
Member post originally published on Greptime’s blog by tison
This article introduced the differences between InfluxQL, Flux, and SQL as query languages. SQL is a more common and general language for querying time series data, making migrating from InfluxQL to SQL a growing trend.

GreptimeDB uses SQL as its primary query language. Once users ingest data into GreptimeDB via the InfluxDB line protocol or other APIs, a common question arises: how can I analyze the data ingested? Specifically, how can existing InfluxQL queries be migrated to SQL queries?
To address the question above, this article outlines the differences between the query languages of InfluxDB (InfluxQL or Flux) and SQL, as well as a cheat sheet for migrating from InfluxQL to SQL.
Overview of Query Languages
InfluxQL
InfluxQL is the primary query language for InfluxDB V1. It’s a SQL-like query language but not a SQL dialect. Below are some examples of InfluxQL queries:
SELECT * FROM h2o_feet;
SELECT * FROM h2o_feet LIMIT 5;
SELECT COUNT("water_level") FROM h2o_feet;
SELECT "level description", "location", "water_level" FROM "h2o_feet";
SELECT *::field FROM "h2o_feet";When InfluxDB was designed and developed, there weren’t as many database developers as today. Consequently, despite InfluxQL’s efforts to closely resemble SQL syntax, implementing basic SQL capabilities supported by relational algebra and adding time series query extensions was quite challenging.
InfluxQL instead implemented functions and syntax specifically designed for time series data analysis. For instance, all InfluxQL queries default to returning the timestamp column in ascending order, and all queries must include field columns to return results.
Additionally, special query syntax is designed for querying over time series rather than rows.
Essentially, InfluxQL was developed from the raw need for time series data analysis focused on numerical metrics. As InfluxDB evolved, InfluxQL also supported continuous queries and retention policies to solve some requirements of real-time data processing.
Although InfluxQL can still be used in InfluxDB V2, it faces a series of challenges due to model mismatches, as InfluxDB V2 mainly promotes the Flux query language.
Keep reading
- Convert Grafana dashboards from InfluxQL to PromQL
- Understand infrastructure monitoring basics
- Can we standardize query languages?
- Register for KubeCon + CloudNativeCon North American 2024 today
Flux
Flux is the primary query language for InfluxDB V2. Unlike InfluxQL, which has a SQL-like syntax, Flux uses a DataFrame style syntax. Developers who have written programs in Elixir will find the syntax familiar. Here are some examples of Flux queries:
erlang
from(bucket: "example-bucket")
|> range(start: -1d)
|> filter(fn: (r) => r._measurement == "example-measurement")
|> mean()
|> yield(name: "_result")Designed to support joint analysis of time series data across various data sources, Flux allows users to fetch data from time series databases (InfluxDB), relational databases (PostgreSQL or MySQL), and CSV files for analysis. For example, sql.from or csv.from can replace from(bucket) in the example above, allowing fetching data from other sources.
Flux can only be used in InfluxDB V2; it is not implemented in V1 and has been abandoned in V3. The reason is apparent: the learning curve is too steep. Without professional language developers, expanding syntax while fixing various design and implementation issues is almost impossible, resulting in unsustainable engineering costs.
SQL
SQL, the Structured Query Language, is familiar to data analysts and is based on relational algebra.
Unlike DSLs tailored for specific business scenarios, SQL has a solid theoretical foundation. Since E. F. Codd published the seminal paper “A Relational Model of Data for Large Shared Data Banks,” research on relational databases has flourished for over fifty years.
Despite unique extensions in various SQL databases that sometimes confuse users, the basic query and analysis capabilities are consistently implemented across all SQL databases, supported by relational algebra. One or two decades ago, there might have been debates about SQL’s relevance. However, SQL has undoubtedly reasserted itself as the default choice for data analysis today. Over the years, SQL has been continuously improved and expanded, and it is widely adopted globally through a series of proven implementations.
SQL is the primary query language for InfluxDB V3 and GreptimeDB. Both now recommend users analyze time series data using SQL.
In GreptimeDB, you can use standard SQL to query your data:
SELECT ts, idc, AVG(memory_util)
FROM system_metrics
GROUP BY idc
ORDER BY ts ASC;The solid theoretical foundation of SQL helps emerging time series databases reliably implement complex query logic and data management tasks. Also, the broader SQL ecosystem enables emerging time series databases to quickly integrate into the data analysis tech stack. For example, in the previous input behavior analysis demos, we showcase an integration between GreptimeDB and Streamlit for visualizing time series by leveraging GreptimeDB’s MySQL protocol support.
Challenges in Time Series Analysis
SQL
While SQL has a solid theoretical foundation and a broader analytical ecosystem, traditional SQL databases suffer when handling time series data, primarily due to their large size.
The value provided from a single data point of a time series is often very low. Most metrics uploaded by devices aren’t explicitly handled, and the healthy status reported doesn’t require special attention. Thus, the cost-efficiency of storing time series data is crucial. How to leverage modern cloud commodity storage to reduce costs and use cutting-edge compression for time series data are key points for time series databases.
