
Member post by DatenLord

In the previous article, An Introduction to the CURP Protocol, we gave a preliminary introduction to the CURP Protocol. Now, let’s continue from where we left off and delve into the internal workings of the CURP Server.
Organization of the Curp Crate’s Source Code
Now, let’s focus on the curp consensus module. The curp module is a separate crate in Xline, with all of its source code stored in the curp directory, which is organized as follows:
curp/proto: Holds the definition of the rpc interfaces and messages related to the curp protocol.
curp/tla+: Holds content related to the tla+ specification of the curp protocol
curp/tests: integration tests
curp/src: the main implementation code of the CURP protocol, which can be divided into:
client.rs: CURP client-side implementation.
cmd.rs: defines key traits for interacting with external mods
log_entry.rs: state machine log entries.
rpc/: CURP server implementation of rpc methods.
server/: CURP server-side implementation, including the following
Key data structure definitions: cmd_board.rs, spec_pool.rs
Key background tasks: cmd_worker/, gc.rs
CURP server front and backend implementations: curp_node.rs, raw_curp/
storage/: implements the interface definition of the persistence layer, used to interact with the storage layer
Curp Server Architecture and Task Division
After understanding the rpc services provided by Curp Server and the corresponding traits, let’s take a look at the architecture and startup process of Curp Server.
Architecturally, the entire Curp Server can be divided into the front-end CurpNode and the back-end RawCurp. Such a design primarily aims to separate synchronous and asynchronous code. Regarding Rust’s asynchronous code:
- For tasks spawned by tokio, since the compiler inherently doesn’t know how long the task will run, it enforces that all tasks must have a ‘static lifetime. This often requires us to clone certain reference data structures.
- Non-Send variables, like MutexGuard, are prohibited from crossing .await statements. When synchronous and asynchronous code are mixed, it necessitates manually releasing this MutexGuard before the await, either within a block or through an explicit drop. This leads to nested code structures, making it more challenging to read.By separating CurpNode (handling synchronous requests) and RawCurp (handling asynchronous requests), the code boundaries are more transparent, enhancing code readability.
For insights on organizing asynchronous code gracefully in Rust projects, you can refer to another article: How to Gracefully Organize Asynchronous Code in Rust Projects.
Within the CurpNode structure, there are spec_pool and cmd_board structures. The spec_pool corresponds to the witness structure in the CURP paper, responsible for storing commands executed in the fast path. In contrast, cmd_board stores the results of command executions. CurpNode can register a listener to cmd_board. Once the RawCurp backend asynchronously completes command execution, the result is inserted into cmd_board, and CurpNode is notified via the listener to return the command execution outcome to the user. When RawCurp receives a request from CurpNode, it inserts the command into the conflict detection queue — the conflict_checked_channel.
As the name implies, a conflict_checked_channel is essentially an mpmc channel that accepts cmd’s from a CurpNode concurrently and dynamically maintains conflict relationships between different cmd’s to ensure that the commands a command worker receives from the channel will always conflict with the currently executing command.
As the name suggests, the conflict_checked_channel is essentially an mpmc channel, capable of concurrently accepting cmds from CurpNode. It dynamically maintains the conflict relationships between different cmds, ensuring that commands retrieved by the command worker from the channel always not conflict with the currently executed commands. The command worker is the command execution entity. While the conflict_checked_channel focuses on relationships between various commands, the command worker is concerned with how to execute the commands. After the command worker completes the command and obtains the result, it inserts the result into cmd_board, triggering the listener and notifying CurpNode that the command execution is finished.
How Curp Server Interacts with Business Server
From the architecture diagram mentioned earlier, we can see that the Curp consensus module provides a Curp Server, which offers rpc services externally. In Xline, the Business Servers make requests to Curp Server via rpc calls. Once the Curp Server processes the request, it notifies the Business Server through the corresponding trait.
Service Definitions
Let’s first take a look at the services defined by Curp Server:
service Protocol {
rpc Propose (ProposeRequest) returns (ProposeResponse);
rpc WaitSynced (WaitSyncedRequest) returns (WaitSyncedResponse);
rpc AppendEntries (AppendEntriesRequest) returns (AppendEntriesResponse);
rpc Vote (VoteRequest) returns (VoteResponse);
rpc FetchLeader (FetchLeaderRequest) returns (FetchLeaderResponse);
rpc InstallSnapshot (stream InstallSnapshotRequest) returns (InstallSnapshotResponse);
}The purposes of these services are:
•Propose: To initiate a proposal request to the Curp cluster.
