



Member post by DatenLord

Background and Motivation
More and more IT vendors are now embracing cross-cloud multi-clustering as cloud-native technologies and cloud markets continue to mature. Here’s Flexera’s mid-2023 survey on the cloud-native market’s acceptance of multi-cloud, multi-cluster management. (info.flexera.com)
As you can see from Flexera’s report, more than 87 percent of organizations in the overall cloud-native market are already using services from multiple cloud vendors at the same time, with only 13 percent using a single public cloud and a single private cloud. Only 13% are using a single public cloud or single private cloud, while 15% of those using multi-cloud deployments are choosing multi-public or multi-private cloud deployments, and 72% are adopting hybrid cloud deployments. These statistics reflect the maturity of cloud-native technologies and the cloud marketplace, and the future will be the era of programmatic multi-cloud managed services.
As you can see from Flexera’s report, more than 87 percent of organizations in the overall cloud-native market are already using services from multiple cloud vendors at the same time, with only 13 percent using a single public cloud and a single private cloud. Only 13% are using a single public cloud or single private cloud, while 15% of those using multi-cloud deployments are choosing multi-public or multi-private cloud deployments, and 72% are adopting hybrid cloud deployments. These statistics reflect the maturity of cloud-native technologies and the cloud marketplace, and the future will be the era of programmatic multi-cloud managed services.
In addition to external trends, the limitations of single-cluster deployments have become an intrinsic motivation for users to embrace multi-cloud, multi-cluster management. Limitations of single cluster deployments include, but are not limited to:
- A single point of failure, where cluster-level failures are difficult to tolerate, and a small cluster federation outperforms a large K8s cluster.
- Boundary constraints of a single cluster, e.g., a Node has only 110 Pods by default, and a cluster can hold up to 5000 Nodes.
- Business-level development needs, e.g., Xline itself is a cross-cluster cluster.
- ….
Karmada, as an open source multi-cluster management tool, has been used by Shopee, DaoCloud and other companies in the production environment. However, since Karmada currently lacks support for stateful application management, it is still mainly used for stateless application management in practice.
To better cope with the future trend of multi-cloud and multi-cluster management, and to better manage stateful applications in multi-cloud and multi-cluster scenarios, Xline and the Karmada community set up a working group to jointly promote Karmada’s support for stateful application management.
What are the challenges of managing stateful applications with Karmada?
Before understanding how Karmada manages stateful applications across multiple clusters, we need to look back at the K8s implementation of managing stateful applications in a single cluster.
Back in 2012, Randy Bias gave an influential talk on “Open and Scalable Cloud Architecture”. In that talk, he proposed a “Pets” versus a “Cattle”.

These two concepts correspond to stateless and stateful applications, respectively. Cattle don’t need names, and they are not unique. This means we can easily replace one with another when one of them has some problems. Pets are different. Each pet is unique, with its own name, and should be looked after carefully when it has some problems.
StatefulSet was introduced in Kubernetes 1.5 and stabilized in version 1.9. It provides a fixed Pod identity for managing Pods, persistent storage for each Pod, and a strict start/stop order among Pods.
The problems are: what exactly constitutes a state, and how Kubernetes addresses it.

In the Karmada multi-cluster scenario, stateful applications pose the following problems:
- How to ensure that multiple application instances across clusters can have a globally uniform start/stop order, which affects the scale in/out and rolling updates of some application instances. For a distributed KV storage based on consensus protocol, the process of scale in/out needs to go through membership change, which involves the determination of majority change in the cluster. If multiple member clusters scale out at the same time without a globally standardized ordering, it will affect the correctness of the consensus reached by the consensus protocol.
- How to ensure that all applications across clusters have globally unique instance identifiers, a natural solution is to incorporate member cluster ids into instance identifiers.
- How to solve the problem of cross-cluster application communication and provide a globally uniform network identity. Currently, in our attempts and practices, we use submariners to bridge the network communication between multiple member clusters. The current implementation relies on a specific network plugin.
