An application, composed of one or more containers as dictated by system architecture, that operates either independently or as part of a distributed collaboration—interacting with at least one other entity (container) or achieving quorum-based consensus. It leverages AI or Machine Learning capabilities to reason and execute actions within event-driven systems, where behavior is triggered or modulated by signals. Its defining attributes: encompass differing levels of autonomy in executing system or user tasks, coupled with the ability to plan, orchestrate, and govern the continuation or completion of its own execution. In cloud-native environments, these components are commonly packaged and deployed as containerized microservices.
Overview
Within the cloud native ecosystem, there has been an explosion in agentic AI. Rapid prototyping and adoption suggest potential for businesses to accelerate time to value for products and services for organizations across all sectors and technology verticals. While this interest is very promising for this burgeoning field, challenges exist in terms of standardization and interoperability, which are currently lacking.
Agentic systems provide the means to perform multi-hop reasoning, and subsequent action calling based upon signals to augment and provide dynamism to conventional programming sequences.
This paper explores four key areas where standardization is needed to ensure interoperability, security, and observability from the outset. The focus of this document is not on how specific agentic protocols are implemented, which programming languages are used, or their execution efficiency. Instead, it provides an agnostic view of best practices that enable deployments in this space to scale securely while remaining observable and explainable through a common foundational framework.
The recommendations described are exclusively focused on cloud native environments built on Kubernetes. This extends to scenarios where Kubernetes may be deployed in public, private, hybrid or edge compute type scenarios, as there are nuances in the domain of security associated with these environments and systems.
This document provides a foundational checklist for agentic standards, but is not intended to be exhaustive and will continue to evolve as practices and the tools improve.
General
This section outlines foundational container and observability best practices for cloud native workloads, including agentic AI systems. Evolving challenges include the rapid advancement of agent environments and capabilities, which require governance frameworks to adapt continuously. Future research and standardization efforts should focus on nuanced reward functions, layered reasoning architectures with built-in controls, and robust safety and alignment techniques to manage increasingly capable and autonomous systems.
General best practices for containers:
The containerization principles outlined below include emerging definitions of agentic services (e.g., autonomous, signal-driven, reasoning-capable container systems deployed within microservice-oriented architectures). The recommendations are not specific to agentic use cases and apply to any containerized or serverless environment.
General best practices include: Security, which covers minimizing attack surface and safeguarding container integrity; Observability, which focuses on collecting actionable metrics, logs, and traces to understand system behavior; and Availability and Fault Tolerance, which outlines strategies for maintaining service continuity and resilience under failure conditions.
Security
- Enforce the principle of least privilege for containers. Only grant the minimal permissions required for the container to operate, minimizing the attack surface. This requires configuring user controls, network policies, security contexts of containers, and access control.
- Information hiding – Avoid exposing unnecessary dependencies outside the container.
- Package only what is needed, use multi-stage builds to minimize image size, and avoid leaking build tools, credentials, or secrets.
- Use secure container images from official, trusted repositories, scanning images for vulnerabilities regularly. Sign and verify images to ensure the integrity and provenance of container images. Add OCI-compliant annotations to container images to document metadata such as source, version, authorship, scan status, and signature information.
- Follow secret management best practices. Never bake secrets into container images. Use Kubernetes Secrets or integrate with secret managers.
- Run containers as non-root users. Define a non-root user in the Dockerfile and configure the runtime to use it. This limits the blast radius in case of a security breach.
- Continuously monitor and update base images of the container to include the latest security patches and avoid known vulnerabilities. Use distroless images where possible.
- Log and monitor container activity. Monitor runtime behavior, resource usage, filesystem access, network activity, and system calls to detect anomalies or security incidents early.
Observability
- Use a standard observability stack Metrics, Events, Logs, Traces (MELT). Consolidating metrics, logs, and traces to ensure viable explainability and achievable debugability of the system.
- Incorporate network observability by collecting flow logs for security, performance monitoring, and troubleshooting.
- Monitor resource-specific metrics and relevant network metrics for system robustness on the data path between key components
- Disk Usage: Monitor disk usage on nodes and persistent volumes to prevent outages caused by storage exhaustion.
- CPU / GPU: Monitor usage at the node and container level to detect bottlenecks, and prepare for potential In-Place pods resizing overhead
- Monitor control plane and node health in the cluster.
- Instrument workloads with relevant metrics and expose application-level and business-critical metrics in addition to system-level metrics.
- Set up alerting based on SLOs/SLA thresholds.
- Implement cost observability to support GPU and LLM benchmarking.
- Secure observability pipelines to avoid tampering with audit trails from agents.
- Set up data retention and aggregation policies.
Availability and fault tolerance (general)
- Implement resource limits and requests to prevent noisy neighbor issues and ensure container stability. Set reasonable CPU/GPU and memory boundaries in your Kubernetes pod specs.
- Utilize PodDisruptionBudgets to enforce minimum pod availability during voluntary disruptions like upgrades or node drains.
- Use Pod Anti‑Affinity or Topology Spread Constraints to distribute pod replicas across nodes or zones, minimizing the impact of node or zone-level failures when possible.
- Use Horizontal Pod Autoscaler (HPA) to scale workloads dynamically using CPU, Memory, or custom metrics such as request volume.
NOTE: The above items are general in nature, and while applicable to smart load-balancing to inference models, does not pertain to more comprehensive MCP / Agent to Agent or LLM tooling.
Availability and fault tolerance (inference specific)
- Inference extensions provided via the Gateway API ensure that path-based rules are to be applied with a focus on inference served AI Models to augment robustness and availability. This capability supports more dynamic deployment scenarios used by agents.
