
Guest post by Shahar Azulay, groundcover’s CEO and Co-Founder
It’s a place all Kubernetes admins have likely been: They have a container that fails to start, and they simply can’t figure out why that is. They may have a container exit code, but that information alone isn’t always enough to figure out the root cause of why a container didn’t start as expected. Plus, because Kubernetes doesn’t automatically notify admins when containers fail to start or terminate unexpectedly, it’s not always immediately clear that there is a problem.
Fortunately, it is possible to track container state continuously, and to get specific information about failed starts and terminations. But you need to know where to look – and the location is less obvious than you may think. In this article, we explain our approach to tracking container restarts and terminations in K8s, and we point to sample code that you can use to implement a continuous “container restart watcher.”
Container and Pod status in Kubernetes
We don’t want to get ahead of ourselves here, so let’s start by explaining the basics of how containers and Pods run in Kubernetes. When you want to deploy an application in Kubernetes, you deploy a Pod. The Pod hosts one or more containers.
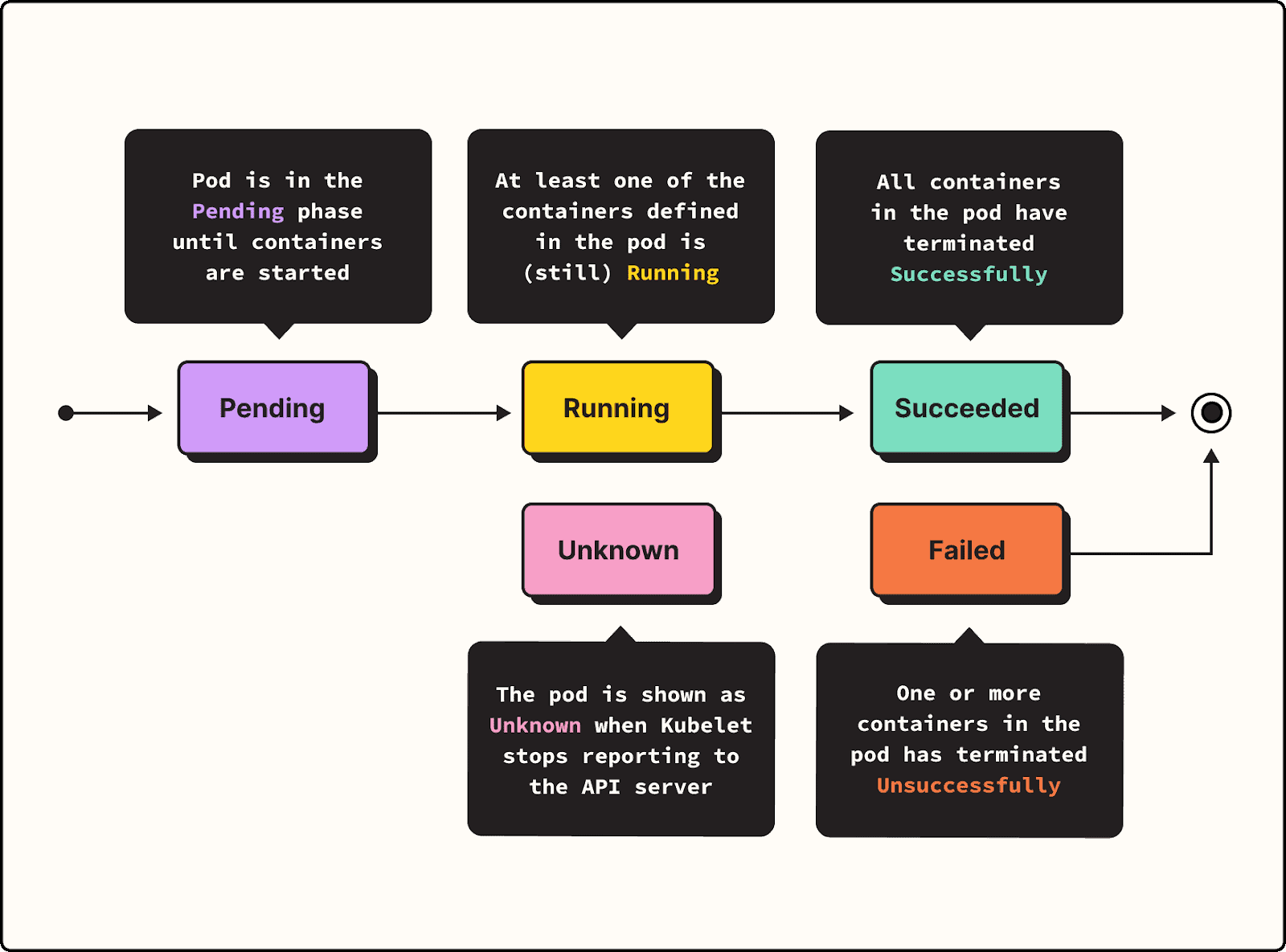
Ideally, when you tell Kubernetes to start the Pod, all of the containers will start up successfully. In that case, what you end up with is a Pod in what Kubernetes calls the Succeeded state. But if one or more of your containers doesn’t start for some reason, the Pod enters the Failed state. In that event, your application won’t run because the Pod that it depends on has failed.