- How to solve the common functions such as cross-cluster stateful application update and capacity expansion and contraction, and provide more fine-grained update policies, such as realizing the function of Partition Update in member clusters.
In order to better solve the above-mentioned problems, we need to introduce a new workload on Karmada to implement a cross-cluster version of “StatefulSet”.
Some early attempts at Xline
Since the Karmada community has not yet discussed the implementation details of the new API, we have made some simple attempts to deploy, scale up and down, and update Xline under Karmada. The overall architecture of the program is as follows:
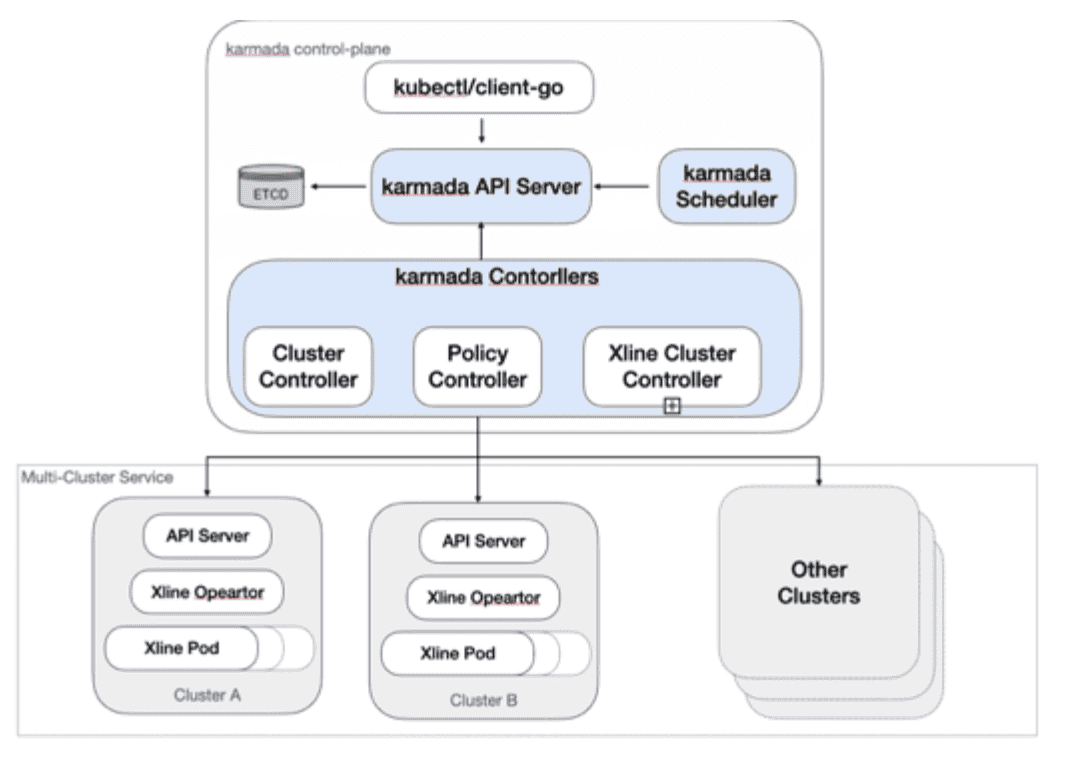
In the overall architecture, we adopt a two-tier Operator approach, in the control plane of Karmada, we deploy a Karmada Xline Operator, which is responsible for interpreting and splitting some Xline resources defined in Karmada, and sending them to member clusters. The Xline Operator on the member cluster monitors the creation of the corresponding resource and then enters the Reconcile process to complete the operation.
Deployment
Let’s take a look at a common deployment method for distributed application clusters under a single cluster (using etcd operator to deploy an etcd cluster as an example). etcd-operator can deploy an etcd cluster in two phases:
- Bootstrap: Create a seed node of etcd with an initial-cluster-state of new and a unique initial-clsuter-token.
- Scale out: perform a member add on the seed cluster to update the cluster network topology, and then start a new etcd node with an updated network topology and an initial-cluster-state of existing.