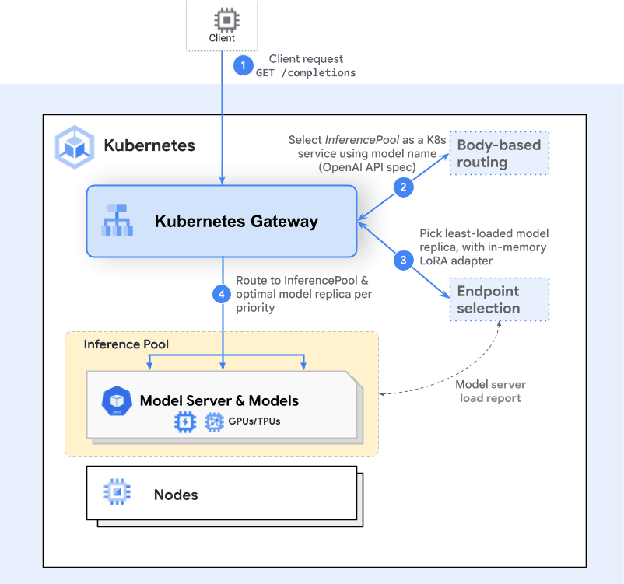
Sample request flow with Kubernetes Gateway API Inference Extensions InferencePool endpoints running a model server framework
Source: https://gateway-api-inference-extension.sigs.k8s.io/
PLEASE NOTE: The General Section is not an exhaustive list of every best practice, rather it is included as a primer on a number of adjacent foundation topics relevant to the main body of this document that is focused towards agents. Links to more exhaustive overviews of such topics and practices can be found in the footnote section. Additional current literature, white papers, and documentation from the CNCF and Linux Foundation should also be considered to ensure the best decisions are made around this constantly moving technology space.
Footnotes:
- Follow the Kubernetes security checklist for ensuring best practices in your cluster: https://kubernetes.io/docs/concepts/security/security-checklist/
- The CNCF white paper on cloud native security defines security controls and practices that are appropriate to the develop, distribute, deploy, and runtime phases.
- Learn more about Kubernetes pod security standards: https://kubernetes.io/docs/concepts/security/pod-security-standards/
- Learn more about Linux kernel security constraints in the context of hardening pods and containers: https://kubernetes.io/docs/concepts/security/linux-kernel-security-constraints/
- You can learn more about tools for monitoring resources here: https://kubernetes.io/docs/tasks/debug/debug-cluster/resource-usage-monitoring/
Control and communication
Microservice architectures have long followed the principles and practices of information hiding, minimal endpoint exposure for only the requisite and needed services, and clear contract-based communications. These same principles should be followed in the context of agentic architectures. As multi-agent systems grow, the intricacy of ensuring effective coordination and communication rises significantly. While Kubernetes provides the platform, the complexities of inter-agent communication protocols (like MCP, A2A) and managing “tool sprawl issues”, require specific attention within the agent application layer itself. Furthermore, pre-empting the unpredictable nature of agent behaviour, requires increased operational rigor, and focus around secure communications.
Communication related attributes
The list below provides a non-exhaustive overview of communication-related attributes that should be considered when creating Agent-to-X deployments (where “X” may refer to tools, services, models, or other agents).
It should be noted, that for this section, the change revision is very high; this is largely due to numerous protocol specifications that are yet to be formally adopted and standardized in the field.
Orchestration flow, safety, and fault tolerance
- Design and implement orchestration methodologies using GitOps principles that optimize agent workflows, task assignments, and communication patterns. This should consider various architectural patterns (e.g., centralized, decentralized, star, ring) and their implications including safety and fault-tolerance aspects for the security and control of the solution.
Tools and services
- A common approach is pursued to access tools (MCP, A2A, ACP, etc…). Unnecessary entropy can lead to complexity in the ability to operate and monitor the solution effectively. While the correct tool should be considered for the task required, careful consideration should be given to whether variance in the system/solution is necessary.
- Connectivity to access control mechanisms needs to be applied in a manner where contingency aspects are taken into consideration. What should the given behaviour be of an AI Agent or Tool if it cannot reach a central Access Control system? Which systems should remain accessible? Which telemetry data should be triggered in the case of a loss of communications?
Agent connectivity to AI Models
- Agents need to communicate with AI models, either within an on-premise environment or within a private or public cloud. In multi-agent architectures that may involve varied models, which processes can proceed with the loss of a given model, and which processes need to stop. A Kubernetes custom watcher pod/controller may be considered in select scenarios to monitor critical resources (such as a model provider), allowing for alternative deployments to be applied in the case of communication disruptions. Observability of such faults, allowing for intervention, can also be achieved through the use of a gateway and/or proxy coupled with robust observability mechanisms.
Agents to other Agents
- Protocols like Google’s A2A (described below) aim to enable secure, dynamic, and structured peer-to-peer agent interaction, even across heterogeneous agent ecosystems.
Filtering and input/output schema validation
- Given the unpredictable nature of generative AI, defining schemas using JSON Schema, Protobuf, or OpenAPI to validate payloads during tool calls and external service invocations can increase system predictability and avoid cascading failures. Data constraints can be enforced to avoid malformed input, malicious content injection, or drift caused by inconsistent formats.
Protocols today (MCP, A2A, etc…)
- While there are a broad array of complementary technologies in the industry today, numerous protocols have gained a level of interest for preliminary evaluation in the field in the domain of agentic AI. Each of these protocols aims at addressing a specific problem space within the domain, ranging from tool exposure to inter-framework communications or agent discovery, trust and identification services.
- Model Context Protocol from Anthropic: Provides a key focus on “tool exposure” providing a means to define an “MCP Server” which is responsible for providing tool access to an “MCP Client”, in many scenarios the use of MCP can support both single and multi-agent frameworks in achieving standardized access to specific tooling, without the need to define and program the logic from scratch. Considerations should be taken in terms of only applying narrowly scoped MCP server tooling access for the given tools required, for both security and optimal system performance reasons. MCP utilizes JSON-RPC 2.0 over HTTPS and streamable HTTP transport. MCP has been donated to the Agentic AI Foundation (AAIF).
