
Over the past two years, digital sovereignty has evolved from a policy discussion into a practical platform engineering concern. The EU Data Act has been fully applicable since January 11, 2025. NIS-2 and DORA already shape day-to-day platform decisions across regulated sectors, and the UK Data Use and Access Act 2025 is rolling out through 2026 with portability rules that bite.
As a result, platform teams are increasingly being asked to demonstrate not only where workloads run, but also how infrastructure is operated, secured, and governed. Questions about control planes, encryption keys, administrative access, auditability, and workload portability now appear alongside traditional data residency requirements.
For organizations building cloud native platforms, this raises an important architectural challenge. While regional infrastructure remains an important consideration, many sovereignty requirements ultimately depend on how control, access, and operational responsibility are distributed throughout the platform stack.
This article explores how Kubernetes-based platforms can address those requirements, and why control-plane design is becoming an increasingly important part of the sovereignty conversation.
What “sovereign” actually requires from a platform
When you decompose what regulators, auditors, and procurement teams keep asking for, four properties show up repeatedly:
- Jurisdictional containment. Every component that can read tenant data, including the control plane, runs under a legal jurisdiction the organization can name and defend.
- Operational autonomy. The team that runs the workload can rebuild, migrate, and audit it without depending on a single vendor’s hosted services.
- Cryptographic and access control. Keys, etcd contents, and admin credentials are not accessible to an entity outside the chosen jurisdiction.
- Portability. If the underlying hardware, provider, or country has to change, the workload moves without rewrite.
For sovereign cloud builders, these are not just regulatory boxes. Control plane location, metadata storage, administrative access, encryption, and key management ownership all have to be explicitly defined, alongside backup strategies and support access models that respect the jurisdictional boundary. None of this is satisfied by “we picked Frankfurt.” It is satisfied by infrastructure choices that go all the way down to the control plane.
Why a single Kubernetes cluster falls short
When building a sovereign platform, these requirements quickly become unavoidable, with Kubernetes serving as the foundational centerpiece that brings them together and provides the right substrate for sovereign platforms. CNCF backing, declarative APIs, and an open ecosystem (Kyverno for policy, Argo CD and Flux for GitOps, KubeVirt for VMs, Cilium for networking, SPIFFE/SPIRE for workload identity) are exactly the building blocks local regulated enterprises are converging on. The Swisscom sovereign Kubernetes reference architecture published on architecture.cncf.io is a clear signal of where the industry is heading.
The moment you start mapping real sovereignty requirements onto a single cluster, the gaps appear:
- One control plane serves all tenants. A jurisdictional incident affecting one tenant’s data plane risks affecting everyone sharing the API server, etcd, and controllers.
- Namespaces are not isolated. Even with strong RBAC, CRDs are shared, admission webhooks are shared, and a misconfigured controller leaks across the cluster.
- Cluster sprawl is the usual fallback. A full Kubernetes cluster per jurisdiction, per environment, per team. Operationally heavy, expensive, and slow to change.
In practice, operators often run shared platforms that support multiple regulated environments simultaneously, each with its own operational, compliance, and residency requirements.