However, in the cross-cluster scenario, due to the lack of a globally standardized startup order for pods in different member clusters, Xline Operators in different member clusters will concurrently perform cluster expansion operations, which will adversely affect the membership change process of the consensus protocol. In order to bypass this problem, Xline adopts a static deployment method, as shown in the following figure:
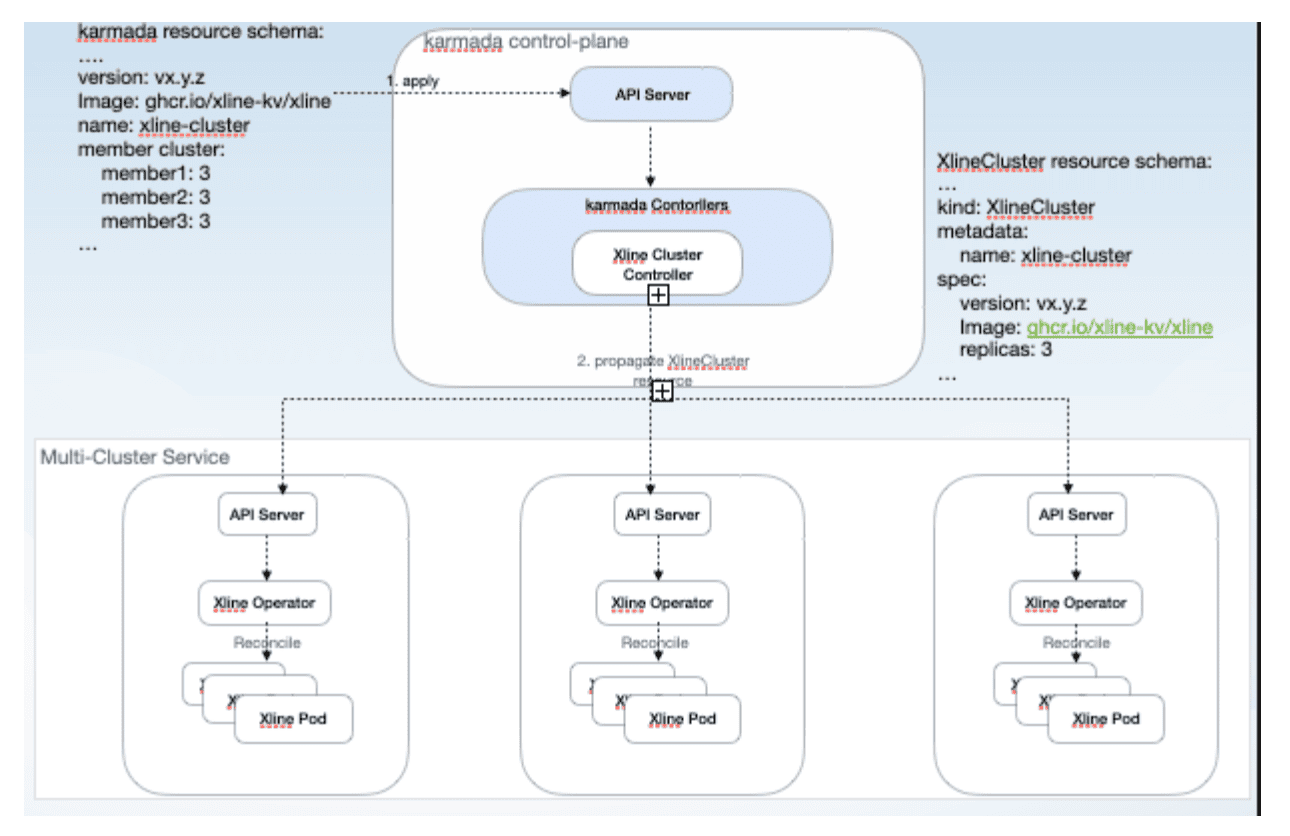
First of all, users need to define the corresponding resources on karmada to describe the cluster topology of a cross-cluster Xline cluster. karmada Xline Operator, after monitoring the resources being applied, will interpret and split the resources into the CR of XlineCluster on the member cluster, and then issue the CR of XlineCluster to the member cluster. The XlineCluster CR contains the number of replicas that should be created for the current member cluster, as well as the member cluster ids of the other clusters and the corresponding number of replicas. The Xline Operator on the member cluster, after monitoring the creation of the CR, will enter the Reconcile process to generate the DNS names of the other nodes in the Xline cluster using the issued cluster topology, and start the Xline Pod.
