
Member post by DatenLord

In the previous article on code interpretation, we briefly explained how the CurpServer of Xline is implemented. Now, let’s delve deeper into some core data structures in the CurpServer, particularly the conflict_checked_channel and command worker, as they collaborate to drive the state transitions of the internal state machine in the CurpServer.
Why do we need a conflict detection queue?
The conflict detection queue serves as a multi-producer multi-consumer channel, and its primary responsibility is to maintain dynamical conflict relationships. It ensures that, at any given time, all receivers will not receive conflicting commands. The order of commands received by the receiver (referred to as the “conflict order”) follows these criteria:
- If cmd A conflicts with cmd B, and A is enqueued before B, A will be dequeued first. B can only be dequeued after A has executed.
- If cmd A doesn’t conflict with cmd B, and A is enqueued before B, they will be dequeued in FIFO order, with A dequeued first and B afterwards.
Understanding this in text might seem abstract, but no worries. Let’s look at a simple example: Assume we now have commands A, B, and C. They enter the conflict detection queue in the order A, B, and C. Where A conflicts with B, and C does not conflict with either A or B, the initial state of the conflict detection queue is as follows:
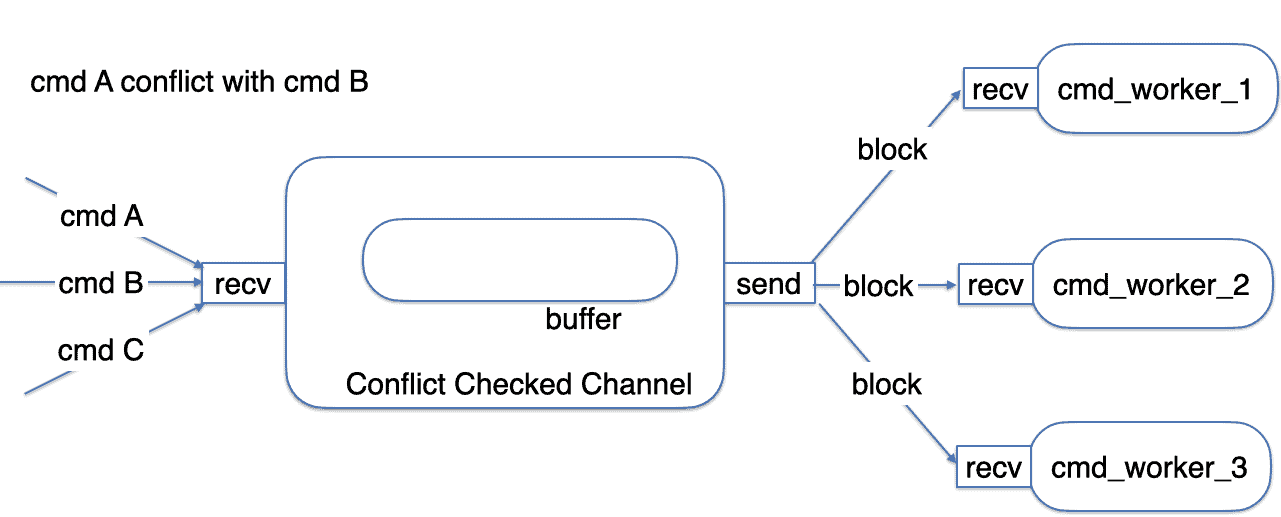
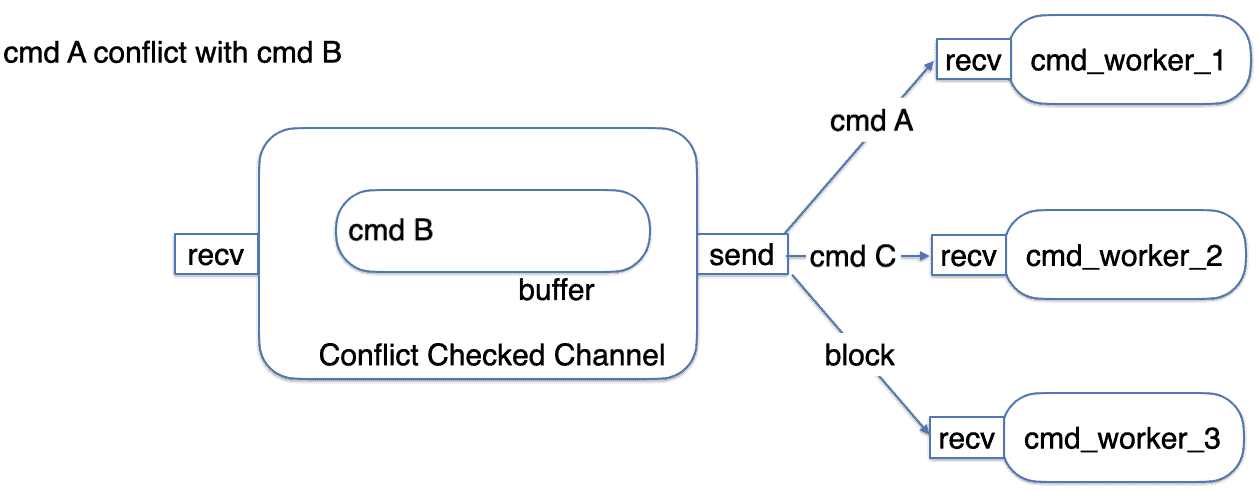
After A, B, and C enter the queue, three different cmd_workers retrieve commands from the channel. Since cmd_worker_1 receives A first, B remains in the queue due to its conflict with A. C, having no conflicts, can be received by cmd_worker_2. B will only be dequeued after A has been executed and dropped, as illustrated in the following diagram:
Some readers might question why we introduce another conflict detection queue when the spec_pool’s duty is to determine conflicts in the fast path, corresponding to the “witness” in the CURP paper. There are two main reasons for this:
