
Guest post originally published on the InfluxData blog by Charles Mahler
Cloud native and microservice architectures bring many advantages in terms of performance, scalability, and reliability, but one thing they can also bring is complexity. Having requests move between services can make debugging much more challenging and many of the past rules for monitoring applications don’t work well. This is made even more difficult by the fact that cloud services are inherently ephemeral, with containers constantly being spun up and spun down.
As a result we see the move towards observability, which allows developers to not just know that their application has a problem but gives enough visibility into their software that they can figure out why something went wrong and how to prevent it in the future.
One tool that makes collecting observability data like metrics, logs, and traces easier is OpenTelemetry. In this article you will learn about OpenTelemetry, some of the problems it helps solve, and about the surrounding observability ecosystem.
What is OpenTelemetry?
OpenTelemetry is an open source collection of various tools, APIs, SDKs, and specifications with the purpose of standardizing how to model and collect telemetry data. OpenTelemetry came into being from the merger of the OpenCensus project (sponsored by Google) and the OpenTracing project (sponsored by CNCF) and has backing from many of the biggest tech companies in the world. Some of the companies actively contributing to the project are Microsoft, Red Hat, Google, Amazon, Shopify, Datadog, and Facebook.
OpenTelemetry is currently the 2nd most active CNCF project behind Kubernetes dating back to last year and has over 1000 contributors according to the CNCF Velocity data tracker.
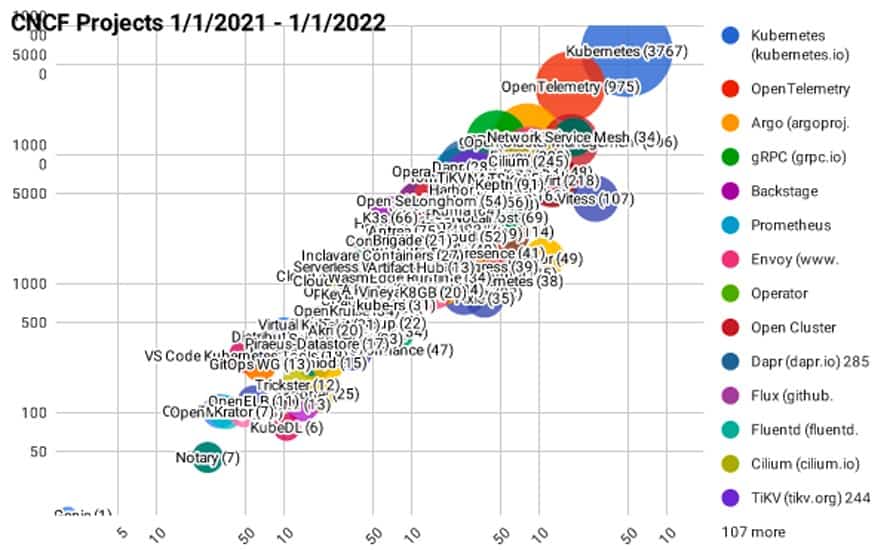
Why use OpenTelemetry?
Choosing whether to include a tool in your application involves many factors, but two of the most important are:
- Whether the project provides real value to your application
- The activity and ecosystem of a project compared to alternative solutions
The first factor involves determining whether the effort to integrate a project with your software or any additional complexity created by using the project is worth the value it creates. In the case of observability and general application monitoring it is almost mandatory for creating reliable software, so any tool that can make collecting observability data like metrics, logs, and traces easier is essential.
Once you’ve determined that a type of tool is worth using, it comes down to determining which option is best among the available solutions. Prior to OpenTelemetry the options available to developers for collecting observability data were either vendor provided, which resulted in lock-in or required combining multiple different open source projects to collect metrics, logs, and traces.
OpenTelemetry solves both of these problems, first by being open source and decoupling collection from storage so you have total control over what happens with your data. The second problem is solved by OpenTelemetry providing specifications and implementations for all types of observability data, so implementation is streamlined and simplified.