- A2A from Google: Offers a means for agents to communicate with one another directly, analogous to peer-to-peer communications. Providing an optimal means for agents which may even exist in disparate domains or that utilize disparate frameworks, with the means to establish communications with one another. A2A utilizes JSON-RPC 2.0 over HTTPS and streamable HTTP transport.
- AP2 from Google: Introduces a framework for secure payment by AI Agents through the use of cryptographic signed certificates. The protocol introduces the concept of real-time and delegated operation models. Uniquely, the protocol adopts x402 extensions supporting its usage in decentralized environments, including usage of Verifiable Credentials (VCs) and Decentralized Identifiers (DIDs).
Authentication and Authorization Focused Protocols
To address the problem space of workload and task based security a number of further mechanisms are needed to ensure that needed trust boundaries can be achieved. In order to achieve these outcomes, there are several options which exist in the cloud native space today, focused towards both workload security and task based authorization.
- SPIFFE/SPIRE: Focused towards workload security, this technology stack provides a means to secure cryptographic identity of workloads through the use of SVIDs in the form of JWT or X.509 documents. The solution allows for workload attestation and federation. (This technology is covered more comprehensively in the security section).
- Identity: The Agntcy identity framework (recently donated to the Linux Foundation) still in relatively nascent stages, takes the approach of allowing varied identity providers to be used in a BYOI (Bring Your Own Identity) construct. What is notably different with this approach for identity is that it also supports the Web3 DID based standard, which supports distributed identity concepts. A novel approach towards the deployment of Identity within Agent-based architectures.
Message and communication design considerations with REST, GRPC & Kafka
- To accommodate the data, the usage of known event-driven bus architectures such as Kafka and Flink should be considered. Event buses are especially useful when asynchronous communication is desired (e.g. long-running tasks) or when building an event-driven architecture (e.g. emitting telemetry, decision logs, or coordination signals). Kafka guarantees high reliability and delivery guarantees, useful for data de-duplication in data management pipelines (at-least-once delivery), and Flink may be considered for stream processing use-cases to manipulate data in transit. While these are very common system architecture patterns, the handling of this data, and its respective security, needs careful consideration when being utilized by agent based systems.
- gRPC, the rate of data at input for streaming data should be considered carefully to assess whether an ELT or ETL approach needs to be taken. Other considerations around the impact that the amount of streaming data may have on agent token limits when interfacing with models that are worthy of evaluation.
- REST: Simple, interoperable protocol where communication is discrete (request/response). Large payloads may affect latency, and are less performant compared with gRPC. REST also lacks native streaming support, which may be required for specific agent based flows and use cases, particularly in long lived actions.
Discovery/agent registries
- DNS based – Kubernetes-native DNS or service mesh registries can be used for agent and tool discovery, based upon the configured agent system design.
- Service meshes have capabilities to maintain a dynamic directory of running services, agents, or tools, along with their metadata and network endpoints.
- Purpose-built agent and tool registries are emerging and not only track network endpoints but also maintain metadata such as agent/tool registry capabilities, health, and status. This allows agentic workflows to select the most appropriate resources at runtime and adapt to changing environments.
- Further options, such as static registration, multicast based registration, and others are also available and worth consideration in air gap scenarios without access to centralized registries.
Footnotes:
- Agent Protocols Paper: https://arxiv.org/pdf/2504.16736
- OWASP Secure Agent Registry: https://genai.owasp.org/secure-agent-registry/
- Agentic Directory Agntcy: https://agent-directory.outshift.com/explore
- Linux Foundation Agntcy project: https://docs.agntcy.org/
- Google A2A Project: https://github.com/a2aproject/A2A
- Google AP2 Project: https://github.com/google-agentic-commerce/AP2
- MCP Project: https://modelcontextprotocol.io/docs/getting-started/intro
- Agent Skills: https://agentskills.io/home
Observability
Observability in the context of agentic microservices manifests in a number of ways. These consist of general container health (as described in the earlier general section) to ensure that CPU, Memory, and GPU resources are ample to perform the requisite functions of the service.
Observability metrics for agentic services extends beyond basic container health metrics architectures in a number of ways. Metrics can be used as a means to identify the precision of requests handled, the time taken to complete a particular task, dwell time in a multi-agent architecture per function, and even as a comparative value to assess if a given tool exposure is more efficient from Service A or Service B.
Metrics
- Configuration of metrics to track tokens used for inference activities with a given model (or xLM if applicable), including relevant metadata (role, model, etc…), and optionally more granular metrics such as TTFT/TPOT/ITL, input/output/reasoning tokens, or other evolving performance measures, both inside and outside of a cluster.
- Interactions with external tools/LLM should be applied as a metric which can be monitored in time series for threshold changes, variance, as to allow for delta comparison, trend analysis, and diagnostics.
- Duration of execution is an important parameter to track, to allow for comparisons between models, and to support in identifying load-related challenges.
- Cost of inference is a viable and trackable parameter which is offered by many online models, similar cost values can be derived based on private metrics such as cost of power and maintenance for private cloud environments.
- Precision, percentage-based confidence level on inference responses when interfacing with given models to allow for improvement comparisons and continuous evaluation.
- Rate Limits hits when executing inference activities, including relevant metadata such as model, account, and tokens used that resulted in rate-limit hits, this data is useful to adapt agent architectures to implement a pause, or capacity characteristics to be updated or model selection changed, this is particularly relevant in on-prem deployments, where concurrency may be a factor.
- Record use-case-specific metrics, such as prompts for validating correctness, hallucinations, or success rate for self-improving agents.
The use of observability traces allows for an end-to-end waterfall view of communications which take place between microservices including agents. In the context of agentic microservice deployments, deploying the right levels of traceability, can support a clear and concise view of the communication flows between agents, databases, and other ancillary components which build up the end-to-end application flow. Traceability is becoming an important consideration for agentic architectures as a means to support requisite regional explainability mandates (EU AI Data Act, etc…).
