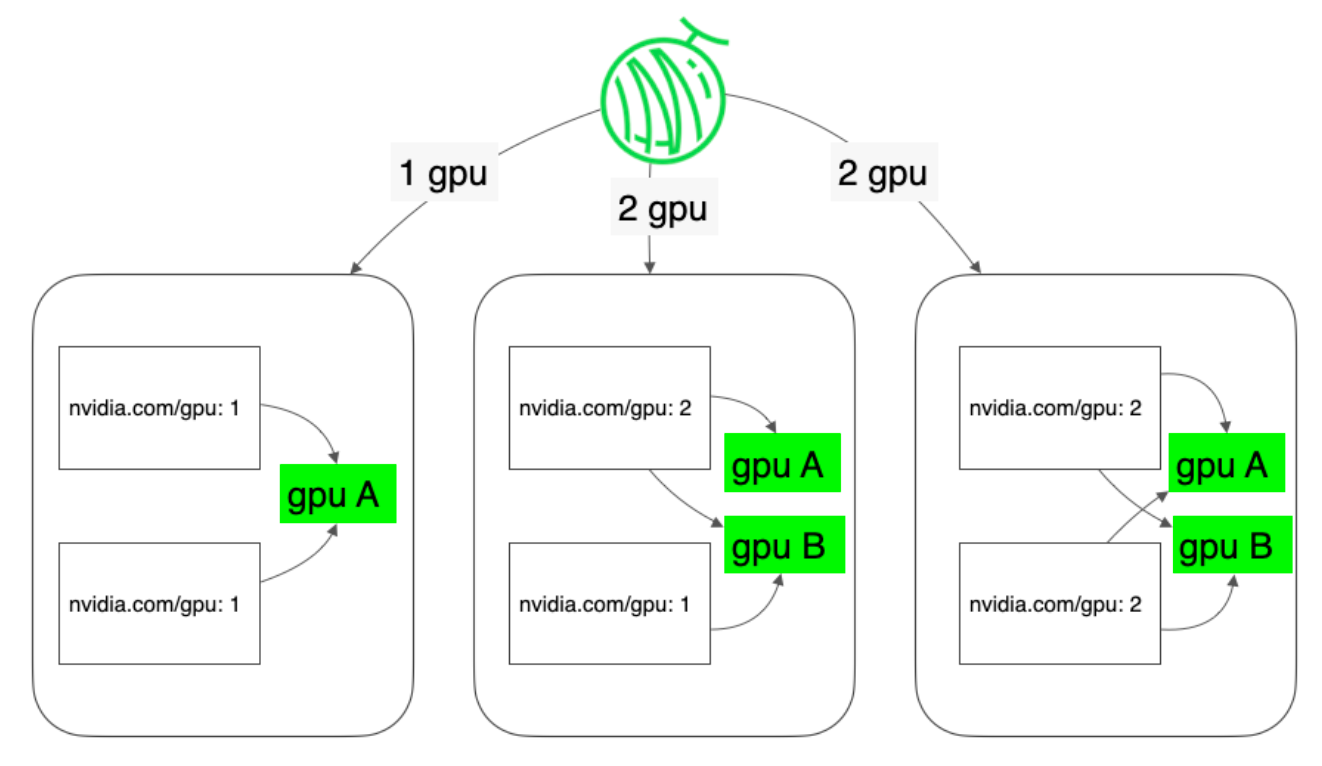
GPU sharing with HAMi
Kubernetes’ default scheduler enforces strict GPU isolation, which blocked migration of SNOW’s sequential Train-to-Inference pipelines — where a trainer and inference engine must share a single GPU. HAMi resolves this by virtualizing GPU resources (vGPU), enabling multiple containers within the same pod to share a single GPU concurrently. [2] It integrates natively with kube-scheduler with zero changes to existing application code, and is fully compatible with the broader autoscaling ecosystem.