•WaitSynced: To wait for the Curp cluster to complete requests in the after-sync phase.
•AppendEntries: To initiate a request to the Curp cluster to append state machine logs.
•Vote: When a Curp Server initiates an election, it transitions its role to Candidate and uses this interface to send voting requests to other Curp Servers. If it receives a majority of positive responses, it becomes the leader; otherwise, it reverts to follower.
•FetchLeader: To retrieve the current leader node of the Curp cluster.
•InstallSnapshot: If a Curp Server’s state machine log lags significantly behind the leader, it can request a snapshot from the leader through this interface to catch up with the leader’s state machine log. Except for Propose and FetchLeader, the other services are primarily for internal use by Curp Server. The Business Servers fetch the current leader information via FetchLeader and makes proposals to the Curp cluster through Propose.
Interface Definitions
Next, let’s see which traits are defined by the Curp module. From a design perspective, the traits defined in Curp can be divided into two categories:
- Command-related: Once the Curp module reaches a consensus on a specific command, it notifies the Business Server to execute the corresponding command via related traits.
- Role-related: When the role of a Curp node changes, it notifies the corresponding business component (e.g., Lessor, Compactor) via related traits.
Command-related Traits
The command-related traits defined in the Curp module mainly include Command, ConflictCheck, and CommandExecutor. Let’s first examine the Command and ConflictCheck traits, which are defined as:
pub trait ConflictCheck {
fn is_conflict(&self, other: &Self) -> bool;
}
#[async_trait]
pub trait Command{
/// omit some code...
#[inline]
fn prepare<E>(&self, e: &E, index: LogIndex) -> Result<Self::PR, E::Error>
where
E: CommandExecutor<Self> + Send + Sync,
{
<E as CommandExecutor<Self>>::prepare(e, self, index)
}
#[inline]
async fn execute<E>(&self, e: &E, index: LogIndex) -> Result<Self::ER, E::Error>
where
E: CommandExecutor<Self> + Send + Sync,
{
<E as CommandExecutor<Self>>::execute(e, self, index).await
}
#[inline]
async fn after_sync<E>(
&self,
e: &E,
index: LogIndex,
prepare_res: Self::PR,
) -> Result<Self::ASR, E::Error>
where
E: CommandExecutor<Self> + Send + Sync,
{
<E as CommandExecutor<Self>>::after_sync(e, self, index, prepare_res).await
}
}The Command trait describes a command entity that can be executed by Business Server. ConflictCheck detects whether conflicts exist between multiple commands. The conflict criterion is whether there’s an intersection between keys of two different commands.Command defines four associated types (K, PR, ER, and ASR). Here, K represents the Key corresponding to the command, while ER and ASR correspond to the results of the command in the execute and after_sync phases of the Curp protocol, respectively. What does PR represent? PR denotes the result of the command in the prepare phase.
To explain the need for a prepare phase, let’s consider an example. Since Xline employs the MVCC mechanism for multi-version management of key-value pairs, each key is assigned a revision. If a client sends two consecutive commands to Xline: PUT A=1 and PUT B=1 (denoted as cmd1 and cmd2) with expected revisions of 3 and 4, respectively, Xline can execute these two non-conflicting commands concurrently and out of order. If cmd2 finishes before cmd1, the revision order may be reversed, leading to errors.
To solve this, a prepare phase is introduced to Command. Curp ensures that the execution in the prepare phase is serialized and always precedes the execute phase. By moving the revision calculation from the after_sync phase to the prepare phase, Xline ensures that the revision order matches the order of user requests arriving at Xline while still allowing for concurrent out-of-order execution of non-conflicting commands.
Next, let’s look at the CommandExecutor trait definition:
#[async_trait]
pub trait CommandExecutor<C: Command>{
fn prepare(&self, cmd: &C, index: LogIndex) -> Result<C::PR>;
async fn execute(&self, cmd: &C, index: LogIndex) -> Result<C::ER>;
async fn after_sync(
&self,
cmd: &C,
index: LogIndex,
prepare_res: C::PR,
) -> Result<C::ASR>;
/// omit some code ...
}CommandExecutor describes the command execution entity. The Curp module uses it to notify the Business Server to execute related commands.
The relationship among these three traits is: ConflictCheck describes the relationship between two different commands; the Curp Server cares only about whether commands conflict, not how they are executed. CommandExecutor describes how commands are executed without concerning themselves with their interrelationships. Their dependency is CommandExecutor ←> Command → ConflictCheck.
