

Project post from the Volcano maintainers
Overview
On KubeCon North America 2022, Krzysztof Adamski and Tinco Boekestijn from ING Group delivered a keynote speech “Efficient Scheduling Of High Performance Batch Computing For Analytics Workloads With Volcano” . The speech focused on how Volcano, a cloud native batch computing project, supports high-performance scheduling for big data analytics jobs on ING’s data management platform.
More details: KubeCon + CloudNativeCon North America
Introduction to ING
Internationale Nederlanden Groep (ING), a global financial institution of Dutch origin, was created in 1991 with the merger of Dutch insurer Nationale-Nederlanden and national postal bank NMB Postbank.
ING provides services in more than 40 countries around the world. Core businesses are banking, insurance, and asset management. Their 56,000 employees serve 53.2 million customers worldwide, including natural persons, families, businesses, governments, and organizations such as IMF.
Business Background
Regulations and restrictions on banking vary depending on the country/region. Data silos, data security, and compliance requirements can be really challenging. It is not easy to introduce new technologies. Therefore, ING builds their Data Analytics Platform (DAP) to provide secure, self-service functionality for employees to manage services throughout the entire process.
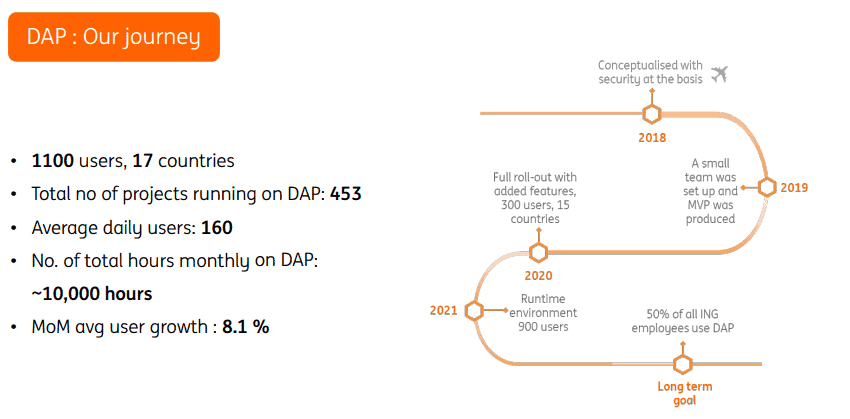
In 2013, they conceptualized data platform. In 2018, ING introduced cloud native technologies to upgrade their infrastructure platform. Since then, more and more employees and departments turn to the platform, and by now, there are more than 400 projects on the data index platform.
They aim to meet all analytics needs in a highly secure, self-service platform that has the following features:
- Open source tool model
- Powerful computing
- Strict security and compliance measures
- One platform for all
- Both global and local
Challenges and Solutions
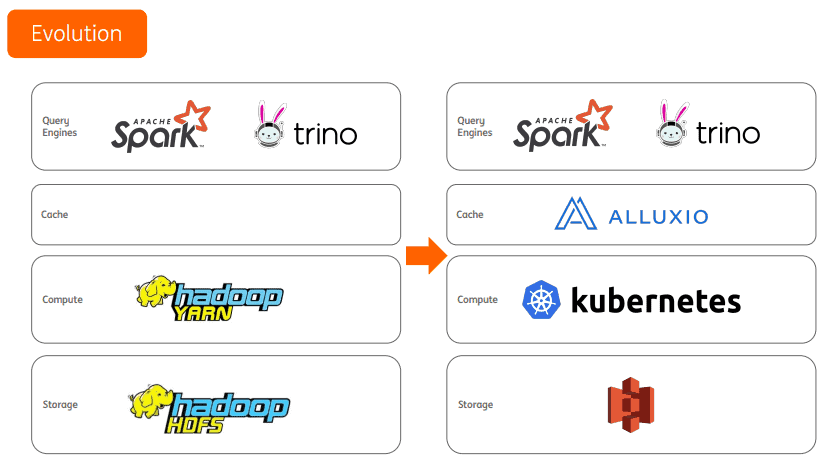
ING is shifting from Hadoop to Kubernetes. They met some challenges in job management and multi-framework support. For example:
- Job management
- Pod scheduling: Unaware of upper-layer applications.
- Lack of fine-grained lifecycle management
- Lack of dependencies of tasks and jobs
- Scheduling
- Lack of job-based scheduling, such as sorting, priority, preemption, fair scheduling, and resource reservation
- No advanced scheduling algorithms, such as those based on CPU topology, task topology, IO-awareness, and backfilling
- Lack of resource sharing among jobs, queues, and namespaces
- Multi-framework support
- Insufficient support for frameworks such as TensorFlow and PyTorch
- Complex management of each framework (such as resource planning and sharing)
Managing applications (stateless and even stateful ones) with Kubernetes would be a perfect choice, if Kubernetes is as user-friendly as Yarn in the scheduling and management of batch computing jobs. Yarn also provides limited support, for example, on TensorFlow and PyTorch. Therefore, ING looked for better solutions.
Kubernetes + Hadoop
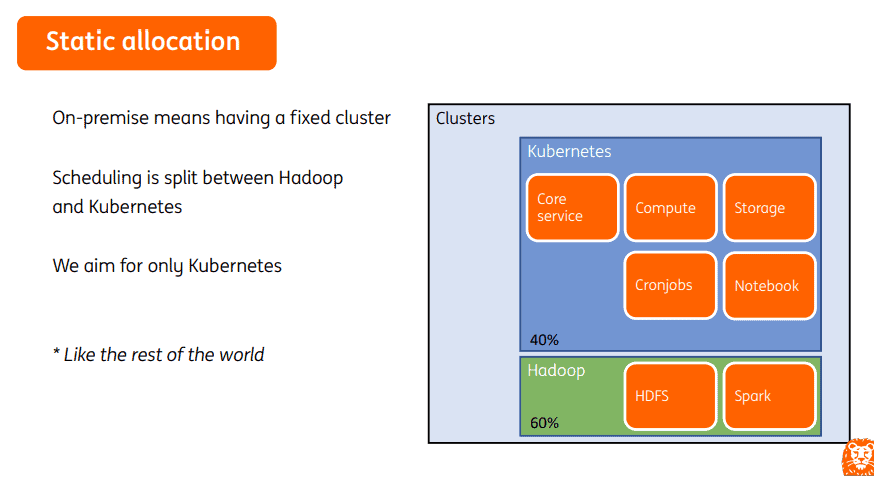
When managing clusters, ING once separated Hadoop and Kubernetes. They ran almost all Spark jobs in Hadoop clusters, and other tasks and algorithms in Kubernetes clusters. They want to run all the jobs in Kubernetes clusters to simplify management.