Traces and spans
- Custom instrumentation via OpenTelemetry provider into corresponding agent code (Python, Rust, Go, etc…) to allow for clear view of end-to-end communications including specific process hooks relevant to the systems execution flow.
- Auto instrumentation of Open Telemetry within K8s to monitor system diagnostics is important to consider, particularly in on-premise deployments where GPU capacity may have an impact on serving requisite models to multiple agents or consumers.
- Creation of agentic code allowing for “hooks” to ensure that functional execution can be monitored in the context of per-process executions (SPANs) within a broader application trace.
- Configuration of metadata (e.g., user ID, session ID, context-related activity, container-ID) in the form of an OpenTelemetry signal, such as baggage, to ensure that unique identifiers can be tracked that are common to each unique agentic workflow or action to support debuggability and explainability.
Logs
- Authoring of viable and usable logs which are authored with a “natural language” in mind to allow for future re-usability by co-op AI model based systems for debugging.
- Deployment of a common system time between agent architectures to ensure operational data and its corresponding flow can be easily monitored and tracked.
- Maintain a common and structured data format throughout the deployment to ensure that data cleaning and transformation tasks are simplified.
- Considerations should be taken around canonical logging from the beginning, as to allow for valid log-based metrics to be saved to a central point for reuse in canonical log generation, canonical logging can support better post-mortem diagnostics and auditability.
Continuous monitoring and adaptive control
- Leverage the robust observability framework described utilizing industry standard methods such as OTEL with clearly defined semantic conventions for continuous monitoring of agent trajectories and performance.
- Implement mechanisms for periodic reassessment to detect performance drift or emerging issues over time through time-series monitoring of key metrics.
- Integrate feedback loops, allowing agents to learn from past experiences and continuously adapt their strategies in dynamic environments, including self-correction mechanisms such as reinforcement learning to enhance reliability.
Footnotes:
- https://opentelemetry.io/blog/2024/llm-observability/
- https://opentelemetry.io/docs/specs/semconv/gen-ai/gen-ai-agent-spans/
- https://www.cncf.io/blog/2025/01/27/what-is-observability-2-0/
- https://opentelemetry.io/docs/concepts/signals/baggage/
Governance
This section defines the critical governance mechanisms necessary to ensure the responsible, reliable, and secure operation of LLM-based multi-agent systems within a Kubernetes ecosystem. Effective governance spans the entire lifecycle of an agent, from initial development and pre-deployment validation to continuous monitoring and adaptation in production.
Agentic governance foundations
- Governance is considered a mandatory foundational layer and factor that must be applied in Cloud Native agentic deployments.
- Counter to existing software governance practices, adherence to a more dynamic and flexible governance approach is essential to deal with emergent behaviours in multi-agent systems (LLM-MA’s).
- Provision for regulatory adherence, to avoid future system design changes, design the system correctly from the beginning, including transparency and accountability, to avoid costly refactoring and redesigns later.
Critical steps and methodologies required before an agent is deployed to ensure its fitness for purpose, including adherence to defined policies and robustness against known failure modes, should be considered for production deployments.
Evaluation factors should be considered beyond the siloed metrics of task completion accuracy or job completion time, to consider multifaceted attributes as part of a comprehensive assessment.
Evaluation approach
- Targeted use case consideration
- Adjust evaluation priorities based on application and use case to allow for differential assessment.
- Support tailoring evaluation approaches to the actual system the agent is embedded in.
- Assessment criterion
- Clear definition of success criterion and success rate of execution in conjunction with quality evaluation of outputs.
- Total cost of usage
- Computational Cost (Processing time, Memory Usage)
- Tangible Financial Costs (API Calls, Tokens Used)
- Environmental Impact (CO2, Carbon Credits)
- Human Cost (Oversight / Setup Time)
- Mandatory storage of data (backups, audit trails)
- Reliability and robustness
- Evaluation of agent behavior in diverse and atypical testing scenarios.
- Ability to withstand adversarial, bias-based, and other attack vectors.
- Safety and alignment
- Adherence to specified constraints, avoidance of harmful outputs, and alignment with human values and intentions.
- Interaction quality
- Naturalness, coherence, and user-centeredness of agent communication and behavior during human interaction.
- Standard and uniform evaluation protocols
- Clear guidelines must exist for test administration, scoring, and environment configuration to ensure results are comparable and reproducible. This is essential for meaningful progress assessment.
The instrumentation of testing structures which allow for the correct levels of evaluation is a key requirement in both benchmarking of what a viable target evaluation state should be, and where improvements or reductions in performance are evident. Setting clear structures and evaluation criteria, through the use of a flexible framework, ensures that the system is tailored to meet the needs of the target application and use case being evaluated.
Synthetic data generation for test execution
- Diverse and policy-driven synthetic datasets and/or fault scenarios should be generated for testing.
- Tests executed should align to real-world scenarios with a precedence towards issues which are more commonplace than corner case scenarios.
- Human-in-the-loop (HITL) interaction should be possible to ground the testing setup for relevance and calibration.
- Ability to generate synthetic scenarios at scale that include entropy in the testing datasets is important to avoid learned behaviour from invalidating test cycles.
Granular and trajectory based assessment
- Stepwise evaluation
- Implement detailed, step-by-step assessments of individual agent actions and LLM calls, facilitating root cause analysis of errors and diagnosing specific failures in intermediate decision processes like tool selection and reasoning quality.
- Trajectory based assessment
- Analyze the entire sequence of steps taken by an agent in relation to an expected optimal path. This method evaluates the agent’s decision-making process, especially for complex multi-turn and multi-step tasks.
Veracity of testing (precision of execution)
- Real-world applicability measures bridge the gap between benchmark performance and practical utility through integration testing (assessing agents within broader systems and workflows) and user acceptance metrics (measuring actual user satisfaction and trust).