In the early days of exploration, the static deployment approach bypassed the lack of a globally uniform startup order for application instances under Karmada’s multiple clusters because it did not involve a membership change in the deployment process. However, there is no silver bullet in the software industry, and the same is true for static deployments, which have some trade-offs as follows. The following table compares the characteristics of dynamic and static deployments in a single cluster vs. multi-cluster scenario:

Scaling Up and Down
There are two specific types of scale in/out for stateful applications under Karmada:
- Horizontal scale in/out — remove/add a member cluster and scale in/out nodes on it.
- Vertical scale in/out — scale in/out on existing member clusters.
Horizontal scale out
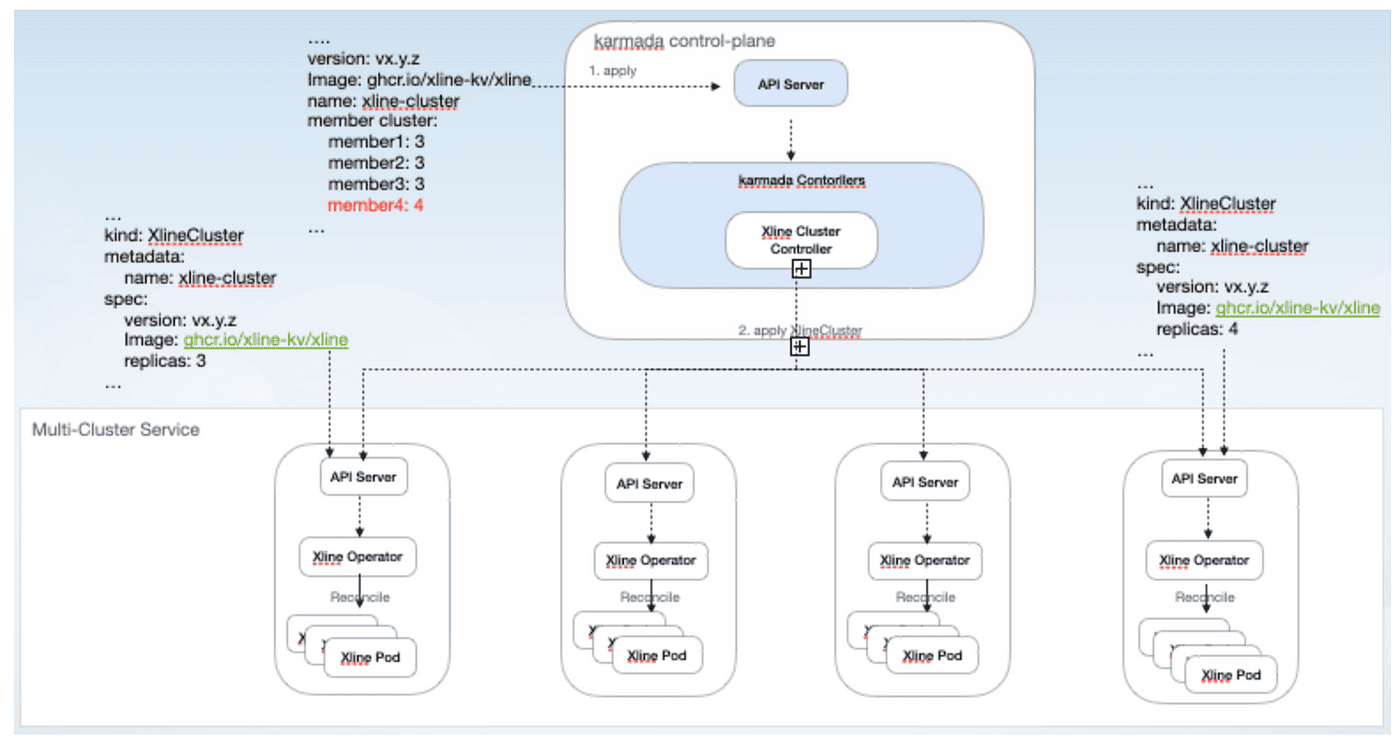
As shown above, the overall process is as follows:
- Create the corresponding member cluster, configure the submariner network, and add it to Karmada for management.