For example, a provider may operate separate EU and UK tenant environments, each backed by its own regional infrastructure, storage, and audit boundaries like below:
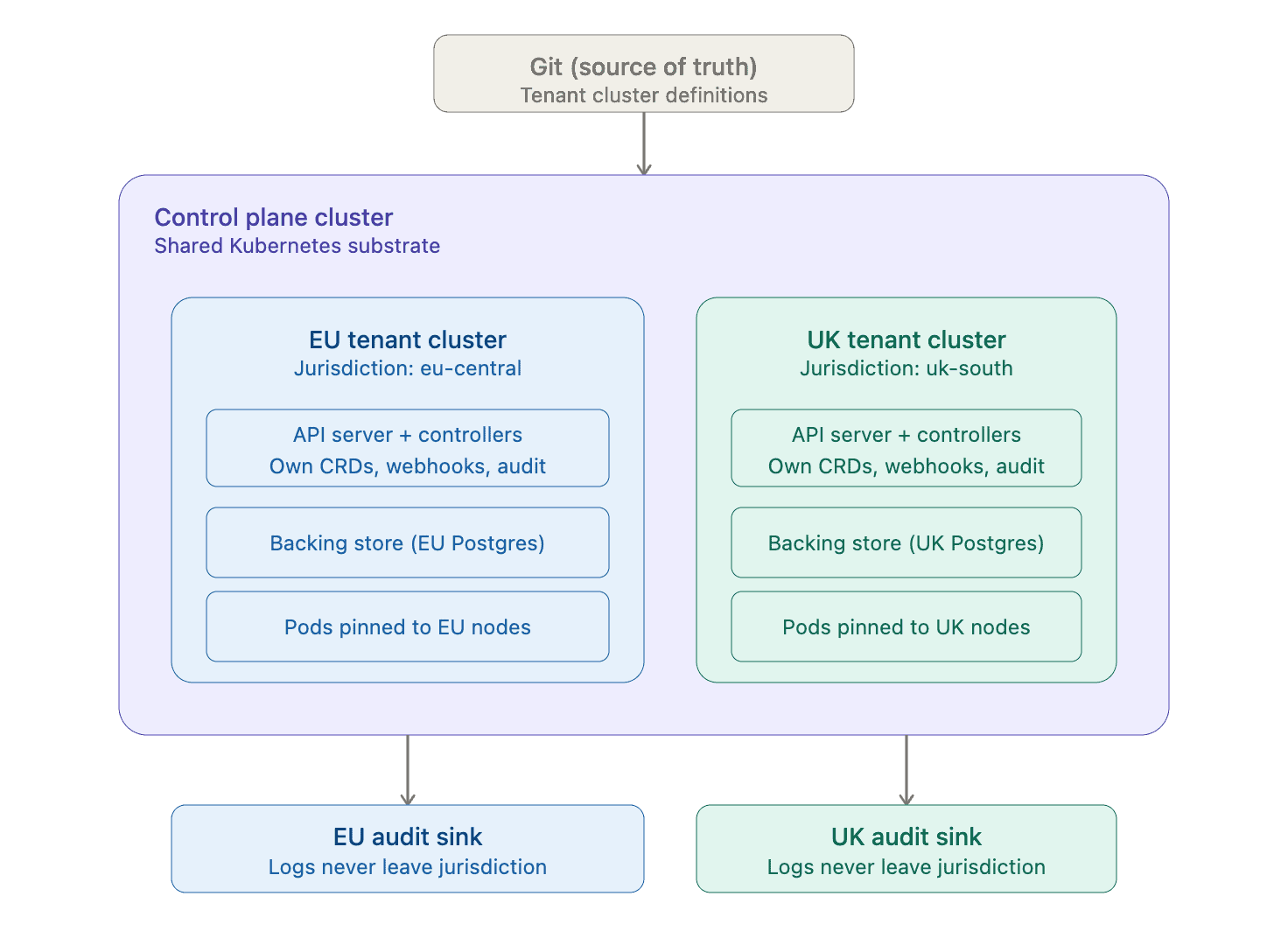
Pic: Sovereign Design, which isn’t Sovereign ( From Sovereign: What It Means )
The challenge with the above is that workload placement alone does not establish sovereignty. Even if tenant workloads run in separate regions, a shared Kubernetes control plane still centralizes administrative authority, policy enforcement, APIs, controllers, and key operational decisions. Wherever that control plane resides and whoever governs it ultimately defines the platform’s real sovereignty boundary.
Tenant clusters as a sovereignty primitive
The pattern worth learning here is the tenant cluster: a Kubernetes control plane carved out for a single isolation boundary, running on top of a shared underlying cluster. Each tenant cluster has its own API server, its own controller manager, its own scheduler, and its own data store. From the workload’s perspective, it is talking to a real, conformant Kubernetes cluster. From the platform’s perspective, the tenant cluster’s control plane runs as a set of pods on a shared Control Plane Cluster.