When Kubernetes and Yarn work together, Kubernetes and Hadoop resources are statically divided. During office hours, Hadoop applications and Kubernetes use their own resources. Spark tasks, when heavily pressured, cannot be allocated extra resources. At night, there are only batch processing tasks in clusters. All Kubernetes resources are idle but cannot be allocated to Hadoop. In this case, resources are not fully used.
Kubernetes with Volcano

When managing clusters with Kubernetes and scheduling Spark tasks with Volcano, resources do not need to be statically divided. Cluster resources can be dynamically re-allocated based on the priorities and resource pressure of pods, batch tasks, and interactive tasks, which greatly improves the overall utilization of cluster resources.
For example, during office hours, idle resources of common service applications can be used by batch and interactive applications temporarily. In holidays or nights, batch applications can use all cluster resources for data computing.

Volcano is a batch scheduling engine developed for Kubernetes with the following capabilities:
- Job queues with weighted priority
- Able to commit above queue limits if the cluster has spare capacity
- Able to preempt pods when more pods come in
- Configurable strategies to deal with competing workloads
- Compatible with Yarn scheduling
Volcano supplements Kubernetes in batch scheduling. Since Apache Spark 3.3, Volcano has become the default batch scheduler of Spark on Kubernetes, making it easier to install and use.
Highlighted Features
Redundancy and Local Affinity
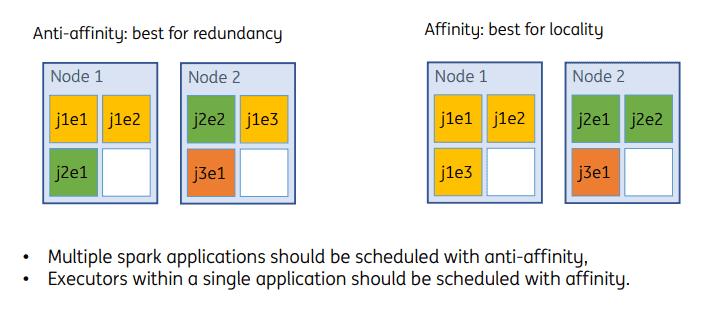
Volcano retains the affinity and anti-affinity policies for pods in Kubernetes, and adds those for tasks.
Dominant Resource Fairness (DRF)
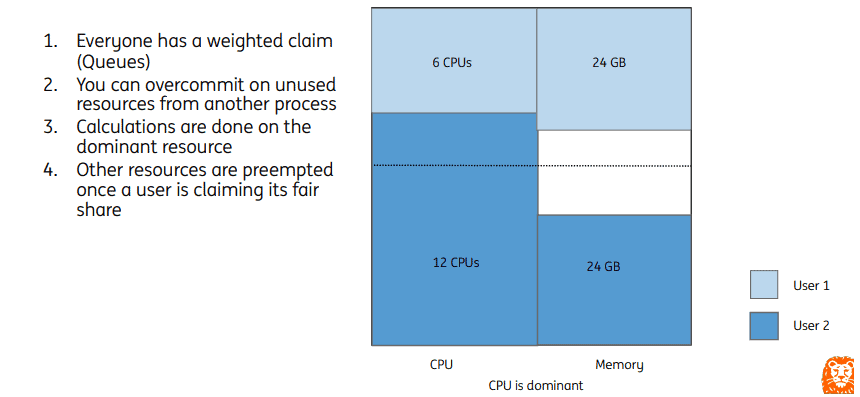
The idea of DRF is that in a multi-resource environment, resource allocation should be determined by the dominant share of an entity (user or queue). The volcano-scheduler observes the dominant resource requested by each job and uses it as a measure of cluster resource usage. Based on this dominant resource, the volcano-scheduler calculates the share of the job. The job with a lower share has a higher scheduling priority.
For example, a cluster has 18 CPUs and 72 GB memory in total. User1 and User2 are each allocated one queue. Any submitted job will get its scheduling priority based on the dominant resource.
