We are thrilled to announce that llm-d has officially been accepted as a Cloud Native Computing Foundation (CNCF) Sandbox project!
As generative AI transitions from research labs to production environments, platform engineering teams are facing a new frontier of infrastructure challenges. llm-d is joining the CNCF to lead the evolution of Kubernetes and the broader CNCF landscape into State of the Art (SOTA) AI infrastructure, treating distributed inference as a first-class cloud native workload. By joining the CNCF, llm-d secures the trusted stewardship and open governance of the Linux Foundation, giving organizations the confidence to build upon a truly neutral standard.
Launched in May 2025 as a collaborative effort between Red Hat, Google Cloud, IBM Research, CoreWeave, and NVIDIA, llm-d was founded with a clear vision: any model, any accelerator, any cloud. The project was joined by industry leaders AMD, Cisco, Hugging Face, Intel, Lambda and Mistral AI and university supporters at the University of California, Berkeley, and the University of Chicago.
“At Mistral AI, we believe that optimizing inference goes beyond just the engine, and requires solving challenges like KV cache management and disaggregated serving to support next-generation models such as Mixture of Experts (MoE). Open collaboration on these issues is essential to building flexible, future-proof infrastructure. We’re supporting this effort by contributing to the llm-d ecosystem, including the development of a DisaggregatedSet operator for LeaderWorkerSet (LWS), to help advance open standards for AI serving.” – Mathis Felardos, Inference Software Engineer, Mistral AI
What llm-d brings to the CNCF landscape
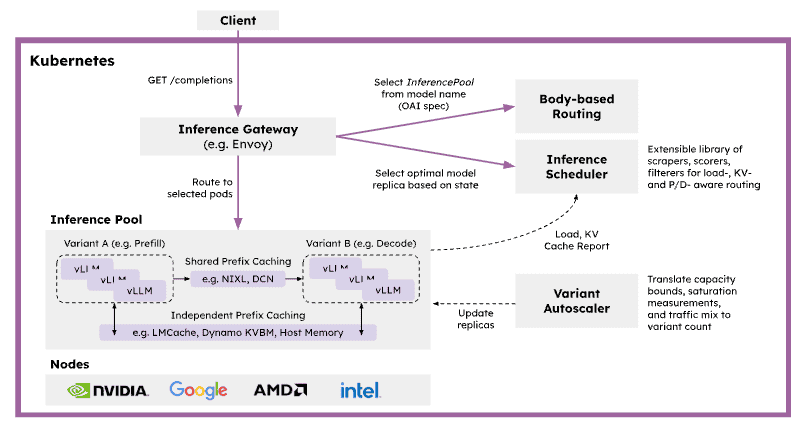
The CNCF is the natural home for solving complex workload orchestration challenges. AI serving is highly stateful and latency-sensitive, with request costs varying dramatically based on prompt length, cache locality, and model phase. Traditional service routing and autoscaling mechanisms are unaware of this inference state, leading to inefficient placement, cache fragmentation, and unpredictable latency under load. llm-d solves this by providing a pre-integrated, Kubernetes-native distributed inference framework that bridges the gap between high-level control planes (like KServe) and low-level inference engines (like vLLM). llm-d plans to work with the CNCF AI Conformance program to ensure critical capabilities like disaggregated serving are interoperable across the ecosystem.
By building on open APIs and extensible gateway primitives, llm-d introduces several critical capabilities to the CNCF ecosystem:
- Inference-Aware Traffic Management: Acting as a primary implementation of the Kubernetes Gateway API Inference Extension (GAIE), llm-d utilizes the Endpoint Picker (EPP) for programmable, prefix-cache-aware routing.
- Native Kubernetes Orchestration: Leveraging primitives like LeaderWorkerSet (LWS), llm-d orchestrates complex multi-node replicas and wide expert parallelism, transforming bespoke AI infrastructure into manageable cloud native microservices.