Tracking why Pods fail
There are many reasons why Pods could end up in the Failed state due to unsuccessful container termination. Common root causes include failure to pull the container image because it’s unavailable, bugs in application code or misconfigurations in the Pod’s YAML. But simply knowing that a Pod has failed doesn’t mean you’ll know the cause of the failure. Unless you dig deeper, the only thing that you’ll know is that it is in the Failed state.
Container exit codes
One way to dig deeper is to look at container exit codes. Container exit codes are numeric codes that give a nominal reason for why a container stopped running. You can get the exit code for containers in a Pod by running:
kubectl get pod termination-demoUnfortunately, container exit codes don’t always provide usable information. The reason why is that exit codes are in some cases determined by the application running in the container, which may use different exit codes than your container runtime. So you may, for instance, get a 143 exit code, which in theory denotes that the container got a SIGTERM. But if that code was generated by your application, 143 may mean something else entirely.
The point here is that, while container exit codes are sometimes useful, they shouldn’t be your main source of insight into failed containers.
The Kubernetes API
You might be tempted to turn to the Kubernetes API to investigate container terminations. The API lets track certain types of “events” associated with changes to cluster state. Unfortunately, because the API doesn’t currently include an event type for container restarts or terminations, it’s not very useful for this purpose.
The ContainerStatus struct
The best way to get information on container restarts is to look at the ContainerStatus struct, which is contained in the PodSpec for the associated Pod.
ContainerStatus looks like this:
// k8s.io/api/core/v1/types.go
type ContainerStatus struct {
Name string
State ContainerState
LastTerminationState ContainerState
Ready bool
RestartCount int32
Image string
ImageID string
ContainerID string
Started *bool
}Of interest for the purposes of this article is the LastTerminationState field, which will be empty if the container is still running successfully. The field is overwritten whenever the container restarts. So, by using the cache.ListWatch to watch for Pod update events, it becomes possible to compare the ContainerStatus structs for the new and old Pods and determine whether a container has restarted. In this way, you can identify container restart events as they happen.
As for figuring out why events happen, you can use the ContainerStateTerminated struct, which looks like this:
// k8s.io/api/core/v1/types.go
type ContainerStateTerminated struct {
// Exit status from the last termination of the container
ExitCode int32
// Signal from the last termination of the container
Signal int32
// (brief) reason from the last termination of the container
Reason string
// Message regarding the last termination of the container
Message string
// Time at which previous execution of the container started
StartedAt metav1.Time
// Time at which the container last terminated
FinishedAt metav1.Time
// Container's ID in the format '<type>://<container_id>'
ContainerID string
}This struct exposes everything you need to determine why a container restarted, independently of exit codes. Using this struct, at groundcover we developed a tool that watches and logs container restart events in Kubernetes. You’re welcome to check it out on GitHub.
Real-time Kubernetes container restart monitoring
The approach we’ve described above makes it possible to get specific information about container restarts and terminations as soon as they happen. It’s one way that K8s admins can stay on top of what can otherwise be a frustrating and vexing issue – containers that don’t run as expected, for reasons that are hard to sort out by looking at container exit codes or Kubernetes events.