- For User1, the CPU share is 0.33 (6/18), the memory share is 0.33 (24/72), and the final share is 0.33.
- For User2, the CPU share is 0.67 (12/18), the memory share is 0.33 (24/72), and the final share is 0.67.
Under a DRF policy, the job with a lower share will be first scheduled, that is, the job committed by User1.
Queue resources in a cluster can be divided by configuring weights. However, overcommitted tasks in a queue can use the idle resources in other queues. In this example, after using up the CPUs of its own queue, User2 can use the idle CPUs of User1. When User1 commits a new task, it triggers resource preemption and reclaims the resources occupied by other queues.
Resource Reservation
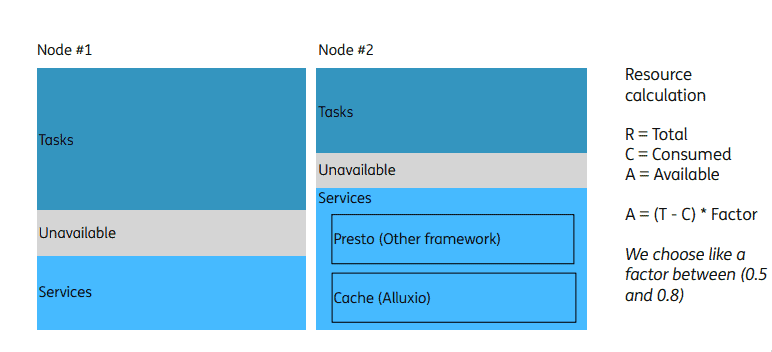
Batch computing tasks and other services may preempt resources and cause conflicts. Assume there are two available nodes in a cluster and we need to deploy a unified service layer in the cluster to provide services externally, such as Presto or cache services like Alluxio, batch computing tasks may have already taken all resources and we can’t deploy or upgrade that service layer. Therefore, ING’s platform now allows users to reserve some resources for other services.
DRF Dashboard

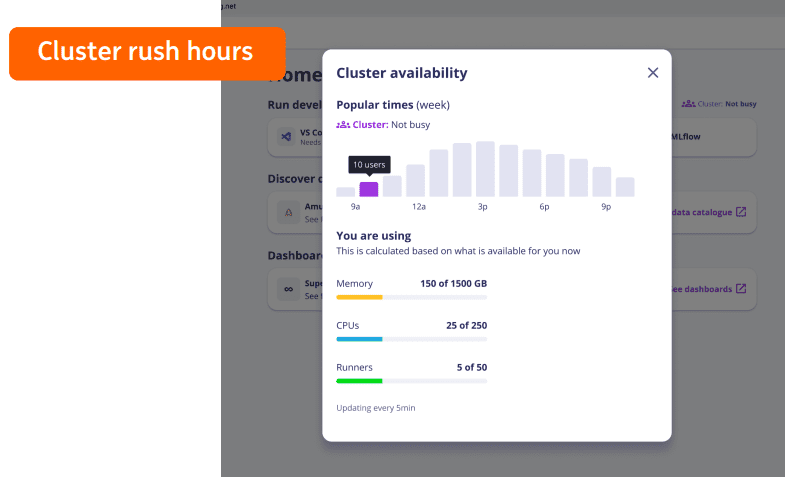
ING built a DRF scheduling dashboard based on the monitoring data from Volcano to obtain scheduling data at different layers. In the service cluster, ING stores the tasks of interactive users in one queue, and the computing tasks of all key projects running on the data platform in another queue. ING can take certain resources from other queues to the key project queue, but that won’t do any good to the tasks of interactive users.
ING is considering displaying the peak hours of cluster use to provide users with more information. With this, users can decide when to start their tasks based on the cluster resource readiness, improving computing performance without complex configurations in the background.
Summary
Volcano abstracts batch task scheduling, allowing Kubernetes to better serve ING in task scheduling. ING will contribute their developed functions to the community, such as the DRF dashboard, idle resource reservation on each node, auto queue management, new Prometheus monitoring metrics, Grafana dashboard updates, kube-state-metrics update, and cluster role restrictions.
More info about Volcano:
GitHub: https://github.com/volcano-sh/volcano
Volcano website: https://volcano.sh/en
Weekly meeting: https://zoom.us/j/91804791393