- Live benchmarks and continuous adaptation employ adaptive, continuously updated benchmarks that can reflect real-world complexities and dynamic conditions. Some frameworks exemplify this trend, evolving to incorporate live datasets and multi-turn evaluation logic to remain relevant.
This sub-section addresses the ongoing post-deployment governance requirements for agents once they are deployed, ensuring continuous safety, performance, and compliance.
Data privacy and minimization
- Enforce strict data minimization practices, transparent data governance policies, and strong security measures to protect sensitive user data that agents may access or process. This is in addition to traditional data protection (layered security). See the security section for more details.
Explainability and auditability of agent decisions
- Model provenance and telemetry of the models across the LLMOps lifecycle. Implement frameworks like the Model Openness Framework (MOF) to ensure transparent documentation throughout the LLM lifecycle, from data preparation and model training to evaluation, packaging, and deployment. This assurance process should include the generation of detailed model cards and data cards, and cryptographically signing model artifacts for integrity and provenance using tools like Sigstore.
- Automated auditing (LLM as a Judge), explore and implement automated evaluation approaches using “Agent-as-a-Judge”. This approach can provide continuous, fine-grained, and cost-effective assessment of agent performance and adherence to safety policies in production, reducing the reliance on manual human annotation for ongoing validation.
Beyond traditional Kubernetes self-healing, design agentic applications to inherently handle failures without cascading impact. This involves implementing agent-level retry logic, circuit breakers, and graceful degradation strategies specific to agent communication and tool interactions, ensuring the overall system remains resilient even when individual agents or external dependencies experience transient failures.
- Integrated lifecycle governance
- Reiterate that effective governance for Kubernetes based agentic applications is not a one-time exercise but an ongoing, integrated process across the entire LLMOps lifecycle. It requires a symbiotic relationship between technical implementation, policy frameworks, and continuous oversight.
Footnotes:
Security
This section defines the security considerations involved in building agentic systems. Three primary goals should guide the design: authentication, authorization, and trust. Agents and their components must be able to securely authenticate and should only be granted the minimum permissions necessary to function. Trust boundaries must be clearly established to prevent privilege escalation, data leakage, or unauthorized behavior within the system.
Keeping these goals in mind user access, agent identity, tenancy, and data access must be deliberately designed and enforced. Each agent should have a unique, verifiable identity to support traceability, accountability, and secure communication across system boundaries. Strong tenancy isolation is critical, especially in multi-tenant environments, to prevent cross-agent interference and ensure that agents operate within their own scoped contexts. Finally, access to data must be controlled by explicit policies that define which data an agent can access, under what conditions, and for how long.
Agent identity
Identity management for AI agents must go beyond simply extending the user’s identity. In a zero-trust architecture, both user identity and agent (workload) identity must be authenticated, authorized, and isolated by clear trust boundaries.
When building agents, it’s critical to evaluate whether user identity propagation is sufficient for use cases such as short-lived, user-initiated tasks or whether the agent needs a dedicated identity. Agents that act autonomously, operate outside the user’s permission scope, or persist beyond the user session require a distinct identity to ensure secure, auditable, and least-privilege access to data and tools.
When to use user identity alone?
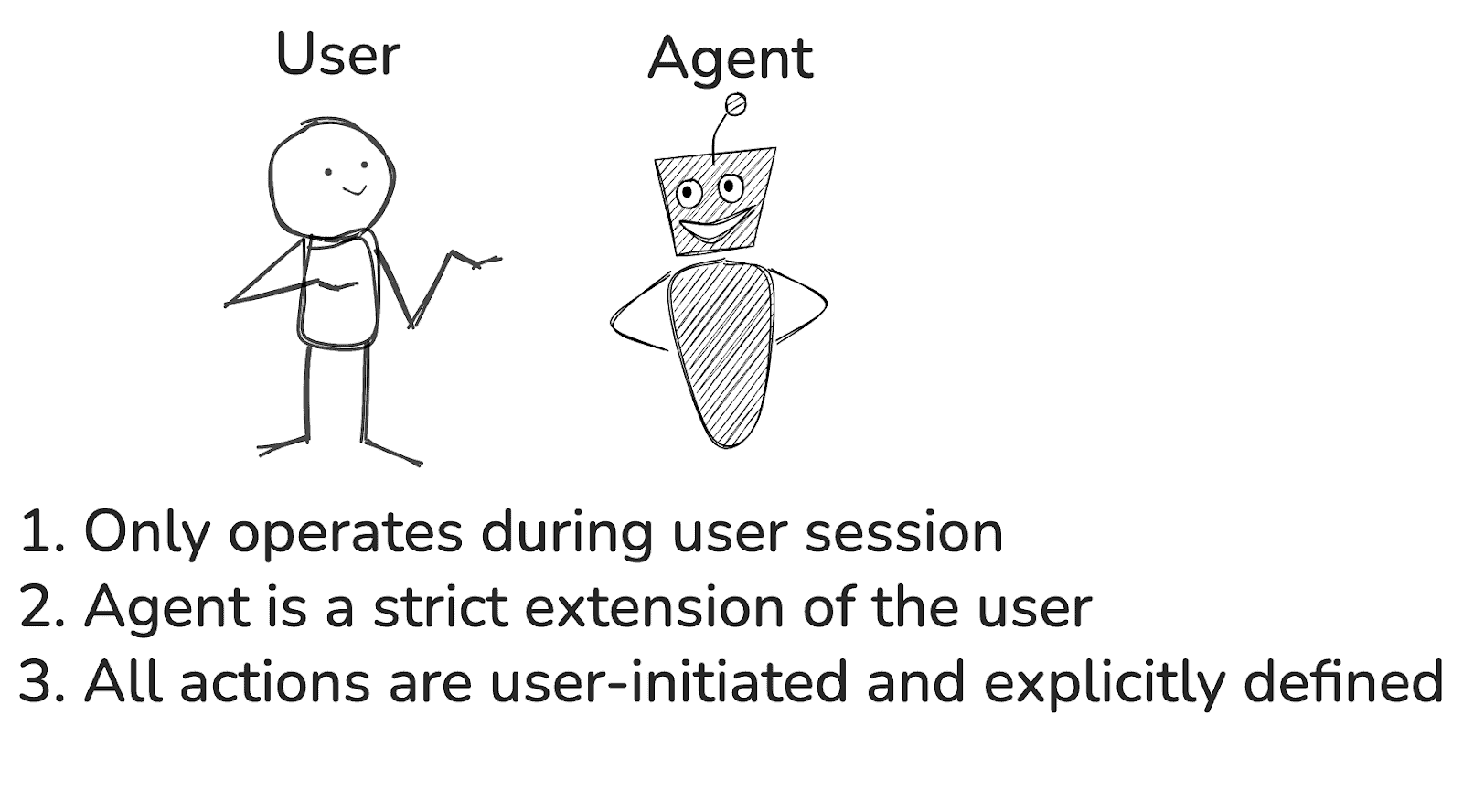
Source: Diagram created by the authors using Excalidraw.
