
How LY Corporation Scaled Kubernetes from 5 to 1,300+ Clusters with Full Automation on Private Infrastructure
Executive Summary
LY Corporation built a fully automated private Kubernetes platform that grew from 5 production clusters in July 2017 to more than 1,300 clusters and 40,000+ nodes today. By using Kubernetes Custom Resource Definitions (CRDs) and custom controllers as an infrastructure control plane, the company cut provisioning from weeks to hours, eliminated manual recovery, and enabled 15 engineers to operate at this scale reliably and securely.
Company Overview
LY Corporation is a Tokyo-based technology company operating large-scale digital services. As engineering teams expanded and service demand increased, the company needed an infrastructure platform capable of scaling predictably while maintaining strong reliability and security standards.
Projects used



By the numbers
1,300+
Kubernetes clusters managed
40,000+
nodes operated on private infrastructure
15
engineers running the platform at hyperscale
Challenge: Scaling Infrastructure Without Linear Team Growth
Operating Kubernetes at large scale required more than deploying clusters. Manual provisioning and ad-hoc operations would not scale, and planned maintenance could not be disruptive.
As internal adoption increased, several challenges became evident:
- Provisioning environments often took more than a week
- Releases required cross-team coordination
- Nodes remained unpatched for extended periods, increasing security risk
- Recovering failed nodes could take several days
- Maintenance and upgrades risked service interruption at scale
Infrastructure operations were limiting business velocity, and simply expanding the operations team was not sustainable. LY needed a declarative, automated model that could scale without proportional growth in operational overhead—with zero-downtime operations as a first-class requirement.
Solution: Growing with Kubernetes from Day One
LY began evaluating Kubernetes in 2015 to run it at scale on private infrastructure. In 2016, the platform team prototyped a Kubernetes-native way to describe and reconcile cluster state using ThirdPartyResource (TPR).
In 2017, as Custom Resource Definitions (CRDs) became available, the team moved to a production-ready design and launched with 5 Kubernetes clusters in July 2017.
The team designed a custom resource called KubernetesCluster to represent the desired state of each cluster. Custom controllers continuously reconcile that state on the company’s OpenStack-based private cloud by:
- Provisioning virtual machines
- Configuring load balancers
- Bootstrapping control plane components
- Creating and scaling worker nodes
Provisioning a new cluster became as simple as applying a resource definition.
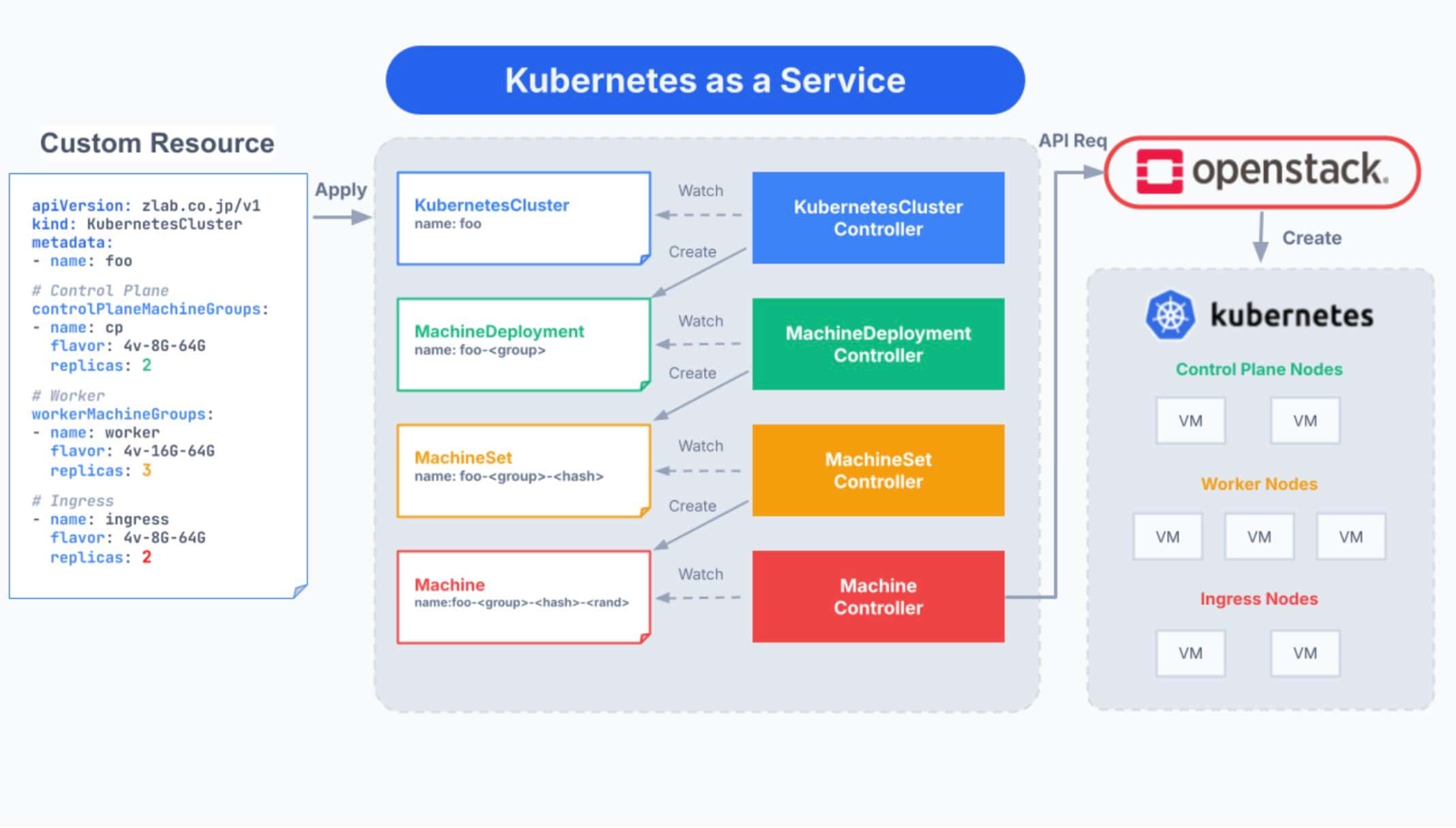
This Kubernetes-native model let the team automate cluster lifecycle and operations at scale, and it made zero-downtime cluster upgrades and maintenance possible. Upgrades use health-gated rolling node replacement—new nodes are added and must pass load-balancer health checks before old ones are drained and removed—while the control plane and etcd run as redundant replicas rotated one node at a time, so the Kubernetes API and running services stay available throughout.
What began as 5 clusters steadily expanded—first to dozens, then to hundreds—as Kubernetes became the default runtime for new services. Today, the platform manages more than 1,300 clusters and 40,000+ nodes.
Built-In Observability, Reliability, and Developer Experience