One popular way to implement this pattern is vCluster, an open source project that provisions tenant clusters as pods inside an existing Kubernetes cluster. We will use it as the running example for the rest of this post because it is easy to try locally, but the architectural ideas apply to anything that gives each isolation boundary its own control plane.
A few properties of tenant clusters matter directly for sovereignty.
Independent control planes. Each tenant cluster has its own API server and its own backing store (embedded etcd, external etcd, or a SQL database). One tenant’s CRDs, admission webhooks, and audit logs do not bleed into another’s. Separate control planes also mean separate Kubernetes versions, separate upgrade cycles, and variation in the platform stack per tenant, which becomes important the more tenants you have. A jurisdictional boundary at the cluster level becomes meaningful.
Pluggable backing store. The tenant cluster’s state can live on encrypted volumes on hardware you own, under the operator you choose. State residency, not just workload residency, becomes something you can design.
Tenant isolation, not multi-tenant namespaces. Workloads inside a tenant cluster cannot reach back into the underlying cluster’s API. For stronger runtime isolation at the container layer, a common approach is to pair the tenant cluster with a user-namespace based runtime such as vNode, or with gVisor or Kata Containers where a VM boundary is required. This matters for AI cloud operators in particular, where the threat model usually combines container-escape concerns with the need to keep tenants from observing each other’s workloads on shared hardware.
Workload portability. A tenant cluster exposes a conformant Kubernetes API. Workloads inside it are portable to any conformant Kubernetes, hosted or self-managed. Moving from a hyperscaler-backed underlying cluster to a sovereign provider, or to bare metal, does not require a workload rewrite.
The pattern that emerges is straightforward. Platform teams run a small number of underlying Kubernetes clusters, and tenants, jurisdictions, or regulated workloads each get their own tenant cluster. Sovereignty boundaries become first-class objects you can declare, audit, and move like the following with vCluster:
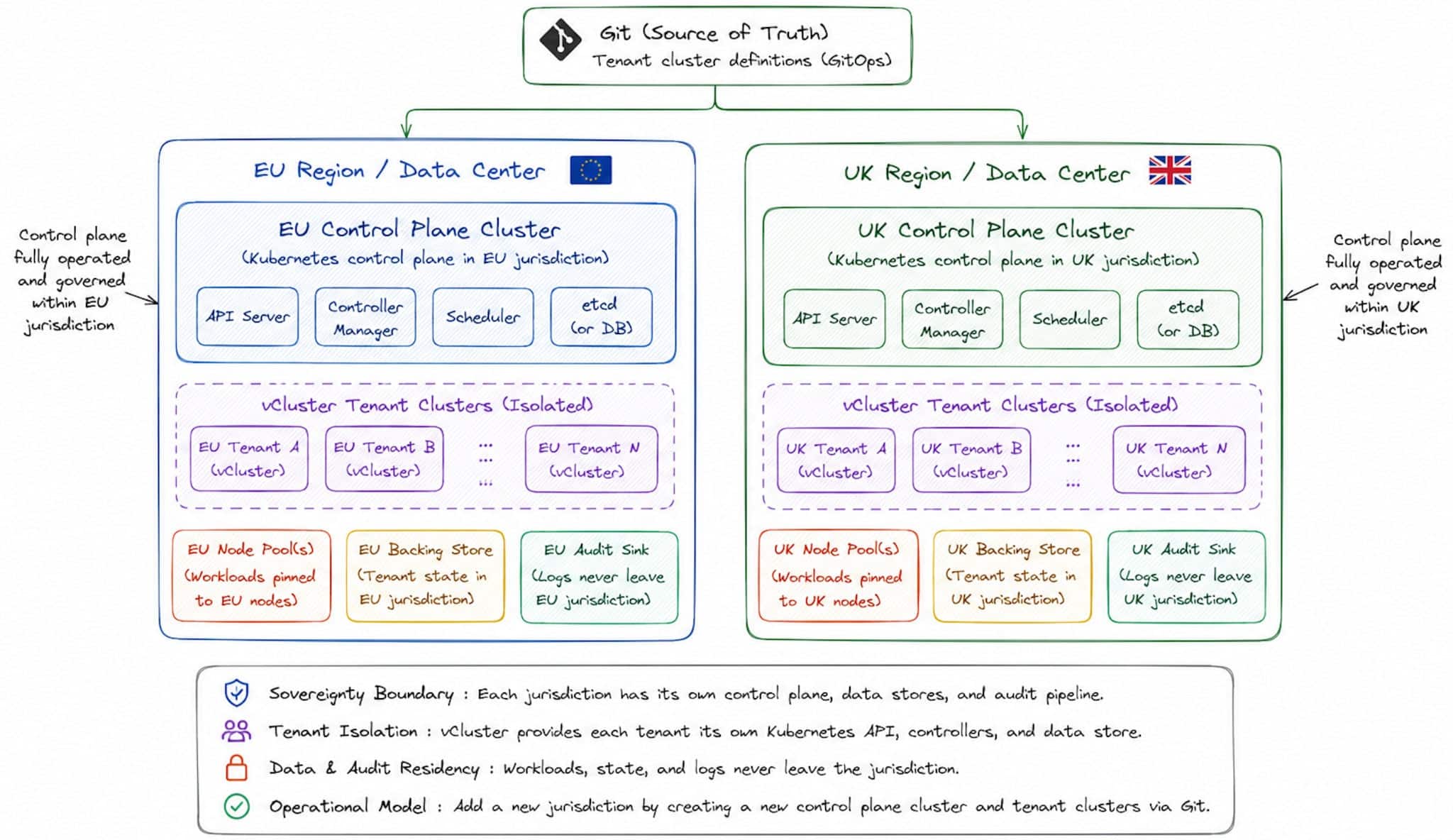
In architecture terms, this often means one underlying control plane cluster per sovereign jurisdiction or data center, with isolated tenant clusters provisioned for customers inside that boundary.
