
I’ve been using AI coding agents as part of my daily engineering workflow and wanted to understand how well they actually perform on real-world bugs.
To test this, I ran a series of structured experiments using bug reports from the Kubernetes repository, evaluating whether agents could produce correct, complete fixes without guidance in a large, multi-million-line codebase. My initial assumption was simple. Success would largely depend on retrieval. Whether via retrieval-augmented generation (RAG) or filesystem search, a model that finds the right code should be able to generate the right fix.
That assumption didn’t fully hold. Even when agents surfaced the right files, they often failed to connect changes across them, misidentified the true scope of the issue, or produced fixes that were locally plausible but globally incorrect. The bottleneck wasn’t just finding code, it was reasoning over it in context.
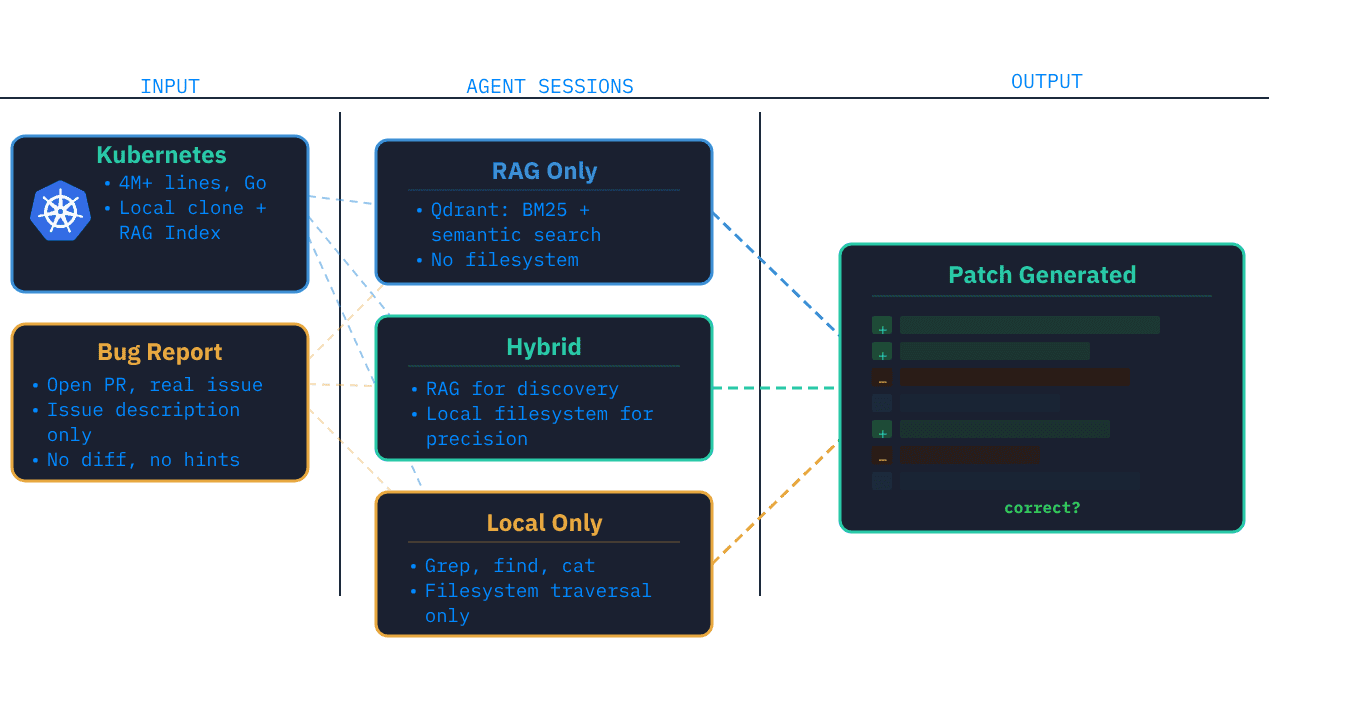
The setup
I took open pull requests from the kubernetes GitHub repo. Real bugs, actively being fixed by real contributors. I extracted just the issue description (not the PR description, not the diff, nothing that would leak the solution) and gave each issue to three different agent configurations:
- RAG Only: Hybrid retrieval over an indexed copy of the Kubernetes codebase via KAITO RAG Engine (Qdrant), combining BM25 for keyword matching with embedding based semantic search. KAITO also provides an auto-indexing controller which is perfect for indexing huge git repos with the capability of incremental indexing. Results are merged and ranked before being returned as context snippets. No local files or web access; the agent only sees retrieved chunks.