An additional benefit of choosing OpenTelemetry over potential alternatives is the ecosystem and community. As mentioned before, OpenTelemetry is now one of the most active CNCF projects and has many major tech companies adopting and contributing to the project. This means you don’t have to worry about the long-term status of the project and can know that there will be continuous improvements and new features added over time.
OpenTelemetry use cases
The data collected by OpenTelemetry has a number of different use cases. Here are a few of them:
- Software monitoring – The most obvious use for observability data is to monitor your software and to make sure everything is working correctly, if not having access to data from all levels of the application makes it easier to debug and resolve issues.
- Optimization – Observability data makes it easier to identify bottlenecks and other areas that are affecting the performance of your application. Over time this data can be used to make your app more efficient and save on infrastructure costs.
- Security – Observability data can be used for real-time security monitoring and used to detect anomalies and other activity that could signify a security breach.
- Developer productivity – Using observability data as part of a deployment pipeline allows software engineers to push new features faster and with more confidence.
What to do with your observability data
OpenTelemetry handles collecting and transmitting your data, but to get real value out of your data you will need other tools. Let’s take a look at a few ways you can use your data and some of the options available.
Data storage
The first decision you need to make with regards to your observability data is how you are going to store it. While any database can be used for storage, observability data is somewhat unique in its properties due to being time series data. More general-purpose databases aren’t optimized for the common types of queries and the general lifecycle of time series data.
If you are looking to optimize the scalability, query performance, and minimize costs of storing your data it might be worth considering a time series database (TSDB). Here are a few of the advantages of using a time series database for storing your OpenTelemetry data:
- Scalability – Time series databases are optimized for handling large numbers of writes and many have out-of-the-box functionality for things like replication and sharding.
- Performance – TSDBs are optimized for the unique types of queries that are common for analyzing time series data. These queries are difficult for standard databases to handle because they come from both ends of the spectrum in terms of OLTP vs. OLAP. For example, a developer would want to routinely do a very broad query across all running servers to get their current metrics during a time period and then if something was wrong with a particular server, analyze the data only for that specific server. A column database would struggle with the first query; a row-based database would struggle with the second. A time series database is designed to handle both queries.
- Developer Productivity – TSDBs have a number of features built-in that are useful for working with observability data. Instead of having to spend developer time building these features onto a general purpose database, you get that out of the box. These include things like downsampling, retention policies, and query languages designed for working with time series data.
- Cost savings – As a result of the above features, using a time series database will save you money in terms of hardware due to efficiency gains and by allowing your developers to focus on building features core to your product’s value for your users.
In addition to time series databases, there are other options available for your observability that might be useful depending on your specific use case. If you need powerful full-text search capabilities for log analysis, a search database makes sense. If you want to analyze relationships between different services in your architecture, a graph database is optimized for that. The key thing to keep in mind is to balance the complexity of adding and managing a new data store to your application with the benefits it provides and determine whether the tradeoff is worth it.
Data Analysis
Once you have your observability data store, you are probably going to want to do something with it rather than just have it sit around. A logical first step is to build some dashboards for visualizing your data and monitoring it. Once you’ve done that, you can try analyzing your data and generating insights that might have previously been hidden or even try making forecasts and projections based on your data.
Automation
The next step after starting to collect data and perhaps running some basic analysis with some manual intervention is to start taking automated action based on your observability data. Using data collected by OpenTelemetry it’s possible to automate across all stages of your software development cycle. Tools like Argo and Flux can be used to build deployment pipelines with capabilities like canary testing, blue-green deployments, and automatic rollbacks. This allows your developers to push to production faster with the confidence that if anything goes wrong, you will know quickly due to data collected by OpenTelemetry and those changes can be reverted without affecting users. Once software is deployed, your telemetry data can be used to make your software more efficient by taking advantage of cloud flexibility to scale services up and down based on observed traffic trends and utilization rates.
Conclusion
Observability continues to gain mindshare and adoption with developers, and OpenTelemetry has the potential to act as the glue that ties together the entire observability ecosystem of vendors and open source projects. As a developer, it is worthwhile to become at least somewhat familiar with OpenTelemetry as a result.