If an agent’s existence and capabilities are strictly tied to the user being actively logged in or connected, the user identity alone is sufficient for the agent identity. Once the user logs out or their session expires, the agent should also cease functioning or lose access. In the scenario, the agent’s identity and permissions mirror exactly those of the user.
When is agent identity required?
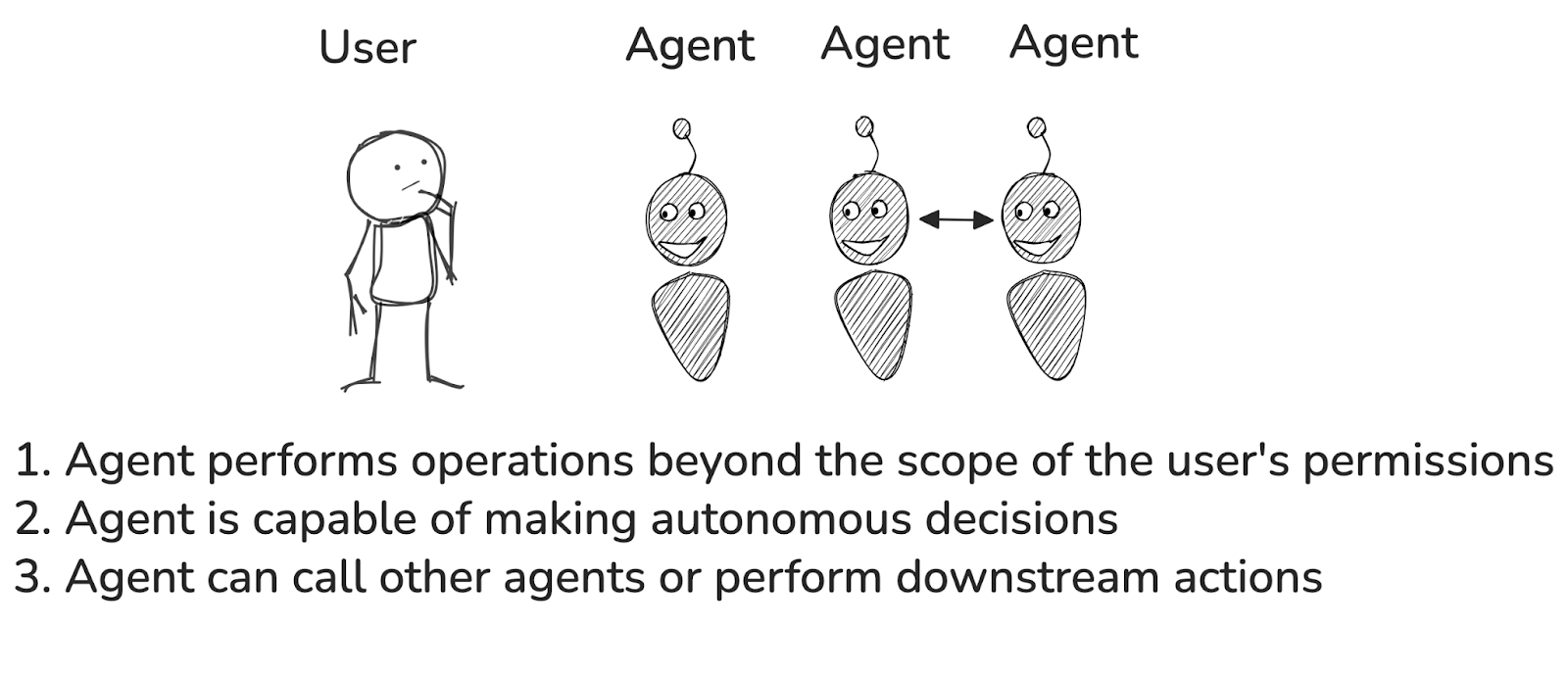
Source: Diagram created by the authors using Excalidraw.
Use agent-specific identities when the agent performs actions beyond the user’s permissions (for example, accessing cross-department data or sensitive information). This is also needed if the agent can make autonomous decisions (initiating workflows, API calls, placing orders, etc.) or if it can interact with other agents and trigger downstream processes.
By clearly distinguishing between user and agent identities and enforcing authentication, authorization, and trust boundaries, systems can minimize the risk of overprivileged agents, prevent lateral movement, and better support auditing and policy enforcement.
The following practices for agent identity should followed:
- Assign a unique workload identity to each agent instance
- Avoid shared or reused identities, and instead use Cloud Native workload identities such as SPIFFE IDs, Kubernetes service accounts, etc. Identity reuse across agent instances or sessions can result in agents retaining or leaking state.
