
Member post by DatenLord

In the previous article, we started from why we need command deduplication mechanism, introduced the necessity of deduplication and some problems of the current deduplication mechanism of Xline, and explained the working principle of RIFL (Reusable Infrastructure for Linearizability), as well as analyzed its performance. This article will be based on this further in-depth explanation.
Problems of implementing RIFL in CURP
The purpose of RIFL is to serve as a system infrastructure to provide exactly-once semantics for RPC, which can naturally be applied to CURP systems. In the CURP paper, RIFL is mentioned several times, as well as some of the changes that need to be made to RIFL to migrate to CURP.
It is recommended that readers who have not read the previous Xline source code analysis first read and understand the principles of CURP.
In the CURP paper §C.1 Modifications to RIFL, the following two changes are described:
First, because of the witness’s replay mechanism, any command may be repeatedly accepted by a new master, and if we rely on the de-duplication mechanism provided by RIFL, the out-of-order ordering of replay commands may result in later acknowledgments rejecting replays of earlier commands. For example, Cmd(first_incomplete=5), Cmd(first_incomplete=1), if replayed in the order of 5 -> 1, then 1 will be ignored. So in the witness replay phase, no processAck is performed.
Secondly, in RIFL, when client_id expires due to client crash, server will clean up all the completion records under this client_id, then in witness replay, the command of the expired client_id will be ignored. So the expiration of the client_id may need to be delayed until the command is synchronized to the backup server.
The content of this article is to introduce how to implement RIFL in Xline’s CURP system and solve some relevant problems.
The implementation of command deduplication in Xline
Lease Server Implementation
In RIFL, the LeaseManager module will act as a witness to the survival of a client. In Xline, it is confusing to rely on another system to provide the Lease mechanism, and it seems that the only way to solve this problem is to implement the Lease Server inside Xline. Of the three node roles, Leader is the most appropriate.
Before implementing the Lease Server, we need to define the following functionality:
- Client needs to get its client id when it sends its first proposal, so it needs to register with Lease Server and get a client id.
- The Client needs to send heartbeats to the Lease Server at regular intervals to ensure that the lease is valid for a long period of time.
- Client needs to get a new client id from Lease Server when its own client id expires.
- Leader needs to check whether a proposal is expired or not, it needs to check whether the client id is expired or not in Lease Server.
- Lease Server should delete and recycle the client id when it expires.
After determining the functionality of the appeal, you can get the RPC definition of Lease Server:
message ClientLeaseKeepAliveRequest {
// The optional client_id, 0 means a grant request
uint64 client_id = 1;
}
message ClientLeaseKeepAliveResponse {
// The refreshed(generated) client_id
uint64 client_id = 1;
}
service Protocol {
...
rpc ClientLeaseKeepAlive (stream ClientLeaseKeepAliveRequest)
returns (ClientLeaseKeepAliveResponse);
}The sender of the RPC is a stream. All requests in the stream are heartbeats, except the first request for the client id, which is used to renew the lease.
Only when the Lease Server finds that the client id has expired or does not exist, it will generate a new client id and return it to the client, otherwise, the server will never return the message.
In addition, this also solves one of the problems described in the RIFL paper: RPC Server repeatedly checking the Lease situation with Lease Server will become a bottleneck.
Tracker Implementation

Looking back at some of the components in RIFL, we can see that two components are very similar: RequestTracker and ResultTracker.
For the RequestTracker on the client side, it needs to generate a series of consecutive sequence numbers and record the acceptance of these sequence numbers, which in turn drives the first incomplete to increase, confirms the received position and sends it to the server for recovery.
Similarly, the ResultTracker on the server side needs to record the sequence number from a Client, check for duplicates, and finally recover all previous records based on the first incomplete from the client.
It is easy to think of the following linear data structure design for sequence number sequences.
Green color indicates that client/server received a return/request from server/client.
Red color means that the client/server has not received a return/request from the server/client.
First incomplete is the first sequence number that did not receive an RPC. Since the first incomplete is pushed by the client and then synchronized to the server, the first incomplete on the server usually lags behind a little bit (indicated by the dotted line in the above figure).
Considering that each grid has only two colors, “green” and “red”, the optimal implementation of this data structure design is to use bitvec (bitmap), which can save a lot of memory overhead, and can be batch accelerated when traversing.
The specific data structure is as follows:
/// Layout:
///
/// `010000000101_110111011111_000001000000000`
/// ^ ^ ^ ^
/// | |________________|____|
/// |________| len |____|
/// head tail
#[derive(Debug, Clone)]
struct BitVecQueue {
/// Bits store
store: VecDeque<usize>,
/// Head length indicator
head: usize,
/// Tail length indicator
tail: usize,
}
/// Track sequence number for commands
#[derive(Debug, Default, Clone)]
pub(super) struct Tracker {
/// First incomplete seq num, it will be advanced by client
first_incomplete: u64,
/// inflight seq nums proposed by the client, each bit
/// represent the received status starting from `first_incomplete`.