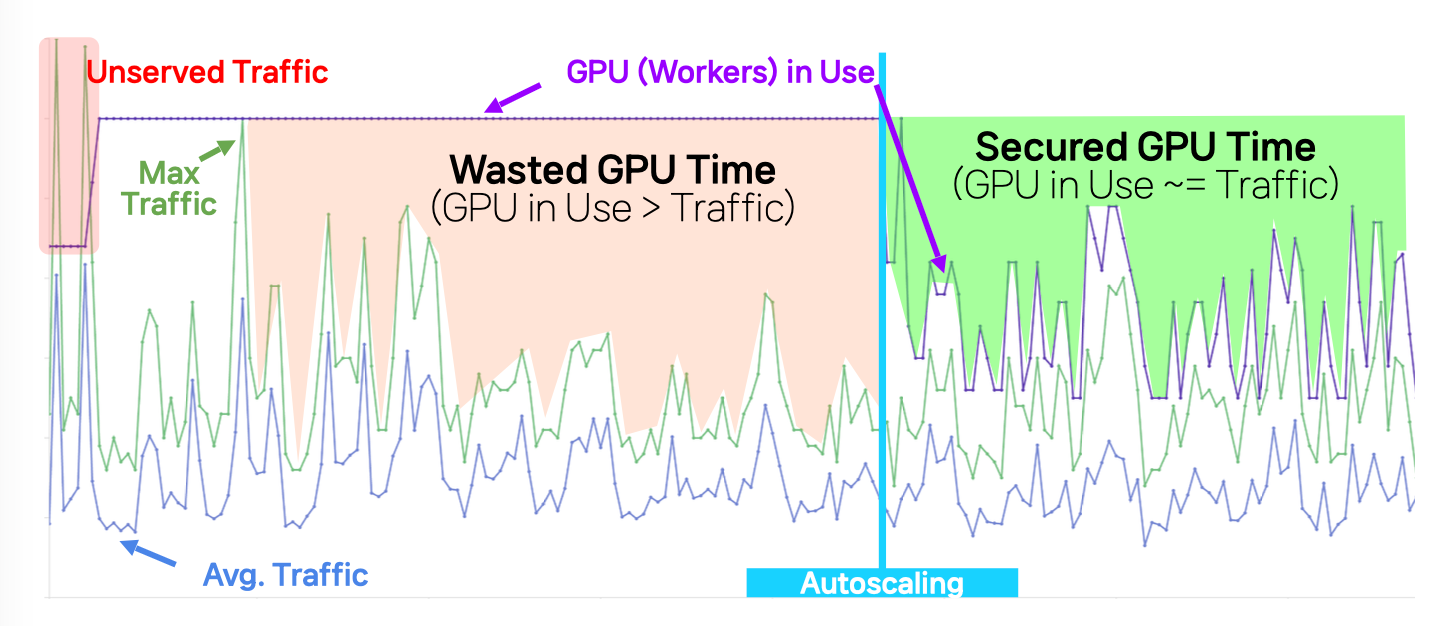
Proactive GPU orchestration with KEDA
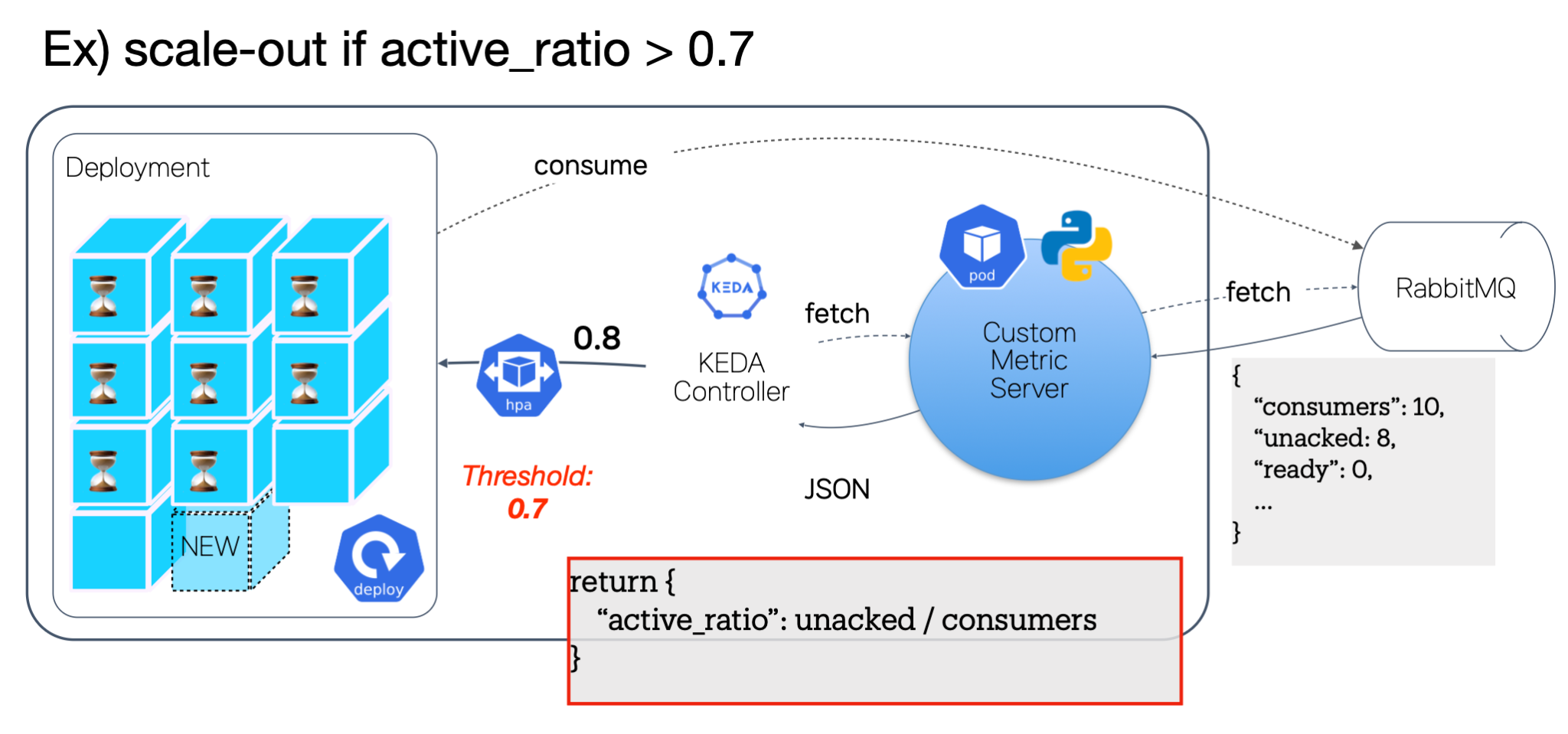
Standard metrics (CPU/RAM, DCGM utilization) proved unreliable for SNOW’s heterogeneous workloads, and KEDA’s built-in RabbitMQ scaler functioned as a lagging indicator — given a ~60-second model warm-up time, scaling triggered after a queue backlog formed was consistently too late.
To address this, SNOW developed a lightweight Custom Metric Server (Python/FastAPI) exposing a Consumer Saturation metric to KEDA’s Metrics API Scaler:
active_ratio = unacked_messages / active_consumers
When active_ratio exceeds a threshold (e.g., 0.7), KEDA provisions new GPU pods before the worker pool saturates, absorbing the warm-up window proactively. For scale-in, longer stabilizationWindowSeconds and cooldownPeriod values prevent premature deallocation during traffic lulls.
Impact and Results
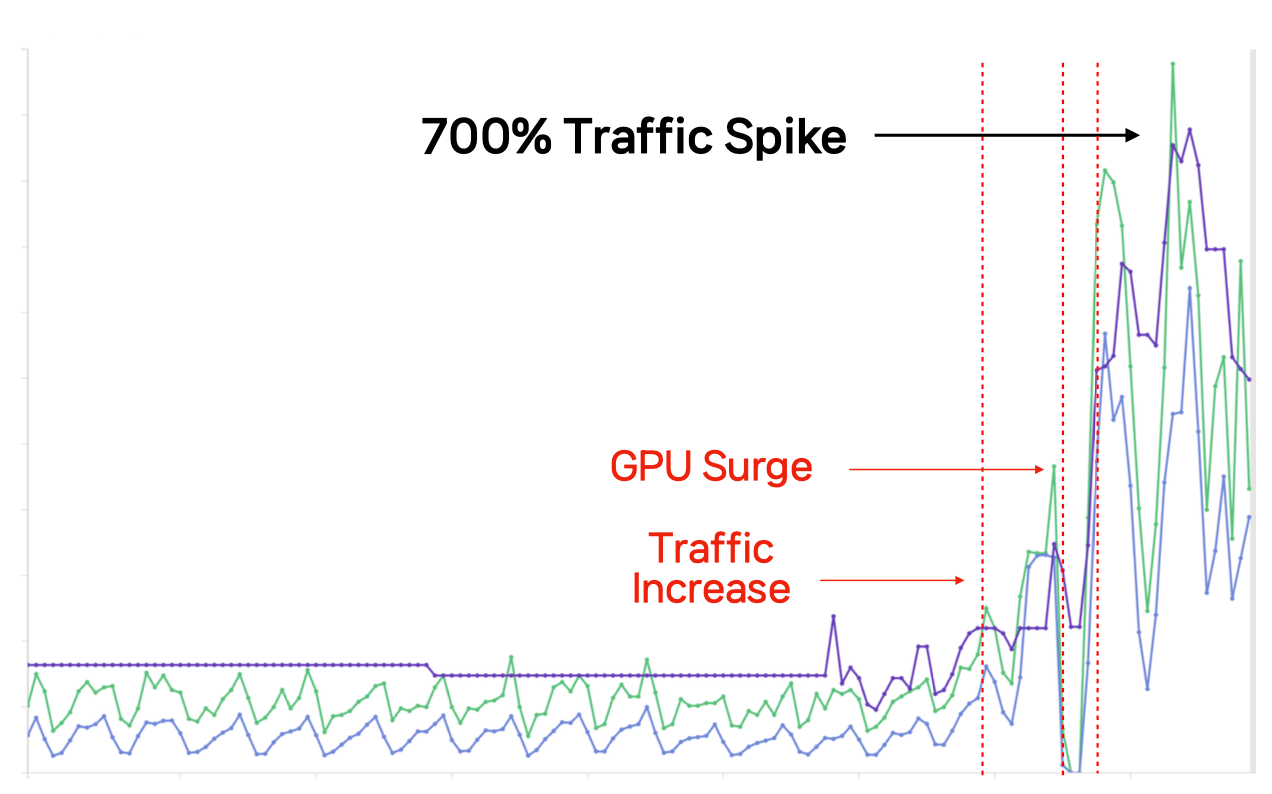
Handling 700% Traffic Spikes through Hybrid Cloud Bursting
When the viral “Ghibli Filter” trend tripled traffic within 3 hours on a low-staff Saturday morning, on-premise capacity alone was insufficient. Autoscaling initially held, but throttling ensued due to GPU surge, urgently demanding a strategic pivot to resolve GPU saturation