Furthermore, extracting essential information efficiently from vast amounts of time series data often requires specific query extensions for optimization. GreptimeDB’s support for RANGE QUERY to help users analyze data aggregation within specific time windows is one such example.
Flux
The learning curve itself essentially doomed this dialect. As mentioned above, being a DSL solely supported by a single provider, Flux faced significant challenges in language robustness, performance optimization, and ecosystem development. The sole provider has since abandoned further development of Flux, making it a language of the past.
InfluxQL
Although InfluxQL syntax resembles SQL, subtle differences can be frustrating. Despite efforts to mimic SQL syntax, InfluxQL fundamentally remains a DSL tailored to time series analysis needs focusing on metrics. Its challenges in development and maintenance costs are similar to those faced by Flux.
For example, InfluxQL does not support JOIN queries. Although one can write queries like SELECT * FROM "h2o_feet", "h2o_pH", it simply reads data from both measurements separately:
> SELECT * FROM "h2o_feet", "h2o_pH"
name: h2o_feet
--------------
time level description location pH water_level
2015-08-18T00:00:00Z below 3 feet santa_monica 2.064
2015-08-18T00:00:00Z between 6 and 9 feet coyote_creek 8.12
[...]
2015-09-18T21:36:00Z between 3 and 6 feet santa_monica 5.066
2015-09-18T21:42:00Z between 3 and 6 feet santa_monica 4.938
name: h2o_pH
------------
time level description location pH water_level
2015-08-18T00:00:00Z santa_monica 6
2015-08-18T00:00:00Z coyote_creek 7
[...]
2015-09-18T21:36:00Z santa_monica 8
2015-09-18T21:42:00Z santa_monica 7Moreover, despite InfluxDB V3 supporting InfluxQL due to strong user demand to facilitate migration, InfluxDB V3 primarily promotes SQL-based queries. Thus, it’s fair to say that InfluxQL is also fading away.
Migrating to SQL Analysis
Today, many existing time series data analysis logics are written in InfluxQL. This section outlines the core differences between InfluxQL and SQL and illustrates how to migrate from InfluxQL to SQL.
Timestamp Column
A key difference in application logic migration is that SQL does not treat the time column especially, while InfluxQL returns the time column by default and sorts results in ascending order by timestamp. SQL queries need to explicitly specify the time column to include timestamps in the result set and manually specify sorting logic.
-- InfluxQL
SELECT "location", "water_level" FROM "h2o_feet";
-- SQL
SELECT ts, location, water_level FROM h2o_feet ORDER BY ts ASC;When writing data, InfluxQL automatically populates the time column with the current time, whereas SQL requires manual specification of the time column value. If using the current time, it must be explicitly written:
-- InfluxQL
INSERT INTO "measurement" (tag, value) VALUES ('my_tag', 42);
-- SQL
INSERT INTO measurement (ts, tag, value) VALUES (NOW(), 'my_tag', 42);InfluxQL does not support inserting multiple rows in one INSERT statement, whereas SQL databases typically support this:
INSERT INTO measurement (ts, tag, value) VALUES (NOW(), 'my_tag_0', 42), (NOW(), 'my_tag_1', 42);Additionally, InfluxQL uses the tz() function to specify the query timezone, while SQL typically has other ways to set the timezone. GreptimeDB supports MySQL and PostgreSQL syntax for setting the timezone.
Time Series
InfluxQL implements time series granularity query syntax, such as SLIMIT and SOFFSET.
SLIMIT limits the number of data points returned for each time series in the result set. For example, SLIMIT 1 means, at most, one result per time series that meets the filter condition.
SQL, not specifically designed for time series data analysis, requires some workarounds:
SELECT DISTINCT ON (host) * FROM monitor ORDER BY host, ts DESC;This query returns one result per time series, distinguished by the host tag:
+-----------+---------------------+------+--------+
| host | ts | cpu | memory |
+-----------+---------------------+------+--------+
| 127.0.0.1 | 2022-11-03 03:39:58 | 0.5 | 0.2 |
| 127.0.0.2 | 2022-11-03 03:39:58 | 0.2 | 0.3 |
+-----------+---------------------+------+--------+Interval Literals
InfluxQL’s interval syntax resembles 1d or 12m, while SQL has standard syntax for time intervals:
INTERVAL '1 DAY'
INTERVAL '1 YEAR 3 HOURS 20 MINUTES'Data Columns and Tag Columns
InfluxQL distinguishes between data columns and tag columns at the model level; queries that only SELECT tag columns will not return data. InfluxQL also supports the ::field and ::tag suffixes to specify data columns or tag columns, allowing for columns with the same name.
SQL standards do not differentiate between data columns and tag columns, treating them all as regular columns. However, specific implementations may map these concepts differently. For example, GreptimeDB’s data model distinguishes between timestamp columns, tag columns, and data columns and has corresponding mapping rules.