- Every command, whether it’s on the fast path or the slow path, must ultimately be executed on the leader. Hence, the leader must find a reasonable execution order among these mixed commands to ensure the execution does not break CURP’s assumptions about command execution order. Spec_pool only stores commands executable in the fast path and doesn’t involve commands in the slow path.
- During the consensus process, we first determine whether a command exists in the spec_pool. This is a synchronous operation. If we put the complicated conflict order calculations into the spec_pool, it would easily create a bottleneck. Hence, we split the responsibilities of determining conflicts and calculating conflict order, placing the former in the synchronous spec_pool and the latter in the asynchronous conflict detection queue.
How does the conflict detection queue work?
To understand the working principle of the conflict detection queue, we need to address two questions:
- How should we model the conflict relationships?
- Given dynamic conflict relationships, how do we quickly identify all non-conflicting commands?
For the first question, we can view all commands as vertices in a Directed Acyclic Graph (DAG), with the conflict relationships represented as directed edges between vertices. Suppose there’s a conflict between command A and command B (A arrives before B), we can represent this conflict with an arc <A, B>, where the head of the arc always points to the later-arriving vertex (this ensures no cycles in the graph).
Once we define the conflict relationship as an edge in a disconnected DAG, the problem of determining the conflict order when executing a command becomes a matter of finding the topological order of the connected component in the DAG that the command belongs to. For each command, successors store which cmds conflict with the current cmd. The length of successors represents the out-degree of the vertex. Predecessor_cnt represents the in-degree, indicating how many preceding cmds conflict with the current cmd.