before the viral trend faded. To address, SNOW expanded dynamically into CSP regions using a unified GitOps pipeline that deployed identical Helm charts across all clusters. CSP worker nodes consumed tasks directly from the central RabbitMQ queue, enabling seamless multi-cluster scaling with zero service interruption. While successfully multiplying consumed traffic to 7x peak levels, SNOW secured the business opportunity through an autonomous pipeline.
Operational Efficiency
- MTTR Improvement: MTTR reduced by 91% (from ~2 hrs to ~10 min.)
- Reduction in Surge Errors: GPU Surge-related user errors dropped by 85% during peak traffic due to proactive scaling.
- Manual Scaling Eliminated: The organization moved from human-driven GPU provisioning to automated, metric-driven scaling. This eliminated the “operational hell” of manual allocation. Operational cost reduction equivalent to 10.8 Man-month savings.
Cost Optimization
- Proactive Autoscaling
- reduced average GPU usage time by 55%
- USD 17.4M in estimated cost savings compared to equivalent on-demand cloud GPU provisioning (USD ~45/hr per A100)
- GPU sharing via HAMi
- HAMi’s GPU sharing capabilities eliminated the need for a full infrastructure re-architecture, significantly reducing migration complexity and engineering overhead.
- GPU requirement reduction
- 2x fewer GPUs needed for training + inference pipelines.
SNOW Corp.’s cloud-native transformation demonstrates how combining Kubernetes with the broader CNCF ecosystem can overcome fundamental limitations in GPU scheduling and observability at extreme scale. By introducing HAMi for GPU sharing and augmenting KEDA with proactive, custom metrics, SNOW shifted from reactive, manual operations to predictive, automated orchestration. This architecture not only enabled the platform to absorb 700% traffic spikes and scale across hybrid environments without disruption, but also delivered substantial gains in cost efficiency, reliability, and operational velocity. Ultimately, SNOW’s approach highlights a replicable blueprint for running large-scale GenAI workloads—where intelligent resource utilization, autoscaling precision, and deep observability are critical to turning infrastructure challenges into competitive advantage.
References
- [1] a16z, “The Top 100 [Gen AI] Consumer Apps”, https://a16z.com/100-gen-ai-apps-5/
- [2] HAMi, https://project-hami.io/
- [3] KEDA, https://keda.sh/
Contacts:
– Jeonghyun Kim, AI Engineer – Email: jeonghyun@snowcorp.com
– Jae Do Chung, SVP of Engineering – Email: jaedo.chung@snowcorp.com