- Prefill/Decode Disaggregation: llm-d addresses the resource-utilization asymmetry between prompt processing and token generation by disaggregating these phases into independently scalable pods.
Advanced State Management: The project introduces hierarchical KV cache offloading across GPU, TPU, CPU, and storage tiers.
SOTA inference performance on any accelerator
A core tenet of the cloud native philosophy is preventing vendor lock-in. For AI infrastructure, this means serving capabilities must be hardware-agnostic.
We believe that democratizing SOTA inference with an accelerator-neutral mindset is the most important enabler for broad LLM adoption. The primary mission of llm-d is to Achieve SOTA Inference Performance On Any Accelerator. By introducing model- and state-aware routing policies that align request placement with specific hardware characteristics, llm-d maximizes utilization and delivers measurable gains in critical inference metrics like Time to First Token (TTFT), Time Per Output Token (TPOT), token throughput, and KV cache utilization. Whether you are running workloads on accelerators from NVIDIA, AMD, or Google, llm-d ensures that high-performance AI serving remains a core, composable capability of your stack.
Crucially, clear benchmarks that prove the value of these optimizations are core to the project. The AI industry often lacks standard, reproducible ways to measure inference performance, relying instead on marketing claims or commercial analysts. llm-d aims to be the neutral, de facto standard for defining and running inference benchmarks through rigorous, open benchmarking. For example, in a ‘Multi-tenant SaaS’ use case, shared customer contexts enable significant computational savings through prefix caching. As demonstrated in the most recent v0.5 release, llm-d’s inference scheduling maintains near-zero latency and massive throughput compared to a baseline Kubernetes service:
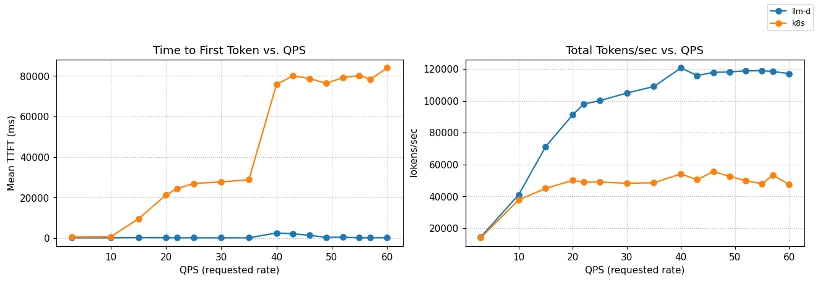
Figure 1: TTFT and throughput vs QPS on Qwen3-32B (8×vLLM pods, 16×NVIDIA H100).
llm-d inference scheduling maintains near-zero TTFT and scales to ~120k tok/s,
while baseline Kubernetes service degrades rapidly under load.
Bridging cloud native and AI native ecosystems
To build the ultimate AI infrastructure, we must bridge the gap between Kubernetes orchestration and frontier AI research. llm-d is actively building deep relationships with AI/ML leaders at large foundation model builders and AI natives, along with traditional enterprises that are rapidly integrating AI throughout their organizations. Furthermore, we are committed to increasing collaboration with the PyTorch Foundation to ensure a seamless, end-to-end open ecosystem that connects model development and training directly to distributed cloud native serving.
Get involved: Follow the “well-lit paths”
At its core, llm-d follows a “well-lit paths” philosophy. Instead of leaving platform teams to piece together fragile black boxes, llm-d provides validated, production-ready deployment patterns—benchmarked recipes tested end-to-end under realistic load.
We invite developers, platform engineers, and AI researchers to join us in shaping the future of open AI infrastructure:
- Explore the Well-Lit Paths: Visit the llm-d guides to start deploying SOTA inference stacks on your infrastructure today.
- Learn More: Check out the official website at llm-d.ai.
- Contribute: Join the community on slack and get involved in our GitHub repositories at https://github.com/llm-d/.
Welcome to the CNCF, llm-d! We look forward to building the future of AI infrastructure together.