Returning to the earlier example of commands A, B, and C, when using a DAG to describe their conflict relationships, the situation is shown in the following diagram:
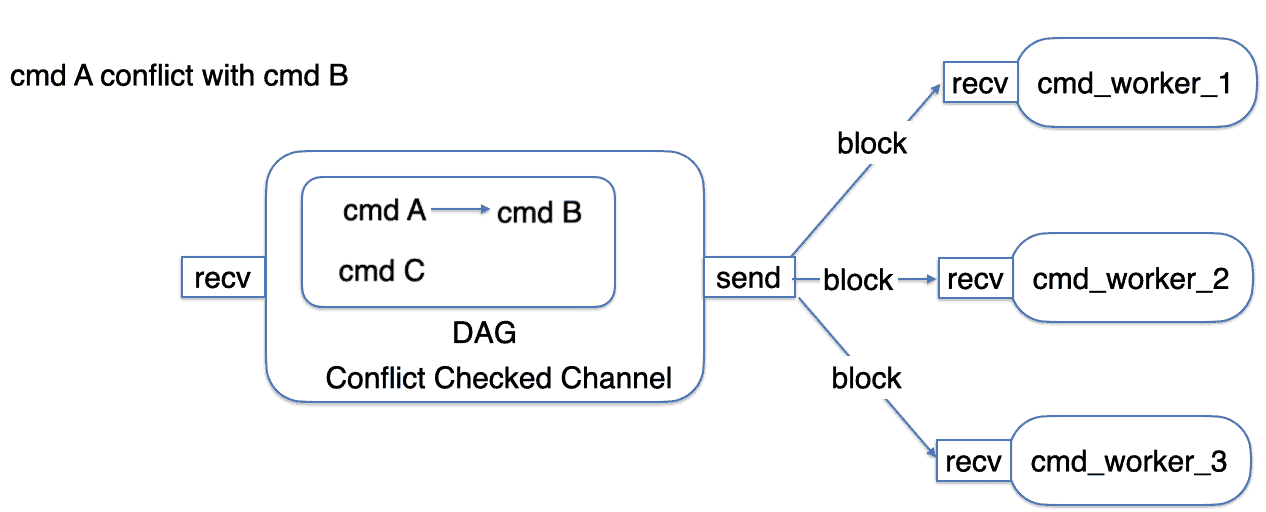
When cmd_workers retrieve commands from the channel, the channel only needs to traverse each connected component of this DAG and find the first vertex with an in-degree of 0. Only after the command has been executed will the channel update B’s predecessor_cnt to resolve the conflict between A and B.
Architecture of the state machine engine
As mentioned at the beginning of this article, the conflict detection queue and command worker together constitute the state machine engine of CurpServer. The conflict detection queue supplies conflict-free commands to the command workers, which then executes these commands and updates the conflict relationships in the conflict detection queue based on the results.
Structurally, the CurpServer’s state machine engine consists of three pairs of channels and a filter. These three channel pairs are: (send_tx, filter_rx), (filter_tx, recv_rx), and (done_tx, done_rx). The specific structure can be seen in the diagram below:
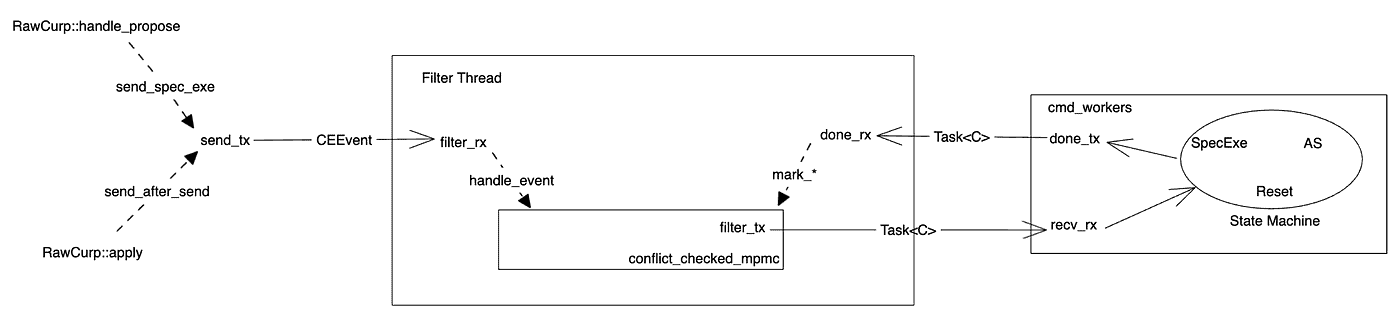
The data flow direction is: send_tx -> filter_rx -> filter -> filter_tx -> recv_rx -> done_tx -> done_rx.
Here, the send_tx owned by the RawCurp object is responsible for sending the corresponding CEEvent to the Conflict Detection Queue during propose (corresponding to CURP’s fast path) and applying logs (corresponding to CURP’s slow path). After determining the conflict order, the Conflict Detection Queue converts the CEEvent into a Task and delivers it to the command worker for execution via (filter_tx, recv_rx). After executing the Task, the command worker sends the results back to the Conflict Detection Queue through (done_tx, done_rx) and updates the vertex information in the dependency graph.