- Avoid static service accounts with broad permissions. The agent identity must be scoped, ephemeral, and least privileged.
- Prefer scoped JWTs or OAuth2 access tokens as opposed to static tokens to tightly control authorization at runtime, and establish clear policies for access fallback behavior, including for disconnected states.
- Use short-lived, automatically rotated credentials tied to agent lifetimes
- For agents created dynamically (e.g., spawned per request or task), generate short-lived identities tied to their runtime scope with automatic rotation (OIDC tokens with TTL, certs with limited validity).
- Agents should be issued time-bound OIDC tokens, SPIFFE/SVID certificates, or ephemeral API credentials with strict TTLs. These credentials should expire when the agent shuts down or after a session timeout.
- Where possible, bind the credential to the agent’s identity and execution context (e.g., a specific namespace or pod UID) to prevent reuse or theft
- Audit and log agent identity usage
- Track which agent used which identity, when, and for what purpose. This is critical for accountability, especially in multi-agent or distributed systems. Note: Secure, tamper-proof logging may be required to support non-repudiation and forensic analysis. Consider using append-only logs or systems with cryptographic guarantees to ensure log integrity.
- “Know your agents”. Maintain a registry of validated agents and track who launched the agent, when, and what permissions it has.
- Ensure delegated actions between agents are logged and auditable to detect misuse of one agent’s identity by another.
- Verify agent identity before each action, not just at the start
- Re-authenticate and re-authorize mid-session for sensitive actions.
- Create enforcement boundaries for agent identity
- Service meshes, Kubernetes NetworkPolicy, API gateways, etc., to ensure agents can only communicate with authorized tools and services.
- This layered defense limits lateral movement if an agent is compromised or misbehaves due to prompt injection or tool hijacking.
- Ensure that agents cannot access resources or perform actions via another agent without explicit authorization (delegation security).
- If using MCP Authorization, follow the authorization flow described in the authorization spec if using HTTP-based transport protocols.
- Use a secure, discoverable naming and identity resolution system
- Adopt frameworks like the OWASP Agent Name Service (ANS) for cryptographically verifiable agent discovery and naming.
Agent tenancy
Agent tenancy spans service-to-service exposure, access to hardware resources (e.g., GPUs), permission scopes, and agent-to-agent interaction. To maintain secure, predictable, and fair behavior in multi-agent environments, tenancy controls must be enforced at both identity and execution layers.
Permissions tied to agent identity should enforce the principle of least privilege and use mechanisms such as Just-in-Time (JIT) to request access only when needed and Attribute-Based Access Control (ABAC) and Policy-Based Access Control (PBAC) to define flexible and secure access policies. As agents introduce probabilistic behavior, adopting these controls based on the agent identity is essential to maintaining trust, traceability, and security at scale.
The following practices for agent tenancy should be adhered to:
- Enable Just-in-Time (JIT) access provisioning
- Create short-lived ephemeral permissions for the task at hand. Agents should request access only when needed, and lose it when done, reducing the risk of excessive permissions.
- Enforce the Principle of Least Privilege (PoLP)
- Agents should only receive the minimal required permissions for their operation. Assume every granted permission will eventually be used. “Just in case” permissions are dangerous since agents are designed to explore options.
- Use fine-grained, scoped tokens per tool with OAuth2 scopes.
- Dynamically strip or mask environment variables containing secrets or keys based on the tool context. For example, don’t inject API keys into an agent that doesn’t perform a task that requires the API key.
- Agents should only receive the minimal required permissions for their operation. Assume every granted permission will eventually be used. “Just in case” permissions are dangerous since agents are designed to explore options.
- Use Attribute-Based Access Control (ABAC) and Policy-Based Access Control (PBAC)
- Define dynamic policies to control permissions for the agent based on the task or environment.
- Isolate agents per trust boundary using strict workload partitioning
- Follow recommendations for isolating agents based on namespace separation, container isolation, network segmentation, or hardware partitioning (especially those representing different users, roles, or organizational functions).
- Leverage service mesh capabilities (e.g., mTLS, identity-aware routing, and authorization policies) to enforce secure communication and fine-grained access control between agents operating across trust boundaries.
Agent data access
Agents often interact with diverse data stores, including those shared across multiple agents or tenants. This requires careful design to enforce strong authentication, fine-grained authorization, and clear trust boundaries to prevent data leakage, tampering, and privilege escalation. Proper access control must be implemented to uphold least-privilege principles, especially when agents operate autonomously. This section outlines key security concerns related to agent data access, emphasizing unique threats such as prompt injection, tool hijacking, and runtime memory vulnerabilities, and provides recommendations to mitigate these risks.