Rather than delivering vanilla Kubernetes, LY provides clusters with a curated set of production-ready add-ons deployed by default, improving developer experience and operational consistency.
Each cluster includes:
- Prometheus with node-exporter and kube-state-metrics, automatically collecting metrics
- Alertmanager with predefined alert rules
- Centralized logging pipelines
- Ingress controllers and cert-manager for automated TLS certificate issuance and rotation
These defaults ensure consistent observability, reliability, and security across all clusters. To prevent configuration drift and long-lived security exposure, nodes are automatically recreated every 3–4 months in alignment with Kubernetes lifecycle policies, eliminating manual recovery procedures.
Results: Operating at Hyperscale with a Small Platform Team
Nearly a decade after beginning Kubernetes evaluation, LY operates one of Japan’s largest private, on-premise Kubernetes environments.
Operational Impact
- 1,300+ Kubernetes clusters
- 40,000+ nodes under management
- 15 engineers operating at hyperscale
- Provisioning reduced from weeks to hours
- Zero manual node recovery
- 100% lifecycle-aligned node rotation every 3–4 months
Beyond operational efficiency, the platform changed how product teams build and ship. Moving the first product to run in production on the platform from VMs to Kubernetes required re-architecting it as a Twelve-Factor app—and that investment paid off across several dimensions:
- Scaling for spikes: campaigns drive traffic several to tens of times higher than normal (up to ~2,000 req/s). Scaling out used to take days of manual work; now the team only changes the desired number of nodes or Pods and the platform provisions the capacity automatically—with no hands-on effort.
- Release speed: with a release flow that runs entirely through GitHub and CI/CD, the time from merging a pull request to a completed release dropped from several hours to about 10 minutes.
- On-demand environments: standing up a purpose-built environment (e.g., performance testing) now takes only creating another KubernetesCluster resource.
- No more manual recovery: the platform health-checks the underlying VMs and automatically recreates and rejoins a node on failure, freeing the team from VM-failure on-call.
The first product team’s success made the platform the de-facto standard for services across the company. More broadly, developers adopted cloud native practices such as graceful shutdown with SIGTERM, accelerating deployment cycles and reducing production risk.
“Treating Kubernetes as our infrastructure control plane didn’t just let a small team run 40,000+ nodes reliably and securely—it turned infrastructure into a self-service platform where product teams scale and release on their own.”
Shota Yoshimura, Senior Platform Engineer, LY Corporation
Lessons Learned
- Treat Kubernetes as a programmable platform, not just an orchestrator
- Design for zero-downtime maintenance early—at scale it becomes a requirement, not an option
- Standardize observability and security to improve developer experience
- Eliminate manual recovery before scale makes it unsustainable
Future Plans and Community Engagement
LY continues to expand automation and strengthen its security posture while exploring deeper integration with emerging cloud native technologies. The company shares its operational experience at events such as KubeCon and participates in Cloud Native Community Japan, contributing back to the ecosystem and remaining committed to collaboration and knowledge sharing.