How States Transition
To understand the working principle of a state machine, we need to address the following two questions:
- What events and states are provided by the state machine?
- Which events will cause the state to transition?
Let’s first look at the events provided by the Curp Server’s state machine engine.
/// Event for command executor
enum CEEvent<C> {
/// The cmd is ready for speculative execution
SpecExeReady(Arc<LogEntry<C>>),
/// The cmd is ready for after sync
ASReady(Arc<LogEntry<C>>),
/// omit some code...
}
/// CE task
struct Task<C: Command> {
/// Corresponding vertex id
vid: u64,
/// Task type
inner: TaskType<C>,
}
/// Task Type
enum TaskType<C: Command> {
/// Execute a cmd
SpecExe(Arc<LogEntry<C>>, Option<C::Error>),
/// After sync a cmd
AS(Arc<LogEntry<C>>, C::PR),
/// omit some code...
}/// CE task
struct Task<C: Command> {
/// Corresponding vertex id
vid: u64,
/// Task type
inner: TaskType<C>,
}From the previous description, we can see that the main events of the CurpServer’s state machine engine can be divided into two types. One type is CEEvent, which describes the information of the command itself, including the source of the command. Here, SpecExeReady indicates that the command comes from the fast path, while ASReadey indicates that it comes from the slow path. The other type is Task, describing the vertex id of the command in the dependency graph and the operations that the current command needs to perform.
The state machine engine of CurpServer also defines the following states:
/// Execute state of a cmd
enum ExeState {
/// Is ready to execute
ExecuteReady,
/// Executing
Executing,
/// Has been executed, and the result
Executed(bool),
}
/// After sync state of a cmd
enum AsState<C: Command> {
/// Not Synced yet
NotSynced(Option<C::PR>),
/// Is ready to do after sync
AfterSyncReady(Option<C::PR>),
/// Is doing after syncing
AfterSyncing,
/// Has been after synced
AfterSynced,
}/// After sync state of a cmd
enum AsState<C: Command> {
/// Not Synced yet
NotSynced(Option<C::PR>),
/// Is ready to do after sync
AfterSyncReady(Option<C::PR>),
/// Is doing after syncing
AfterSyncing,
/// Has been after synced
AfterSynced,
}Here, ExeState represents the execution state of the command, while AsState represents whether the command has completed the after_sync phase. CurpServer uses a combination of ExeState and AsState to represent different stages in the command execution process. The semantics represented by different states are as follows:
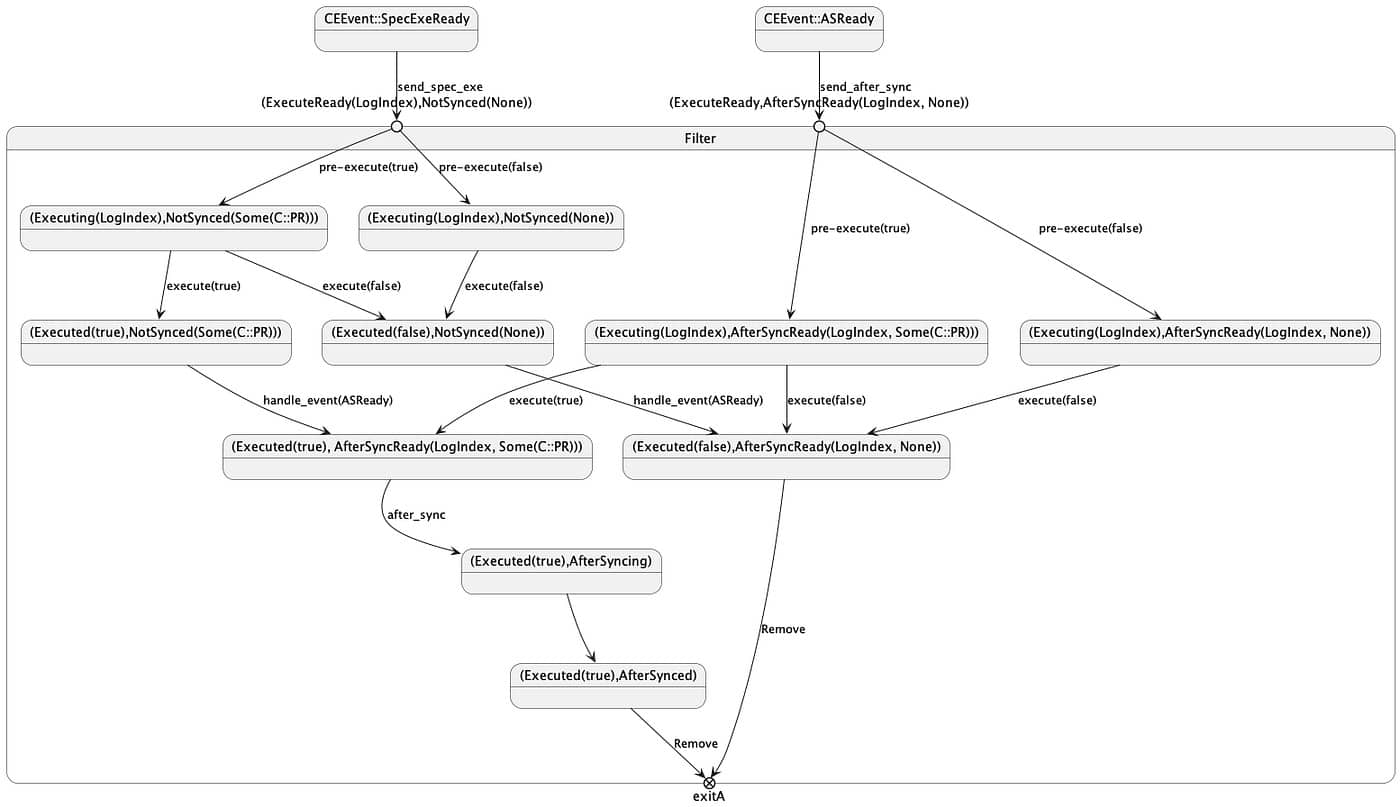