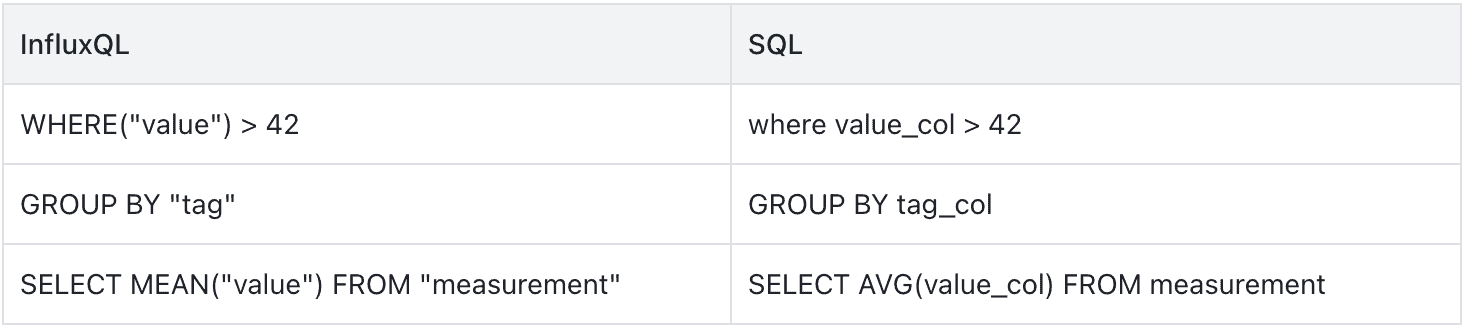
Function Names
Some function names differ between InfluxQL and SQL. For instance, the MEAN function in InfluxQL corresponds to the AVG function in SQL.
However, many other functions, such as COUNT, SUM, and MIN, remain the same in both languages.
Identifiers
In InfluxQL, identifiers are always double-quoted, while SQL supports unquoted identifiers.
It is worth noting that SQL identifiers are case-insensitive by default. If case sensitivity is needed, the identifiers should be enclosed in the appropriate quotes. In GreptimeDB, double quotes are used by default. However, when connecting via MySQL or PostgreSQL clients, the corresponding dialect’s syntax is respected.
Examples of identifier usage differences between InfluxQL and SQL are as follows:
JOIN
InfluxQL does not support JOIN queries, while one of the fundamental capabilities of SQL databases is support for JOIN queries:
-- Select all rows from the system_metrics table and idc_info table where the idc_id matches
SELECT a.* FROM system_metrics a JOIN idc_info b ON a.idc = b.idc_id;
-- Select all rows from the idc_info table and system_metrics table where the idc_id matches, and include null values for idc_info without any matching system_metrics
SELECT a.* FROM idc_info a LEFT JOIN system_metrics b ON a.idc_id = b.idc;
-- Select all rows from the system_metrics table and idc_info table where the idc_id matches, and include null values for idc_info without any matching system_metrics
SELECT b.* FROM system_metrics a RIGHT JOIN idc_info b ON a.idc = b.idc_id;These are examples of JOIN queries in GreptimeDB, which supports:
- INNER JOIN
- LEFT JOIN
- RIGHT JOIN
- FULL OUTER JOIN
Queries over Time Windows
InfluxQL’s GROUP BY statement supports passing a time window to aggregate data within a specific length of time windows.
SQL does not have such specific query capabilities; the closest equivalent is the OVER ... PARTITION BY syntax, which can be quite complex to understand.
GreptimeDB implements its own RANGE QUERY extension syntax:
SELECT
ts,
host,
avg(cpu) RANGE '10s' FILL LINEAR
FROM monitor
ALIGN '5s' TO '2023-12-01T00:00:00' BY (host) ORDER BY ts ASC;Continuous Aggregation
InfluxQL supports continuous aggregation, which corresponds to the standard concept of materialized views in SQL.
However, the implementation of materialized views in most SQL databases is still fragile and remains an area for further exploration. GreptimeDB supports continuous aggregation to meet these needs based on its flow engine.
Conclusion
This article introduced the differences between InfluxQL, Flux, and SQL as query languages. While InfluxQL and Flux are used by InfluxDB and specifically created for handling time series data, SQL is a widely used query language in relational databases. Its robust theoretical foundation and rich ecosystem allow data analysts to quickly get started and use effective tools for time series data analysis.
GreptimeDB natively supports SQL queries. Visit our homepage for more information or create a free cloud service instance to start your trial today.
About Greptime
We help industries that generate large amounts of time-series data, such as Connected Vehicles (CV), IoT, and Observability, to efficiently uncover the hidden value of data in real-time.
Visit the latest version from any device to get started and get the most out of your data.
- GreptimeDB, written in Rust, is a distributed, open-source, time-series database designed for scalability, efficiency, and powerful analytics.
- Edge-Cloud Integrated TSDB is designed for the unique demands of edge storage and compute in IoT. It tackles the exponential growth of edge data by integrating a multimodal edge-side database with cloud-based GreptimeDB Enterprise. This combination reduces traffic, computing, and storage costs while enhancing data timeliness and business insights.
- GreptimeCloud is a fully-managed cloud database-as-a-service (DBaaS) solution built on GreptimeDB. It efficiently supports applications in fields such as observability, IoT, and finance.
Star us on GitHub or join GreptimeDB Community on Slack to get connected. Also, you can go to our contribution page to find some interesting issues to start with.