Traits for Role Change
The role-related trait defined in Curp is RoleChange:
/// Callback when the leadership changes
pub trait RoleChange {
/// The `on_election_win` will be invoked when the current server win the election.
/// It means that the current server's role will change from Candidate to Leader.
fn on_election_win(&self);
/// The `on_calibrate` will be invoked when the current server has been calibrated.
/// It means that the current server's role will change from Leader to Follower.
fn on_calibrate(&self);
}In Xline’s Curp module, the protocol backend uses the Raft protocol. The so-called backend means that when a conflict occurs, the Curp module automatically falls back to the Raft protocol. In this scenario, the latency to reach a consensus is the same as the Raft protocol, both being 2 RTT. As we know, the original Raft paper defined three roles for nodes in a Raft cluster: Leader, Follower, and Candidate, with their transition relationships as follows:

Initially, a node is a Follower. If it doesn’t receive any messages from the current cluster Leader within the election_timeout, including heartbeats or AppendEntries requests, it initiates an election operation and transitions to Candidate. If it wins the election, it becomes the Leader; otherwise, it reverts to the Follower. If a network partition occurs, two Leaders might emerge. Once the network partition resolves, the Leader with a smaller term will calibrate itself upon receiving any message from the Leader with a larger term, updating its term and transitioning to the Follower.
Why does Xline need to define a trait like RoleChange? In some Xline business scenarios, some components, like LeaseServer and LeaseStore, perform different operations on Leader node and non-Leader nodes. Thus, when a node’s role changes, the corresponding components need to be notified. Currently, because Lease-related components only differentiate between Leader and non-Leader nodes, the defined callback only covers the election_win and calibrate events. If future business requires finer-grained role differentiation, more callback methods will be added to cover those requirements.
How Curp Server Handles Requests
Let’s assume there are two PutRequests: PUT A=1 and PUT A=2. Let’s see how the curp server handles these conflicting requests. As mentioned earlier, users need to initiate a proposal to Curp Server through the propose method of the Curp Client. Let’s first look at the pseudocode implementation of propose.
/// Propose the request to servers
#[inline]
pub async fn propose(&self, cmd: C) -> Result<C::ER, ProposeError> {
// create two futures
let fast_round = self.fast_round(cmd);
let slow_round = self.slow_round(cmd);
// Wait for the fast and slow round at the same time
match which_one_complete_first(fast_round, slow_round).await {
fast_round returns fast_result => {
let (fast_er, success) = fast_result?;
if success {
Ok(fast_er.unwrap())
} else {
let (_asr, er) = wait for slow_round to finish;
Ok(er)
}
}
slow_round returns slow_result => match slow_result {
Ok((_asr, er)) => Ok(er),
Err(e) => {
if let Ok((Some(er), true)) = wait for fast_round to finish {
return Ok(er);
}
Err(e)
}
},
}
}As the code suggests, when a Client calls propose, it simultaneously starts two different futures, namely fast_round and slow_round, corresponding to the fast path and slow path of the Curp protocol, respectively. The process waits for one of the futures to complete. Clearly, when the first request arrives, there will be no conflict with other requests. Thus, it can be assumed that this request will be processed during the fast round. Let’s first look at the implementation of fast_round.
Curp Consensus Process — Fast Round
The fast_round code is defined in curp/src/client, corresponding to the frontend process of the Curp protocol.
/// The fast round of Curp protocol
/// It broadcasts the requests to all the curp servers.
async fn fast_round(
&self,
cmd_arc: Arc<C>,
) -> Result<(Option<<C as Command>::ER>, bool), ProposeError> {
let request = create a new ProposeRequest;
let mut rpcs = broadcast request to each node and put responses into a stream;
let mut ok_cnt: usize = 0;
let mut execute_result: Option<C::ER> = None;
let superquorum = superquorum(self.connects.len());
while let Some(resp_result) = rpcs.next().await {
let resp = match resp_result {
Ok(resp) => resp.into_inner(),
Err(e) => {
warn!("Propose error: {}", e);
continue;
}
};
update_state(resp.term, resp.leader_id);
resp.map_or_else::<C, _, _, _>(
|er| {
if let Some(er) = er {
execute_result = Some(er);
}
ok_cnt += 1;
Ok(())
},
|err| {
if let ProposeError::ExecutionError(_) = err {
return Err(err);
}
Ok(())
},
)??;
if (ok_cnt >= superquorum) && execute_result.is_some() {
return Ok((execute_result, true));
}
}
Ok((execute_result, false))
}Overall, the logic of fast_round can be divided into three steps:
- Wrap Command into the corresponding ProposeRequest.