For example, an EU control plane cluster may serve EU-resident tenants exclusively, while a separate UK control plane cluster independently serves UK customers. This model allows each tenant to run its own Kubernetes control plane without requiring a full physical cluster per customer.
A practical pattern: jurisdiction as a cluster
Consider a SaaS company serving EU and UK customers. Under the EU Data Act, customer data, audit logs, and metadata for EU-resident tenants must remain under EU jurisdiction and be portable. UK customers fall under the Data Use and Access Act 2025, a parallel but not identical regime. The same product, two sovereignty boundaries.
A clean way to express this is one tenant cluster per jurisdiction, declared as Kubernetes resources and managed by GitOps. The shape is the same regardless of which tool you reach for: a custom resource describes the tenant cluster’s location, backing store, and policy posture, and a controller reconciles it.
The constraints that have to land somewhere in that resource are:
- A node selector or topology constraint that pins every pod in the tenant cluster to nodes labelled with the right jurisdiction, enforced as a hard constraint at the tenant control plane level rather than left to good behavior.
- A backing store for the tenant cluster’s own state (its etcd or SQL equivalent) that lives in the chosen jurisdiction. The control plane’s data, the API objects, the secrets, must not transit a non-jurisdictional managed service.
- An audit log sinks local to the jurisdiction, so the tenant cluster’s audit stream never crosses the boundary the regulator cares about.
- A policy bundle (Kyverno or OPA Gatekeeper) loaded into the tenant cluster that enforces residency, image provenance, and SBOM requirements from inside.
A UK tenant cluster looks structurally identical, with different labels, a different backing store, and a different audit target. Adding a new jurisdiction is a pull request, not a cluster build.
The whole definition lives in Git. The audit trail for “why is tenant X’s data in jurisdiction Y” is a commit history, not a screenshot of a console.
Reducing the blast radius of a sovereignty incident
The sovereignty conversation usually focuses on residency. The harder property is what happens when something goes wrong: a subpoena, a misconfigured controller, a leaked credential.
Tenant clusters narrow the blast radius in concrete ways.