- Modify the Xline resources on Karmada, and add a new record member4: 4in the member cluster field to indicate that you want to expand 4 Xline resources on member4.
- Karmada Xline Operator will split the resources and distribute them to member4.
- Xline Operator on member4 receives the corresponding resources, enters the corresponding Reconcile process, calls the Xline client to execute member add, reaches a consensus, starts the new Xline Pod, and repeats the above process until the number of Xline replicas on member4 reaches the specified number. on member4 reaches the specified number
Vertical scale out
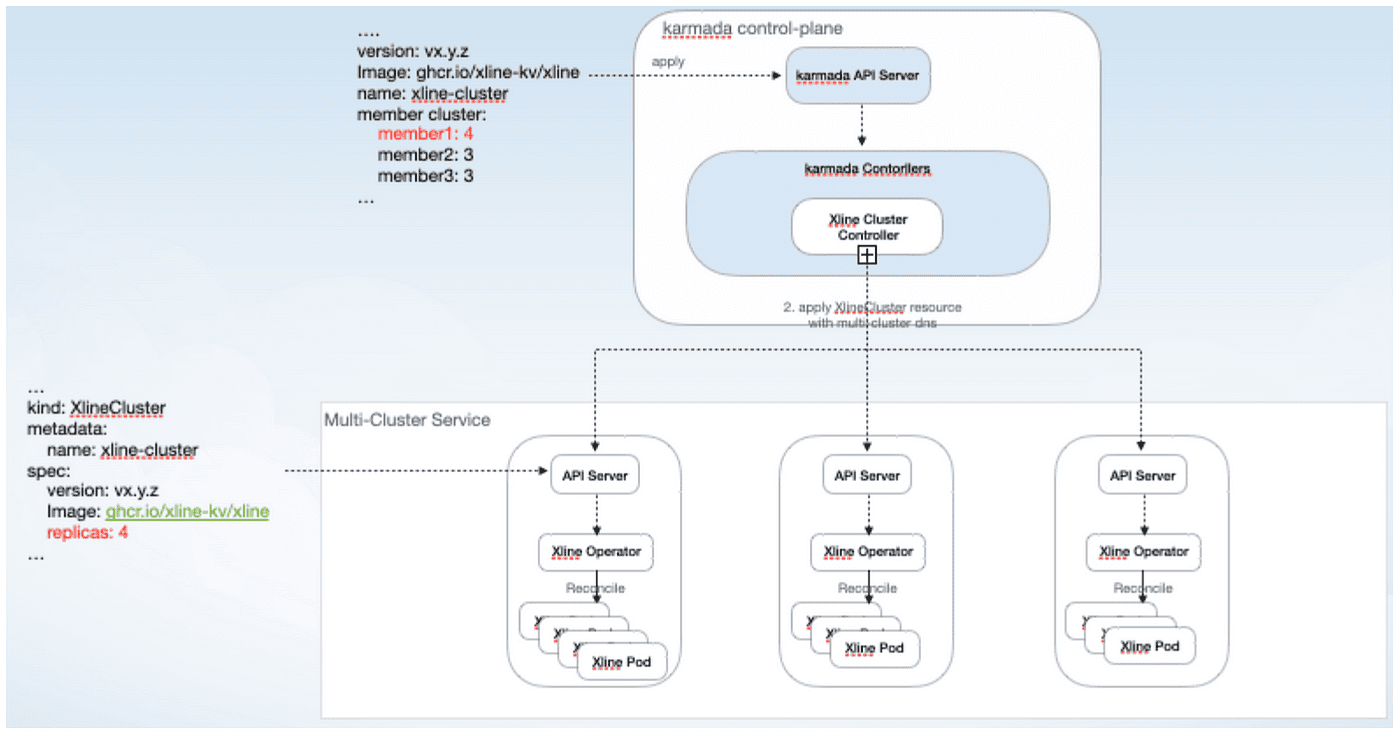
For vertical scale out, the general process is also shown above:
- Modify the Xline resources on Karmada, e.g., specify that the Xline Pod in member1 should be expanded from 3 to 4
- Karmada Xline Operator will split the resource and distribute it to member1
- When Xline Operator on member1 receives the notification of resource modification, it enters the corresponding Reconcile process, calls the Xline client to perform member add, and then starts the new Xline Pod after consensus is reached, and repeats the above process until the number of replicas of Xline on member1 reaches the specified number. replicas of Xline on member1 reach the specified number
Currently, because scale in/out inevitably involves a membership change process, and there is a lack of synchronization between member clusters under Karmada, there are limitations to the scale process: a horizontal scale out can only scale a cluster, and a vertical scale out can only scale a cluster on a specified member cluster.
Rolling updates
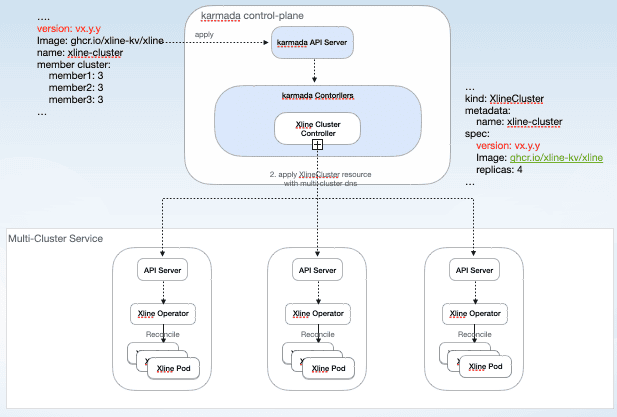
For a rolling update, the general process is shown above:
- The user modifies the Xline resource on Karmada to change the Xline mirror version.
- The Karmada Xline Operator splits the resource and distributes it to the member clusters.