- Broadcast the ProposeRequest to all nodes in the Curp cluster.
- Summarize the results. If the current Command doesn’t conflict with the others, a successful execution result will be obtained. If the number of successful ProposeResponses received exceeds the super quorum (approximately 3/4 of the cluster node count), the command is deemed successfully executed; otherwise, it fails.
Some readers might wonder why, in a distributed cluster with 2f + 1 nodes, consensus protocols like Raft or Paxos only need f + 1 nodes to return a successful response, but Curp requires more than f + f/2+1 nodes to return successful responses in the fast path. Here, f represents the fault tolerance of the cluster. To understand this discrepancy, let’s consider what would happen if the Curp protocol also used f+1as the criterion for success in the fast path.
Assume Client_A broadcasts ProposeRequest (marked as A) to 2f + 1 nodes and receives f + 1 successful responses. There must be one leader node among them, with the remaining f nodes being followers. Suppose f nodes, including the leader, crashed and all had request A. Among the remaining f+1 nodes, only one follower retains request A in its in-memory spec_pool. Then, the client broadcasts another ProposeRequest (marked as B, conflicting with A). Since each node uses its in-memory spec_pool to determine whether incoming requests conflict with speculatively executed requests, even though Client_B won’t receive a successful result, request B will still be saved in the spec_pool of f nodes. If the leader node recovers and replays all requests saved in spec_pool across all nodes to restore the state machine (a process we call “recover”), the originally executed request A becomes the minority, while the unsuccessfully executed request B becomes the majority. This leads to an error during the leader’s recovery process.
When the Curp protocol usesf+ f/2+ 1 as the criterion for success in the fast path, even if all f nodes containing request A crash, there are still more than half the nodes in the remaining f + 1 nodes that retain the request. This ensures that a later conflicting request will not outnumber the originally successfully executed request.
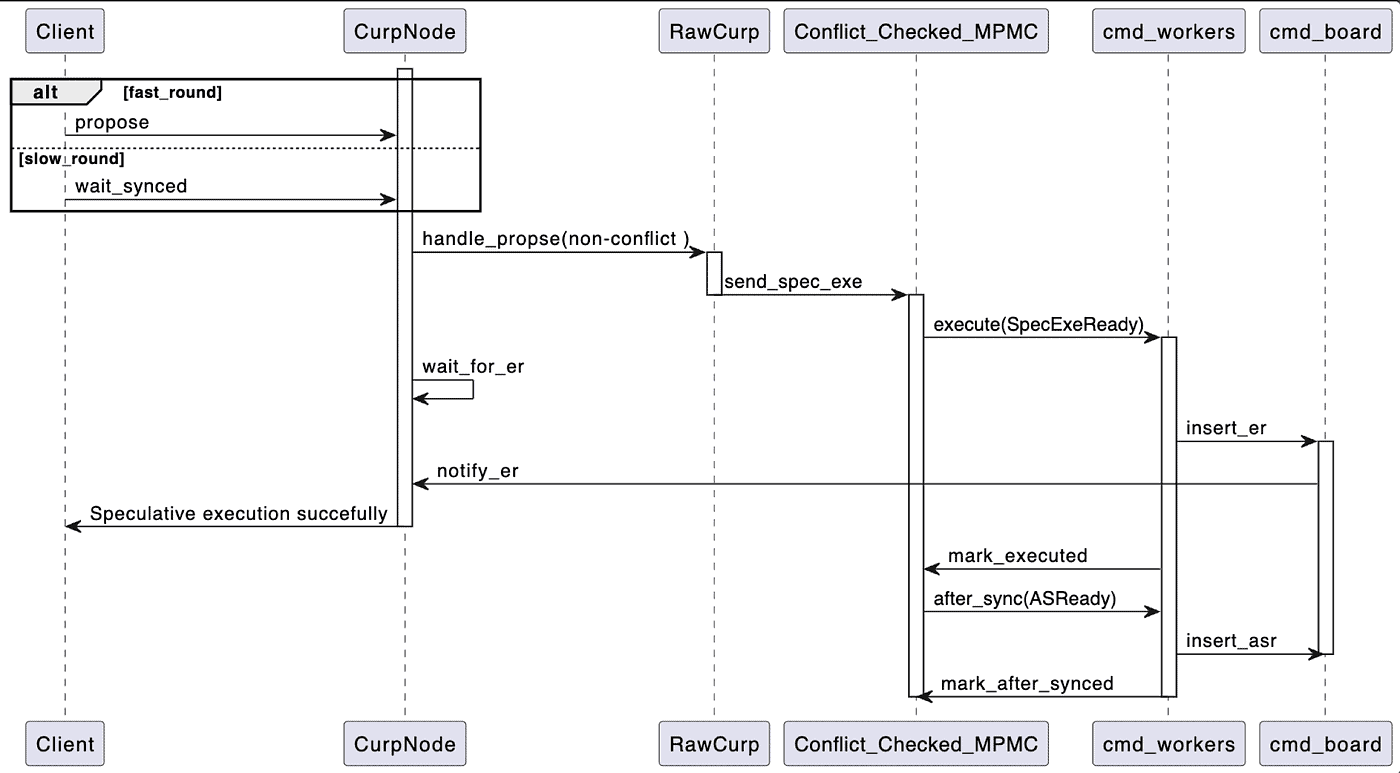