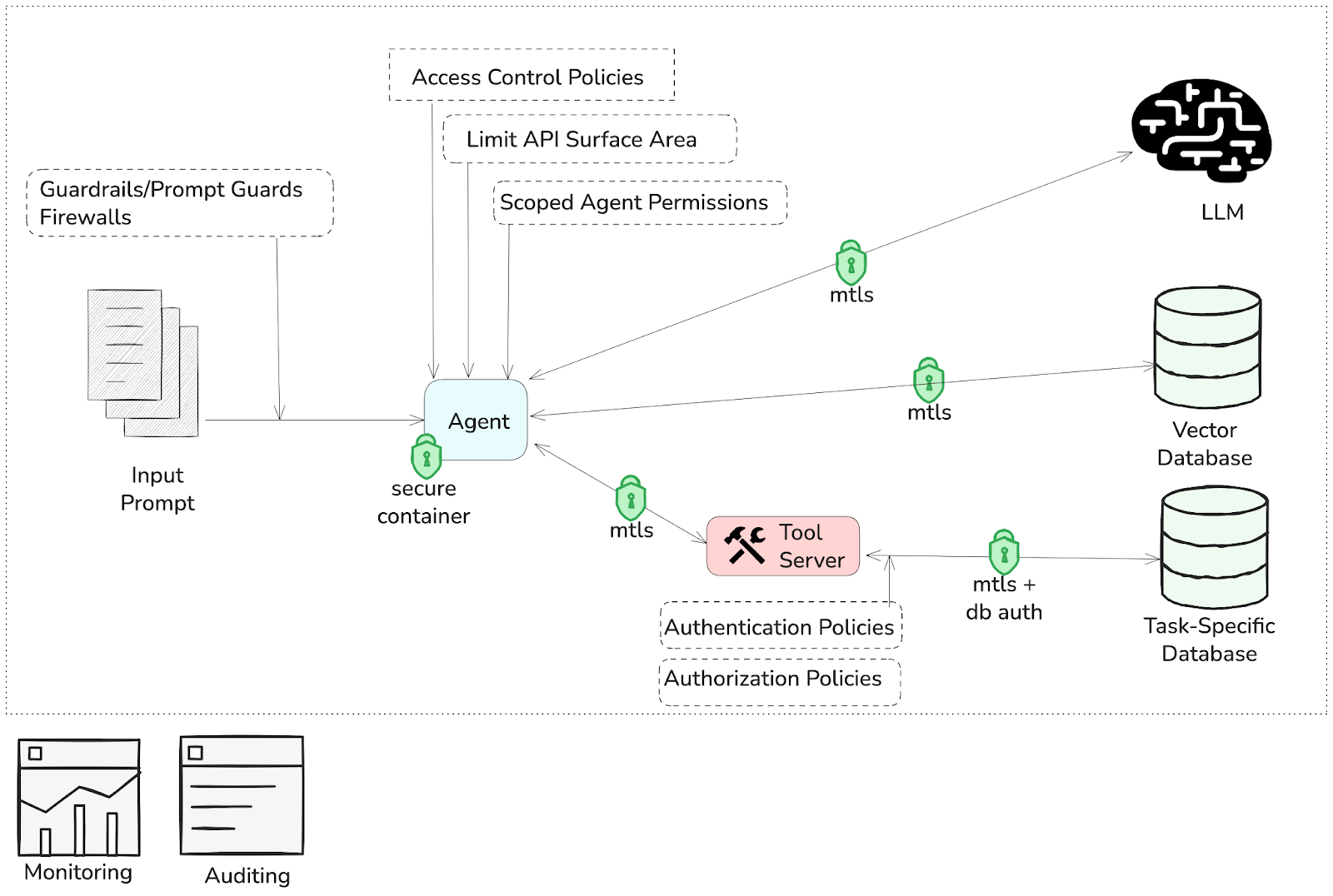
Source: Diagram created by the authors using Excalidraw.
- Control access agents have for data sources.
- Agents must have strictly scoped access to data stores, limiting exposure to only the necessary information for their task
- When multiple agents access common stores (e.g., Retrieval-Augmented Generation (RAG) databases), enforce strong data segregation and query-level access controls to prevent leakage.
- Mitigate prompt injection and jailbreaking vulnerabilities
- Implement rigorous input validation and sanitization to filter out malicious payloads.
- Use context-aware prompt templates and guardrails that limit agent responses to authorized scopes.
- Employ monitoring and anomaly detection to catch unusual agent behavior indicative of prompt tampering (see observability section for more details).
- Restrict access to prevent tool hijacking and unintended execution
- Enforce strict permission boundaries on tool invocation, allowing agents to access only authorized tools.
- Only allow agents to use pre-approved tool interfaces.
- Audit and log all tool execution requests to detect unauthorized or unexpected calls.
- Apply strong authentication and authorization on internal APIs, using zero-trust principles to limit the risks of exposing internal APIs and multi-agent collaboration
- Limit API surface area exposed to agents, and segregate APIs by agent roles or tasks.
- Use network segmentation and firewall rules to restrict API access to only trusted agent processes.
- Continuously monitor API usage for unusual patterns or abuse.
- Use mTLS to secure all inter-service and agent-tool communications.
- Deploy agents in isolated runtime environments (e.g., containers, sandboxes)
- Enforce strict memory and file system access controls to limit an agent’s visibility and scope.
- Leverage hardware-based isolation mechanisms, such as Trusted Execution Environments (TEEs) or secure enclaves, and GPU-based confidential computing features to protect model execution and intermediate memory states when running agents on shared infrastructure.
- Protect agent execution environments and internal logic
- Minimize system prompt leakage. Ensure that system prompts and configuration details are not exposed through user-facing APIs, logs, or client-side code. Use context-scoped prompts and redact sensitive content in observability tools.
- Restrict access to agent source code and runtime binaries. Avoid shipping exposed Python binaries or readable scripts; use compiled artifacts, signed containers, or encrypted packages where possible.
- Redact or rewrite sensitive flows. Add an additional layer of prompt moderation or transformation before LLMs receive inputs or return outputs.
Footnotes/Links:
- MCP provides transport-level authorization that allows clients to securely request resources on behalf of resource owners. For HTTP-based transports, this involves standardized authorization headers and token-based authentication mechanisms. Implementations using HTTP SHOULD adhere to the flow outlined in the spec to ensure interoperability and proper access control. https://modelcontextprotocol.io/specification/2025-06-18/basic/authorization
- ANS provides a DNS-like mechanism using PKI, structured schemas, and Zero-Knowledge Proofs (ZKP) to validate agent identity and capabilities. This enables trusted resolution across multi-agent systems while mitigating threats such as agent impersonation and registry poisoning: https://genai.owasp.org/resource/agent-name-service-ans-for-secure-al-agent-discovery-v1-0/
- Resources for guides for using confidential containers and supporting GPUs:
Contributing
This document is subject to a high-change revision cycle due to the rapid pace of evolution in the agentic AI space. Community contributions are welcome and encouraged.
For details on how to propose changes, draft updates, request reviews, and follow the versioning and governance process, please see the Contributing Guide.