
KubeCon + CloudNativeCon Europe 2021 – Virtual sponsored post by Sirish Bathina of Kasten by Veeam
Flexible storage options are one of the many benefits of developing apps in Kubernetes, but choosing the right one can be a challenge. Depending on your app’s requirements and characteristics, one solution might be better than the other. But no matter the type of application, performance is always important.
A new open-source project called Kubestr provides a simple way to identify, validate and evaluate storage options for Kubernetes applications. Kubestr is able to evaluate the relative performance levels of various storage configurations across cloud providers. So, in an attempt to demonstrate Kubetr’s utility, I decided to run it against a variety of configurations and crown the winner as “best storage provider.”
Unfortunately, I quickly discovered that this task was impossible, because each cloud provider comes with an abundance of customization options, all of which impact performance. This led me on a journey to see how I could use kubester to achieve the desired performance for four different providers: DigitalOcean, Google, AWS, and Azure.
The Test
./kubestr fio -s <storageclass>The program above runs the default Kubestr fio test on a 100 GiB volume of a specified storageclass.
The default test consists of four jobs:
- 4K blocksize randreads to get read IOPs
- 4K blocksize randwrites to get write IOPs
- 128K blocksize randreads to get read BW
- 128K blocksize randwrites to get write BW
NOTE A custom fio config can be passed using the -f option:
./kubestr fio -s <storageclass> -f <fiofile> where the fiofile follows the .fio format. Here are some examples.
I wanted to run this test against the same (or similar) infrastructure. For the most part, these tests are run on general-purpose nodes that have 2CPUs and 8GiB of memory.
DigitalOcean …and dedicated resources
I started with DigitalOcean because, up until recently, I had free credits. Using an automated script that I’ve used for the last year to deploy clusters, I created a 3-node cluster, where the type of node was s-2vcpu-4gb (You’ll notice that the amount of memory in these nodes is less than what I advertised earlier).
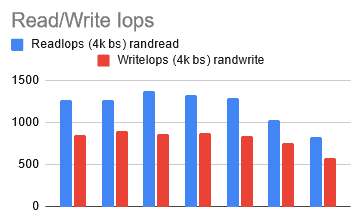
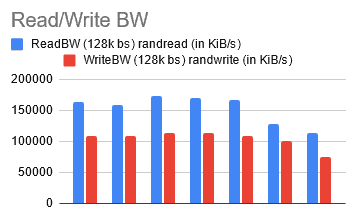
After running the test a few times, I started to notice that with the same parameters, I was encountering different results. As I questioned why this was happening, I discovered that DigitalOcean offers two types of VMs, shared and dedicated. Until now, the VMs (or Droplets as they call them) were being shared with my coworkers, making the statistics unreliable. So, I decided to switch to the smallest dedicated node that they offered, g-2vcpu-8gb. This is how I ended up with my choice of node (it will change again later).
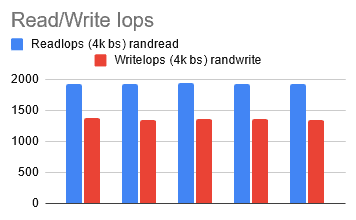
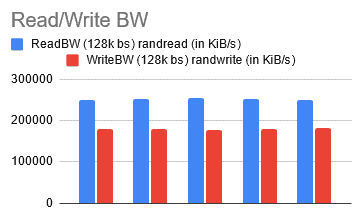
After running the tests a few more times, I started seeing some consistency. This is also how I reached somewhat of a benchmark goal for my remaining tests.
[ReadIops: 1900, WriteIops: 1300 , ReadBW: 250 MiB/S, WriteBW: 180 MiB/S]
I wanted to see what it would take to get roughly the same results across all providers.
Google Cloud …where size matters
Next up was Google Cloud. I tried to recreate the environment I had in DigitalOcean. This meant a GKE cluster with three e2-standard-2 nodes (2cpu, 8GB). For the storage type, I decided to go with the faster option, pd-ssd. On my first few runs, the numbers were not what I expected- > [rIops: 695, wIops: 370, rBW: 86 MiB/S, wBW: 46 MiB/S].
Then I learned that you could achieve better performance by increasing the size of your storage.
NOTE Kubestr takes a volume size using the -z option:
./kubestr fio -s <storageclass> -z <size> 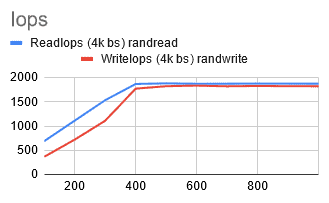
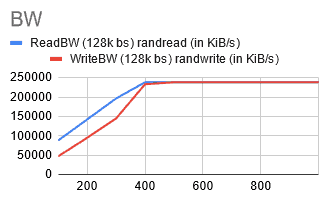
I noticed that the numbers started to increase as I chose larger volume sizes, reaching their peak at around 400 GiB.
@ 400GiB [rIops: 1870, wIops: 1775, rBW: 232 MiB/S, wBW: 227 MiB/S]
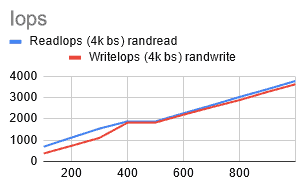
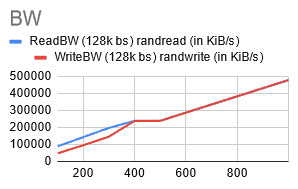
Much better! At this point the performance was capped by the size of nodes and by choosing bigger nodes (8vCPUs or higher), and I was able to see even higher outputs.