- Hybrid (RAG + Local): Same RAG index, but also has a full local clone of the kubernetes repository. The agent must start with RAG for discovery, then can read local files for precision.
- Local Only: Full clone, grep, find, cat. No RAG, no web. The agent explores the codebase through direct filesystem traversal.
Each agent ran in a completely isolated session. Same model (Claude Opus 4.6), same timeout (5 minutes), same output format. The only variable was how they could see code.
One critical constraint: the RAG and Hybrid agents were prompted to make RAG queries before producing any fix. Early experiments showed that without this mandate, hybrid agents would skip RAG entirely when the issue mentioned specific filenames, defeating the whole point of the comparison.
The test cases (Benchmark)
I used a set of real, in-flight bug fixes from the Kubernetes repository as a benchmark. Each test case is an open pull request where the agent is given only the issue description and asked to produce a patch. They span kubelet, scheduler, networking, storage, and apps. From a one-line guard clause to a 900-line multi-file refactor.
| PR | Bug | SIG | Size | Files |
| #134540 | SubPath volume mount race condition (EEXIST) | sig/storage | XS | 3 |
| #138211 | Image pull record poisoning (preloaded images) | sig/node | M | 5 |
| #138244 | NUMA topology stall on GB200 systems (O(2^n)) | sig/node | L | 2 |
| #136013 | OOM score panic on zero memory capacity | sig/node | S | 2 |
| #138269 | Scheduler SchedulingGates missing Pod/Update event | sig/scheduling | S | 2 |
| #138158 | ServiceCIDR deletion race in allocator | sig/network | M | 3 |
| #135970 | Missing initializer in StatefulSet slice builder | sig/apps | M | 4 |
| #138000 | Windows kube-proxy stale remote endpoint cleanup | sig/network | XL | 5 |
| #138191 | Container status sort by attempt (clock rollback) | sig/node | M | 5 |
Each generated diff was compared against the corresponding pull request diff and graded across five dimensions (0–4 each):
- Files: Did the diff touch the correct files?
- Location: Was the fix applied in the correct function/layer?
- Mechanism: Did the fix preserve correct system-level invariants and layering, not just patch symptoms?
- Tests: Were existing tests updated or meaningful new tests added?
- Completeness: Did the patch propagate changes across all required call sites and dependent paths?
This evaluation uses the PR diff as the reference implementation. That isn’t a perfect ground truth. PRs reflect iterative discussion and may not represent the only or final correct solution. Here, it serves as a proxy for “what human contributors converged on under review constraints.”
Timing
Every session had a 5-minute ceiling. Here’s how long each actually took:
| PR | RAG | Hybrid | Local |
| #134540 | 55s | 3m00s | 5m00s |
| #138211 | 2m30s | 3m30s | 2m30s |
| #138244 | 41s | 44s | 2m00s |
| #136013 | 31s | 55s | 41s |
| #138269 | 44s | 1m12s | 1m23s |
| #138158 | 1m41s | 1m48s | 52s |
| #135970 | 1m23s | 2m43s | 1m32s |
| #138000 | 1m28s | 4m03s | 4m57s |
| #138191 | 1m34s | 3m54s | 2m52s |
| Average | 1m16s | 2m25s | 2m24s |
RAG is consistently the fastest. It doesn’t read files, navigate directories, or wait for grep results. It asks the index, gets snippets, and generates. Average wall-clock: 1 minute 16 seconds. This suggests retrieval reduces exploration overhead but also reduces structural exploration depth.
Hybrid is the slowest on average at 2 minutes 25 seconds. The mandatory RAG-first phase adds overhead before local exploration even begins. On complex PRs like #138000 and #138191, Hybrid pushed past 3-4 minutes. The tool switching loop dominates latency more than actual file access.
Local matches Hybrid’s average but for different reasons. Hybrid spends time on RAG queries followed by targeted file reads. Local burns time on broad exploration through grepping, finding, and iterating directories. Exploration cost is highly sensitive to how well the issue text anchors the search.
Token economics
Token usage isn’t just about how much context the agent reads—it’s dominated by how many times it calls the model.
Claude’s API is stateless, so every call replays the full conversation. That makes call count the primary cost multiplier.
A few terms used below:
- Calls: Number of model invocations in a session
- New Tokens: Tokens newly introduced (retrieved code, file contents, prompts)
- Output: Tokens generated by the model
- Cached (replay): Tokens resent on each call due to conversation replay
- Total: Sum of all tokens processed across the session
Averages across all runs:
| Approach | Calls | New Tokens | Output | Cached (replay) | Total |
| RAG | 4 | 44k | 2k | 141k | 187k |
| Hybrid | 8 | 27k | 3k | 234k | 264k |
| Local | 6 | 23k | 4k | 162k | 189k |
Three patterns stand out:
- Hybrid is the most expensive, not because it reads more, but because it makes the most calls. The RAG to local loop creates repeated round-trips, and each one replays a growing context window.