- The Xline Operator on the member cluster monitors the resource changes and enters the corresponding Reconcile process to perform a rolling update. The update process on the member cluster is no different from the update on a single cluster.
Currently, the main supported update method is the default rolling update, but from the perspective of practical application scenarios, at least the following two issues need to be considered:
- The update process involves the stopping of old Xline nodes and the starting of new Xline nodes, which requires additional mechanisms to ensure that the update process is not unavailable.
- More fine-grained update policies, such as Partition Update, should be supported; among multiple member clusters, priority should be given to updating clusters where only the follower exists, and when updating the member cluster where the leader resides, the leader should be transferred to the updated member cluster to avoid extreme situations where the leader frequently steps down due to rolling updates.
Conclusion
Given the trend of multi-cloud and multi-cluster management and the nature of Xline’s business, the Karmada and Xline communities have formed a working group to promote stateful application management in Karmada multi-clusters. In order to solve the problem of managing stateful applications in Karmada multi-clusters more elegantly, we need to introduce a new Karmada workload, and since the Karmada community has not yet reached a consensus on the implementation details of the new workload, in the early stage of experimentation, Xline adopts a two-tier Operator approach, which is implemented through the Karmada Xline Operator to the Karmada Xline Operator. The Karmada Xline Operator interprets and splits the top-level resources and sends them to the member clusters, and then the Xline Operator on the member clusters tunes the resources.
In this way, we have made some early attempts to deploy Xline on Karmada and explore rolling updates, and made some preliminary preparations for the development and design of the new Karmada StatefulSet workload in the future.