AWS …nodes knows
With AWS, I started with m4.large nodes. These fit the bill (2cpu, 8GB) and were part of their general-purpose nodes. However, I wasn’t seeing the results I wanted with either storage types they offered.
gp2 [rIops: 442, wIops: 358, rBW: 51 MiB/S, wBW: 41 MiB/S]
io1 [rIops: 466, wIops: 357, rBW: 52 MiB/S, wBW: 41 MiB/S]
I should also note that changing the size of the volumes had little to no impact on the results. At this point, a coworker pointed out that the latest general-purpose instance offered, m5, comes with improved networking. As I switched to m5.large nodes, I immediately noticed an improvement with the io1 storage type.
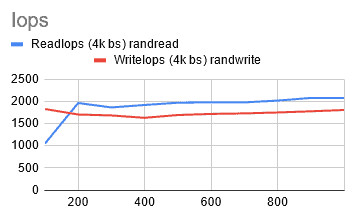
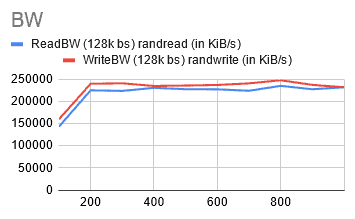
@400GiB [rIops: 1924, wIops: 1634, rBW: 225 MiB/S, wBW: 229 MiB/S]
I was getting the results I wanted and it seemed that increasing the volume size had a modest impact. The results of the gp2 storage type were inconsistent, but AWS has released a new storage type, gp3, which is designed to provide more predictable performance.
Azure …lots of options
With Azure I definitely had an abundance of options. I set out to find something that matched my desired specifications, and I first landed on a node type of Standard_D2_v3. Maybe I should have done a bit more reading before choosing that, because I soon figured out that those nodes don’t support premium storage options. I learnt that nodes that do support premium storage are denoted with an “s.” So, I switched to using Standard_D2s_v4 nodes but didn’t get the results I wanted.
@ 500GiB [rIops: 588, wIops: 404, rBW: 66 MiB/S, wBW: 42 MiB/S].
I took another look at my options and saw that they had nodes with local storage, denoted by “d.” Unaware of the potential benefit, I switched to Standard_D2ds_v4 nodes. This also yielded similar results:
@ 500GiB [rIops: 598, wIops: 416, rBW: 66 MiB/S, wBW: 42 MiB/S]
I was starting to lose hope. I decided to try one more thing: increasing the node size. I switched to Standard_D8ds_v4 nodes with eight vCPUs and 32 GiB memory, and voila!
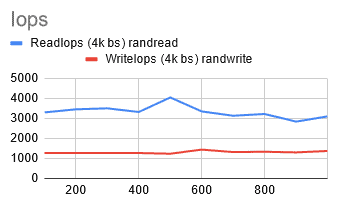
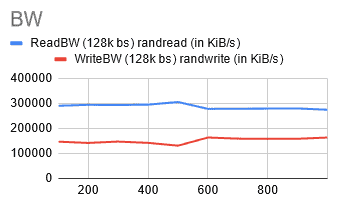
@ 400 GiB [rIops: 3316, wIops: 1276, rBW: 287 MiB/S, wBW: 139 MiB/S]
I was finally seeing the results I wanted!
Wrap up
Nodes mount the storage and drive the I/O to volumes, so it makes sense that differences in nodes can lead to changes in performance. The three main things I’ve gathered when choosing a node:
- Shared vs. dedicated: Both DO and GKE offer shared instances which can be great to keep costs low during development or for smaller applications. However, as you move to production and need more reliable performance, you may want to consider using dedicated resources.
- Type of nodes: In this exercise, I stuck to using the various general-purpose nodes offered by the providers. Even with AWS, some nodes were better suited for storage than others. The cloud providers also offer specialized nodes for specific application needs. For example, Azure has their Lsv2-series nodes that are optimized for storage.
- Size of nodes: Bigger is better. In this case more CPUs means better ability to drive I/O to the volumes. Now this may not always be the case. For instance, with GKE, when I switched from two cpu nodes to four cpu nodes, there was no difference. However, by switching to eight cpu nodes, I was able to drive more I/O.
Obviously, the volumes themselves are important. Some things to consider are:
- Size of the volume: I’ve learnt that with a provider like GKE increasing the size of the volume has an affect on its performance.
- Type of volume: In most cases I used the readily available high performance ssd. However, there are other options for storage ranging from low cost/low performance cold storage all the way up to high speed nvme accessible flash arrays.
So…there you have it!
At the end of the day, picking the right node and volume really depends on your application’s needs. I hope this gives you some insight into the immense number of options present and that Kubestr can help you validate your choices in the future. As for picking the best cloud provider? Whoever gives you free credits, I guess.
To learn more about Kubestr, look for Kasten in the Sponsor Theater at KubeCon + CloudNativeCon Europe 2021 – Virtual.

##
Author:
Sirish Bathina
Member of Technical Staff
Kasten