A CLOUD Act-style request against the operator of the underlying cluster does not automatically yield a tenant cluster’s etcd contents if that backing store lives with a jurisdiction-local operator. The legal target and the technical target are decoupled by design.
A compromised admission webhook in the EU tenant cluster cannot reach into the UK tenant cluster, because they do not share a control plane. The webhook lives entirely inside one tenant cluster’s API server.
A platform-wide CRD upgrade is staged per tenant cluster. You can run Kubernetes 1.34 in one jurisdiction and 1.33 in another while a regulator finishes its review of a CVE. Version skew becomes a feature, not a problem.
These properties are not magic. They follow from giving each sovereignty boundary its own control plane, and they are very hard to retrofit onto a single shared cluster.
Bare metal, AI clouds, and where this is going
The same pattern composes downward. If the requirement is hardware sovereignty, not just operator sovereignty, the underlying cluster itself can run on bare-metal provisioned with Metal3 and Ironic (or higher-level tools like Tinkerbell) or layers like vMetal. Tenant clusters then inherit that hardware boundary by construction. No part of the stack runs on infrastructure outside the chosen jurisdiction. The Sovereign AI Cloud on Bare Metal GPUs guide walks through what this looks like end to end for a GPU-heavy build.
This matters for the AI cloud wave specifically. GPU-heavy workloads have been the loudest argument for hyperscaler dependency, and they are also the workloads most exposed under the EU AI Act’s Article 12 logging and governance requirements. A pattern of GPU-bearing underlying clusters on sovereign bare metal, with per-customer or per-jurisdiction tenant clusters that get GPU access through Dynamic Resource Allocation, gives AI platform teams a credible answer to both “where does training run?” and “who can subpoena the weights?”
This is not hypothetical. Polarise, a German sovereign AI cloud provider, is one example of an operator running this exact shape in production: shared GPU capacity underneath, a tenant cluster per customer on top, all under EU jurisdiction. The operator changes, the pattern is the same.
What this does not solve
It is worth being honest about the boundaries.
The tenant cluster pattern does not change the legal jurisdiction of the operator running the underlying cluster. If a US-headquartered company operates the Kubernetes underneath, CLOUD Act exposure for that operator remains. The pattern reduces and partitions exposure, it does not erase it. For workloads where the operator’s jurisdiction is itself the threat model, you still need a sovereign operator on sovereign hardware, with the tenant cluster pattern sitting on top.
This pattern also does not replace the rest of the CNCF sovereign stack. You still need a policy engine such as Kyverno or OPA Gatekeeper, an SBOM pipeline (the Cyber Resilience Act will not wait), an audit log pipeline, a workload identity layer like SPIFFE/SPIRE, and a GitOps controller. Tenant clusters are a primitive, not a platform. Frameworks like DORA and SecNumCloud 3.2 make this explicit: the tenant-cluster boundary is one input to operational resilience and sovereignty controls, not the whole answer.