/// `BitVecQueue` has a better memory compression ratio than `HashSet`
/// if the requested seq_num is very compact.
inflight: BitVecQueue,
}Tracker recovery
Everything looks great when the core components above are working properly, but would it still look that way if something went wrong?
For example, what if a leadership transfer occurs and the new leader can’t get the information from the old leader tracker? Obviously, this will be a problem, as we do not access the state machine for each deduplication for the sake of performance, but rather maintain a set of memory-based trackers, and we have to consider how this data structure can be recovered during a system migration.
The RIFL paper does not describe in detail how to implement tracker recovery, which is a specific problem we encountered in our implementation; RIFL as a generic mechanism does not discuss this situation. However, the RIFL paper does mention that completion records need to be persisted:
In order to implement exactly-once semantics, RIFL must solve four overall problems: RPC identification, completion record durability, retry rendezvous, and garbage collection
In addition, it is suggested that completion records and operation objects need to be stored together.
RIFL uses a single principle to handle both migration and distributed operations. Each operation is associated with a particular object in the underlying system, and the completion record is stored wherever that object is stored.
If we can recover the tracker from either the operation object or the completion record, we can avoid misclassification due to tracker loss.
The first question is where to store the completion record. The answer is in the log, which is synchronized by each node in the system and applied to its own state machine.
However, CURP system has some differences, the Witness node will also store the proposal, and the completion record can also come from these proposals, in the recovery phase of the CURP system, we can recover the tracker from the proposal recovered from Witness, for example, when we receive the Cmd(client_id=1, first_incomplete=1, first_complete=1, first_complete=1, first_complete=1, first_complete=1, first_complete=1) 1, first_incomplete=5), we can update the ResultTracker of the client with id 1 to 5 (be careful not to processAck in the recovery phase, which will cause subsequent commands with first_incomplete less than 5 to be filtered). Based on this mechanism, we don’t need to worry that the proposal we commit early will not be able to recover the completion record because it is not yet persisted.
In our implementation, we combine the above two scenarios: recovering from logs and recovering from recovered commands. In this way, we can be sure that we have fully recovered the tracker.
Is it really fully recovered?
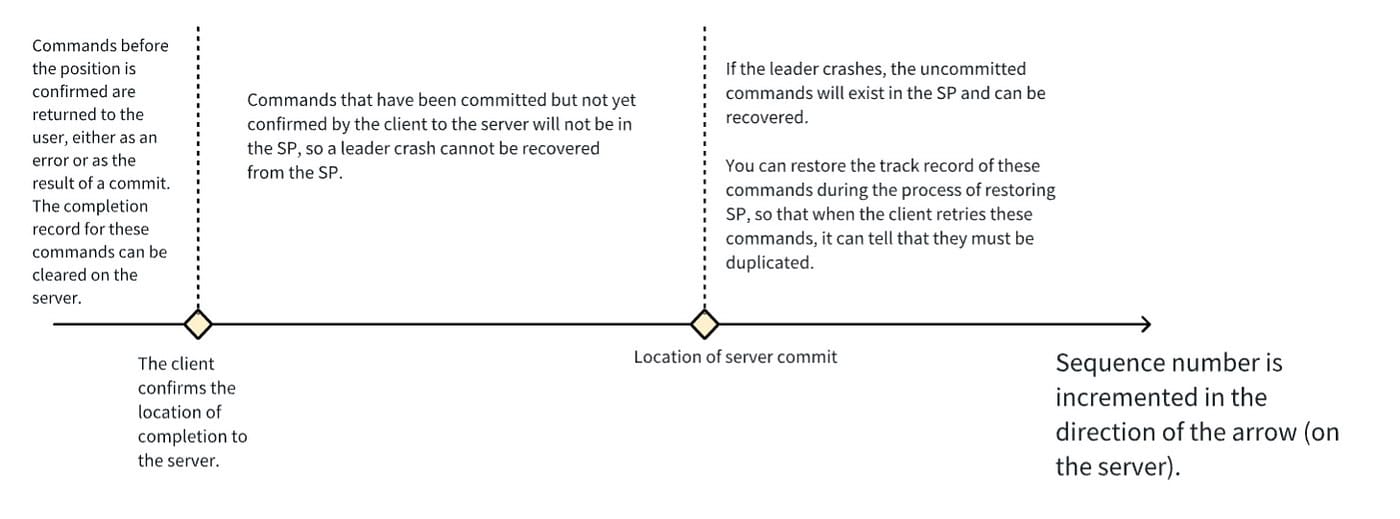
This figure divides the sequence number sent by a client into three segments, the target of tracker recovery is the location where the client confirms to the server that it is done and all the sequence numbers inflighted by the client.