Returning to our example, since Curp Server didn’t encounter conflicts when processing the request PUT A=1, it smoothly completes in the fast_round. For the Leader node, the request goes through CurpNode, to RawCurp, to the conflict detection queue Conflict_Checked_MPMC, and finally handed over to cmd_worker for execution. After the cmd_worker executes PUT A=1, it inserts the corresponding result into cmd_board, notifying CurpNode to return the command execution response to the Client. The following diagram depicts the sequence of events in the fast_round process.
Curp Consensus Process — Slow Round
When the Client sends the request PUT A=2 to the Curp Server, as known from the previous propose method, the Client will simultaneously start both the fast_round and slow_round futures. Clearly, since the request PUT A=2 is in obvious conflict with the previous request PUT A=1, fast_round cannot be successfully executed, hence waiting for the completion of slow_round. The code for slow_round is defined in curp/src/client, corresponding to the backend process of the Curp protocol, i.e., the wait_synced process.
/// The slow round of Curp protocol
async fn slow_round(
&self,
cmd: Arc<C>,
) -> Result<(<C as Command>::ASR, <C as Command>::ER), ProposeError> {
loop {
let leader_id = self.get_leader_id().await;
let resp = match call wait_synced from leader node {
Ok(resp) => resp.into_inner(),
Err(e) => {
wait for retry_timeout to retry propose again;
continue;
}
};
match resp? {
SyncResult::Success { er, asr } => {
return Ok((asr, er));
}
SyncResult::Error(Redirect(new_leader, term)) => {
let new_leader = new_leader.and_then(|id| {
update_state(new_leader, term)
})
});
self.resend_propose(Arc::clone(&cmd), new_leader).await?; // resend the propose to the new leader
}
SyncResult::Error(Timeout) => {
return Err(ProposeError::SyncedError("wait sync timeout".to_owned()));
}
SyncResult::Error(e) => {
return Err(ProposeError::SyncedError(format!("{e:?}")));
}
}
}
}Overall, the slow_round logic can also be divided into two steps:- Obtain the current leader of the cluster and send a WaitSyncedRequest to it.
- Wait for the leader to return the execution result of WaitSyncedRequest. If failed, wait for retry_timeout and try again.