- (ExecuteReady, NotSynced(None)): Represents that the command is ready to proceed to the execute phase and that the command belongs to the fast path. There’s no need to wait for the after_sync to complete before returning results to the user. This state is also the initial state of the state machine engine in the fast path.
- (ExecuteReady, AfterSyncRead(None)): Indicates the command is ready for the execute phase and belongs to the slow path. It needs to wait for after_sync to finish before results can be returned to the user. This is also the initial state of the state machine engine in the slow path.
- (Executing, NotSynced(Some(C::PR))): Represents successful pre_execute execution of the command, having obtained the execution result of pre_execute as Some(C::PR), and the command has also entered the execution state.
- (Executing, NotSynced(None)): Represents the failure of the command’s pre_execute phase.
- (Executed(true), NotSynced(Some(C::PR))): Represents successful command execution.
- (Executed(false), NotSynced(None)): Indicates a command failure in the fast path.
- (Executed(true), AfterSyncRead(LogIndex, Some(C::PR))): Indicates the command has been executed and is preparing for the after_sync phase.
- (Executed(true), AfterSyncing): Represents the command has been executed and is currently in the after_sync phase.
- (Executed(true), AfterSynced): Indicates the successful command execution, and the after_sync phase was also successful.
- (Executing, AfterSyncReady(Some(C::PR))): Represents the command is executing and is preparing for the after_sync phase.
- (Executing, AfterSyncReady(None)): Represents the failure of the command’s pre_execute phase.
- (Executed(false), AfterSyncReady(None)): Indicates a command failure in the slow path.
The relationship between various state transitions is as follows:
Summary
In Xline, whether commands are from the fast path or the slow path, these commands will eventually be executed on the leader node. It is evident that just relying on spec_pool to determine if there’s a command conflict is not enough. This is because spec_pool can only judge whether a new command conflicts with a command that is currently in the execute phase but hasn’t gone through the after_sync yet. It cannot dynamically maintain command conflict relationships. To address the dynamic maintenance of conflict relationships, we introduced the Conflict Detection Queue and constructed the CurpServer’s state machine engine in conjunction with the command worker. Through the execution by the command worker, commands from different paths (fast path and slow path) can transition states based on their current state and return corresponding results to users.