- RAG and Local end up with similar total cost, but for opposite reasons. RAG pulls in more new context via retrieval, while Local makes more exploratory calls. The totals converge.
- Fewer calls beats fewer tokens. Sessions that stayed under ~5 calls were consistently cheaper, regardless of approach.
Across all runs, call count was the biggest driver of both cost and latency.
What I actually learned
Agents fix locally, not systemically
Agents are good at fixing the problem directly in front of them, but struggle to reason about the broader system.
PR #134540 is a good example. The correct fix required preserving an error (%w) so the caller could handle it, and then updating the caller to tolerate that specific case. Every agent instead swallowed the error at the source. Functionally similar, but architecturally wrong.
This shows up consistently: agents fix symptoms in isolation, but miss the contracts between components.
Scope discovery is the real bottleneck
The biggest failure mode wasn’t incorrect fixes, it was incomplete ones.
Agents routinely fixed the “main” bug but missed adjacent changes:
- On #138191, RAG-only fixed one sort implementation but missed a second.
- On #138000, all approaches fixed the core bug but missed required changes in proxier.go and related integration logic.
- On #134540, Local and Hybrid saw a partial fix already in the codebase and stopped early, missing the second required change.
The common pattern that emerged was agents don’t ask “what else needs to change?” They stop once the immediate issue appears resolved. This is most visible in multi-file changes, where agents fix the local bug but fail to propagate required updates across integration points.
Retrieval changes discovery, not reasoning
RAG meaningfully affects how agents find code, but not how they reason about it.
Forcing RAG usage improved results in some cases. On #138211, mandatory retrieval pushed the agent to discover the policy evaluation layer before implementing a fix, leading to a better architectural choice.
But the limitation remains, once the relevant code is found, the agent still reasons locally. Retrieval helps with navigation, not with understanding system-wide implications.
Agents prefer adding over reusing
When given a choice, agents tend to introduce new abstractions rather than reuse existing ones.
On #138191, the correct fix used the existing `RestartCount` field. All agents instead introduced a new `Attempt` field. Functionally correct, but architecturally heavier.
This pattern showed up repeatedly. Agents don’t reliably recognize when the system already contains the concept they need. They solve the problem in isolation rather than integrating with existing design. This also shows up in tests. Agents tend to add new tests rather than update existing ones, even when behavior changes require modifying assertions.
Issue quality dominates everything
Well-specified issues flatten the differences between approaches.
On PRs like #136013 and #138269, the issue descriptions named the exact file, function, and expected behavior. All approaches converged to high scores, with Local slightly ahead simply due to speed and direct access.
When the issue effectively acts as a spec, retrieval method matters far less. When the issue is vague, performance diverges significantly.
The bottom line
These results come from large codebases (millions of lines), where correctness depends on system-wide understanding rather than local edits.
They are not about raw model capability, but about how agent workflows behave under scale.
Indexing helps, but doesn’t solve scope
Semantic search (RAG) improves discovery in large repositories, but does not ensure coverage of all affected components.
Workflow matters more than model choice
Hybrid setups perform best only when retrieval is enforced. Otherwise, agents default to local reasoning and miss broader context.
Scope discovery is the core bottleneck
Agents reliably fix visible issues, but fail to consistently identify all dependent changes across the system.
This is the dominant failure mode in multi-file and integration-heavy changes.
Issue quality is the strongest lever
Well defined bug reports reduce performance variance more than tooling or retrieval strategy.
Skills can help, but they don’t remove the system problem
This experiment did not use any explicit coding “skills” or curated agent playbooks. Only prompts and tool access.
In principle, structured skills (such as repo exploration strategies or architectural summarization) could improve performance by guiding agents toward better system-level reasoning.
However, in large, evolving codebases, these skills would need to be continuously maintained and updated to remain aligned with the actual repository structure. That makes them less like a one-time improvement and more like an additional system to operate and maintain.
As a result, while skills may improve outcomes, they do not remove the core bottleneck observed in this study: scope discovery and system-level reasoning under scale.
The benchmark used Claude Opus via OpenClaw with KAITO RAG Engine indexing the Kubernetes/Kubernetes repository at HEAD. All sessions ran in isolated subagents with no shared state, April 2026. Ground truth was the actual PR difference from each open pull request.