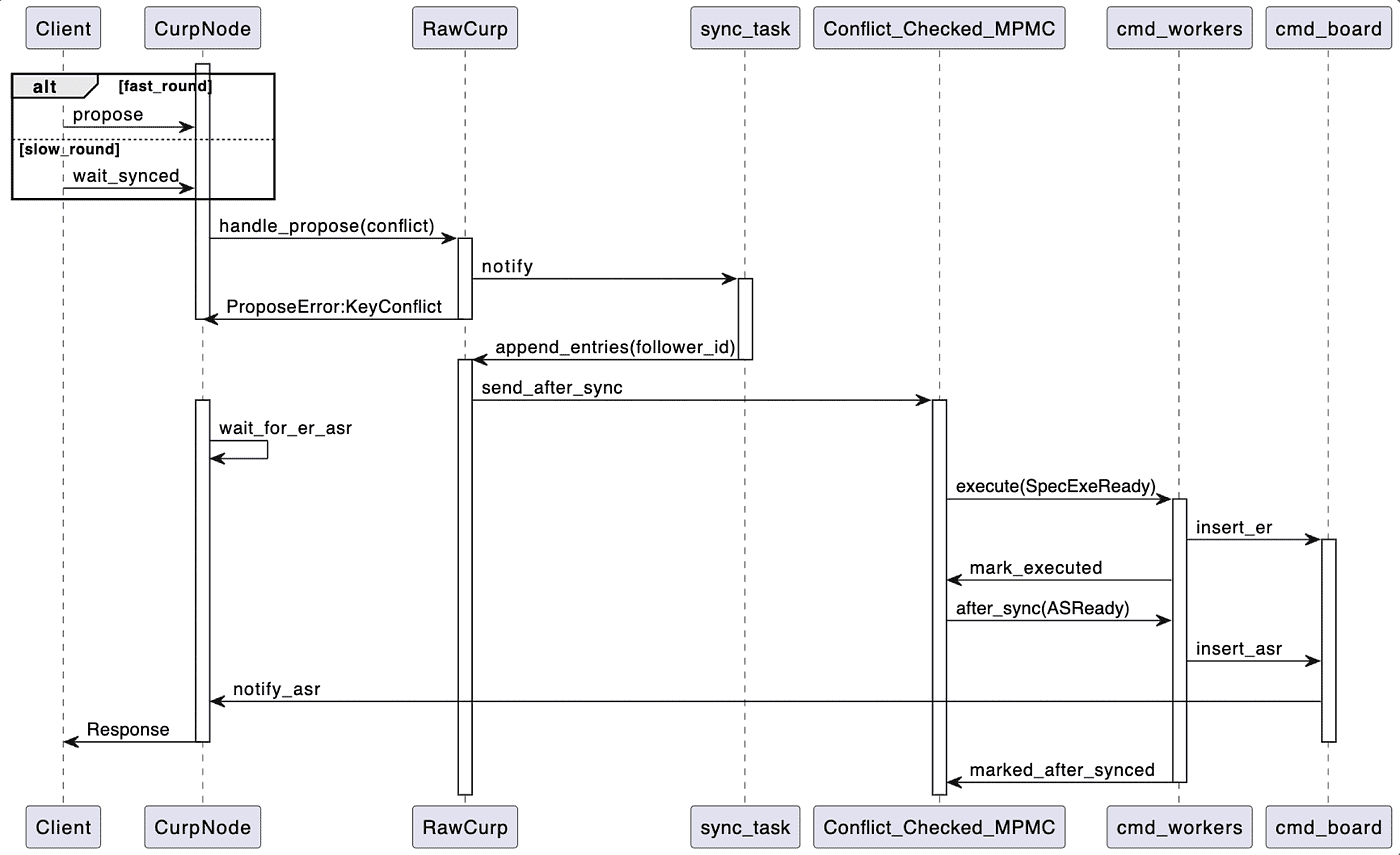
In the Client’s propose method, because fast_round determines that the newly arrived request conflicts with the previously speculatively executed request, RawCurp will first save this Command in the state machine log and initiate an AppendEntries request to the cluster. After completion, it will return a ProposeError::KeyConflict error to the client, waiting for the end of slow_round. After the Leader completes the AppendEntries operation to the Followers in the cluster, the apply operation will be performed to apply the log to the state machine. It’s during this process that the leader will send the Command to the conflict detection queue, Conflict_Checked_MPMC. Only after the cmd_worker has executed all commands conflicting with PUT A=2 can the PUT A=2 command be popped from the conflict detection queue for execution. Unlike fast_round, in the slow_round process, after the command is executed and the execution result is saved in cmd_board, it will not return directly. Instead, the command will be put back into the conflict detection queue until the command completes the after_sync operation and saves the corresponding result to cmd_board. Only then will it return to CurpNode and finally return the corresponding ProposeResponse to the Client. The sequence diagram for the entire slow_round operation is as follows:
Summary
In this article, we discussed how the Curp Server in Xline interacts with the business Servers. The business Server initiates requests to the Curp Server through the RPC interfaces predefined by Curp Server. Curp Server, on the other hand, notifies the business Server through two different types of traits. The command-related Traits, such as Command, ConflictCheck, and CommandExecutor, are mainly responsible for notifying the business Server after reaching consensus on commands. The RoleChange trait mainly notifies the business Server when the role of a cluster node changes.
In Xline, the Curp Server is divided into two parts: the front-end CurpNode and the backend RawCurp. CurpNode mainly handles synchronous RPC call requests and forwards the requests to RawCurp for asynchronous execution. RawCurp submits commands to the conflict_checked_channel, with the command workers responsible for execution. After execution, the result is inserted into cmd_board, notifying CurpNode of the execution result.