In these three segments, the first segment cannot be recovered, if the client has already confirmed, it means that it has already been returned to the user, so the client is unlikely to retry this command. It may have retried this command before, and retry request in the network delayed for a long time, but will not reach the new leader.
The third segment can be recovered from Witness’s Speculative Pool.
For the second segment, reading the log by default may not recover everything, and with the log compact mechanism, we can’t predict whether the compacted position is in the first segment or not. In order to solve this problem completely, we need to impose a restriction on the log compact: we can’t allow compacting of any sequence number after the one that the surviving client has not yet confirmed.
Lease Server Availability Issues
As I mentioned before, in order to prevent Xline from relying on another Lease system, we implemented Lease Server on the Leader. Since the tracker on the Leader is facing an availability problem, does Lease Server naturally have an availability problem as well?
Actually not :D, think of it in another way, Lease Server acts as a witness to the survival of all clients, if Lease Server crashes, we don’t think Lease Server crashed, we think all clients crashed, thus forcing all clients to give up retrying, giving feedback to the user about the situation and letting the user decide whether to retry or not.
Now that we have tracker recovery, the client id from the recovery process can be used to recover the lease to do Lease Server recovery.
What we haven’t done yet in RIFL
Persistence of Completion Records
RIFL requires completion records to be persisted and migrated with the system, so that even in a new system, duplicates can be checked for and returned to the user for previous executions.
We have not implemented persistence and migration of completion records, if we did, we would need to store the execution result of the command in the corresponding log entry, which is not friendly to the data structure of the log to repeatedly seek and insert the execution result.
Therefore, after the leadership changes, the new leader checks the duplicate command, but cannot get the previous completion record.
We can consider optimizing the log data structure to achieve the persistence and migration of completion records.
Optimization of recycling mechanism
When you look at the previous diagram, you may be agile enough to realize that this structure has a drawback: head-of-line blocking.
The HTTP protocol’s oldest implementations have already solved this problem: Multiplexing.
But the authors of RIFL don’t seem to want to get into this mess.
The garbage collection mechanism could be implemented using a more granular approach that allows information for newer sequence numbers to be deleted while retaining information for older sequence numbers that have not completed. However, we were concerned that this might create additional complexity that impacts the latency of RPCs; as a result, we have deferred such an approach until there is evidence that it is needed.
In fact, this is not a huge problem; unlike HTTP pipelining, not receiving a return does not affect the sending of subsequent requests (as shown above), which may cause the results of a command that has been processed on the server not being reclaimed in time, and taking up too much memory. The RIFL authors mentioned that an upper limit (512 in the paper) could be added to solve this problem, but considering that this problem is not insurmountable, further optimization should be required.
Optimization of some structures under command deduplication
RIFL can be used not only as an RPC de-duplication mechanism, but also to optimize some structures in Xline.
In fact, the idea of de-duplication was prompted by the discovery that the timed GC mechanism of some of Xline’s current components could lead to correctness problems, and that the triggers for these problems were magnified in the madsim test environment, which forced us to reintroduce a new methodology for solving these problems.
Currently, the GC tasks in Xline’s backend include Speculative Pool GC and Command Board GC. Combined with the deduplication mechanism, we can replace these two intervals with active GC after the client confirms the GC, which prevents the unconservative active GC from causing correctness issues.
Speculative Pool GC Optimization
When reclaiming the remaining commands in the Speculative Pool, we can change the original non-conservative timed GC to actively ask the Leader to reclaim them, and the Leader can use the RIFL mechanism to determine to a certain extent whether a command has been committed.
If the RIFL mechanism determines that the command has been confirmed, the command must be commited. For a command that has been committed to the client, but the client has not confirmed it, RIFL cannot immediately determine that it has been committed, so it is necessary to wait for a period of time, and when the client confirms these commands, the Leader can then ask the Leader to recover the command. When the client confirms the command, the leader can check whether the command is committed or not. If the client crashes during this period, the leader can also use the Lease Manager to determine that the client has dropped out of the line, then all the commands inflighted by the client will be invalidated, and we can safely clean up all the commands under this client id.
CommandBoard GC optimization
Similarly, CommandBoard also has a GC timer task, this GC task may lead to recovering the completion records that the client didn’t have time to receive under extreme conditions. With the RIFL mechanism, we can replace the timer GC with the GC after the client’s confirmation, which ensures that the client must have received the completion records.
Summary
In Xline’s CURP system, this paper discusses the implementation of RIFL (Reusable Infrastructure for Linearizability) as an infrastructure to provide Exactly-Once semantics for RPC and the solutions to related problems. It mainly includes the design of Lease Server, the conception, optimization and reliable recovery of Tracker, as well as the optimization of the structure of the background GC Task in the command deduplication scenario. After that, the deduplication mechanism will be further optimized to complete the record persistence and the optimization of the recycling mechanism, which will provide a more complete guarantee of the Exactly-Once semantics and lower performance overhead.