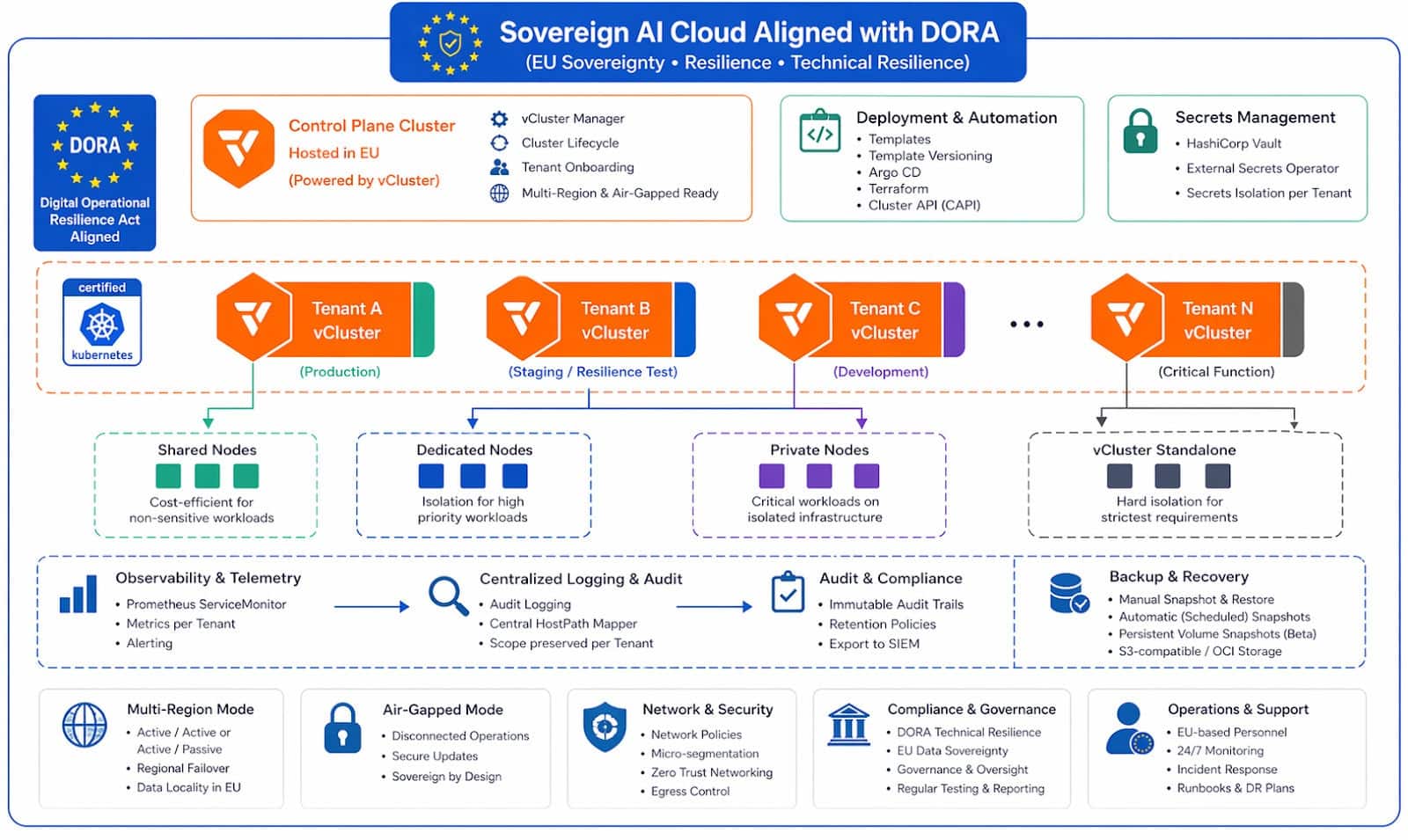
Ref: vCluster DORA Infographic
And per-tenant clusters have an operational cost. Each one is a real control plane to monitor, upgrade, and back up. The benefit only justifies the cost when the boundary you are drawing has real legal or risk weight behind it. A tenant cluster per customer is overkill for a free tier. A tenant cluster per jurisdiction with a few regulated customers in each is exactly the shape this pattern is for.
The shape of a sovereign platform in 2026
Pulling the threads together, the platforms passing 2026 audits tend to look roughly like this:
A small number of underlying Kubernetes clusters, on sovereign infrastructure where the threat model requires it. Tenant clusters per jurisdiction, per regulated workload, or per regulated customer, each with its own control plane, declared in Git, deployed via Argo CD or Flux. Policy enforced by Kyverno or Gatekeeper at the underlying cluster and per-tenant inside each tenant cluster. Audit logs streamed to jurisdiction-local sinks, never crossing the boundary the regulator cares about. Workloads written against plain Kubernetes APIs, portable across underlying clusters as procurement, geopolitics, and hardware availability shift.
Sovereignty in this model is not a procurement clause. It is an object in the cluster, with a name, a template, and a commit history. That is the form regulators are starting to expect, and the form platform teams can actually operate.