

Guest post originally published on G-research’s blog by Jamie Poole, Compute Platform Engineering Manager at G-research
Over the last couple of years we have been migrating more and more of our workloads to containers on Linux. One particular style of workload that is very important to us is run-to-completion batch jobs. Much of our business uses large compute grids to perform distributed data science and numerical processing – looking for patterns in large, noisy real-world datasets. Until recently we had mainly been doing this using HTCondor running on Windows.
Migrating to Linux and containers, we had the opportunity to reassess how we wanted to go about this. We experimented with running containerised jobs on Condor on Linux, but after a trip to KubeCon Barcelona and talking with some other research-focussed organisations, we felt that there was an opportunity to do things better using Kubernetes. We already run many of our services on Kubernetes, so having a single logical compute platform with all the operational and functional benefits Kubernetes brings was attractive.
It was clear that vanilla Kubernetes was not able to cater for our use case. We have a large, fixed-pool of on-prem compute, and one of the advantages of the Condor model is that you can submit many more jobs than your infrastructure can process at once and the excess is queued externally and prioritised using a fair-share system. We knew already that Kubernetes was the best-of-breed for container orchestration but lacked the ability to queue jobs or schedule them fairly when over-provisioned. If we could enable these extra features, might we be able to use Kubernetes for our batch job infrastructure too, and give us a single logical platform for all our compute?
We started an internal experiment, which we named Armada. We had some key architectural principles we wanted to adhere to:
- Write some software to add queuing and fair share, without needing to alter Kubernetes itself. Leave Kubernetes to do the hard work of node-scheduling and container lifecycle management.
- Support multiple clusters, such that we can scale past the limit of a single Kubernetes cluster and also gain the operational advantages of multiple clusters. Our aim is to run a fleet of thousands of servers.
- Use a pull-based model for obtaining jobs, to allow us to to scale up easily
Additionally, we wanted to make it open source from the start. We have been benefiting more and more from open source technologies, not least Kubernetes itself. We felt that if we could produce something that would solve a problem for us it would most likely be useful for others, and it could be a good opportunity to give something back to the ecosystem from which we are benefitting. We haven’t had much experience of building greenfield open source projects so simply started on GitHub to ensure that we would be able to share it.
We quickly produced a proof-of-concept and had an application that we could use in AWS to prove that Kubernetes was up to the job of running many tens of thousands of jobs across multiple clusters with hundreds of nodes each. Crucially we were able to demonstrate that with no special tuning Kubernetes was more than capable of handling thousands of containers starting and stopping, as long as we handle the queuing externally.
So how does it work?
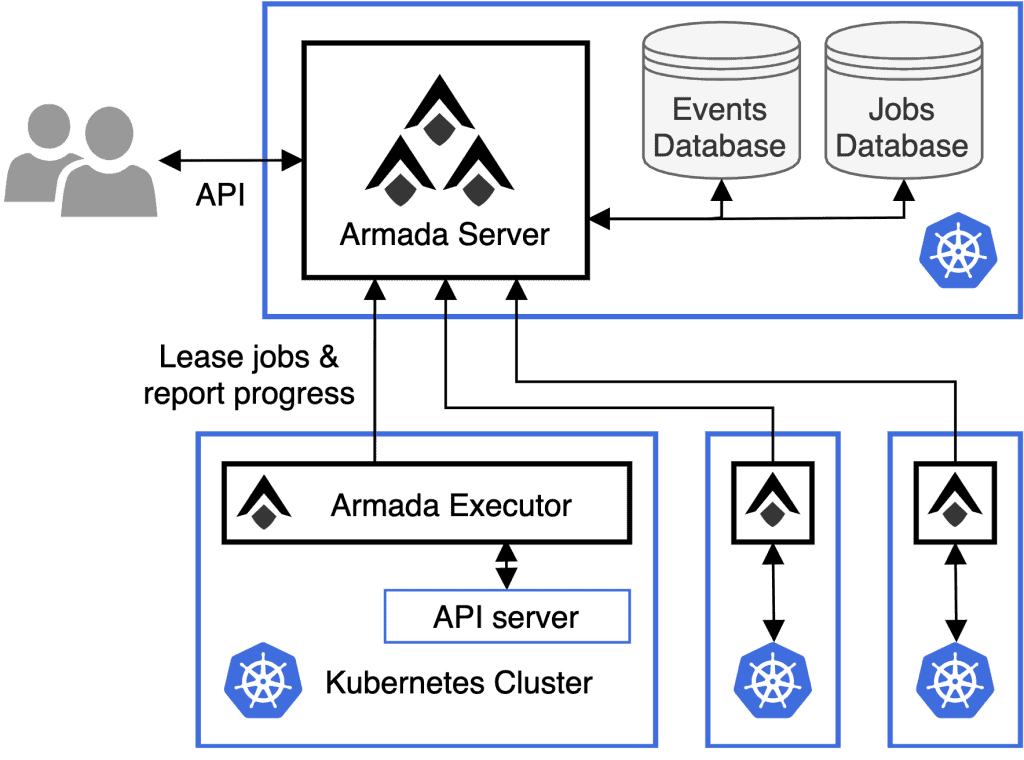
The Armada design is simple. There is a central server component which stores queues of jobs to be run for different users or projects. It is responsible for maintaining the state of the overall system. It has an API allowing clients to submit jobs in the form of Kubernetes pod specs, as well as the ability to watch progress of jobs or cancel them.
Below this, we have an executor component which can be deployed into any given Kubernetes cluster, permissioned to be able to inspect the cluster and discover how much resource (e.g. CPU / GPU / memory) is available. It regularly contacts the server component and leases jobs to be run, and then creates pods locally, reporting progress back to the server component. When jobs complete, pods are cleaned up and space becomes available for the next.
Scaling can be performed horizontally in two dimensions. We can increase nodes in dedicated executor clusters, as well as adding more executor clusters on demand. Because of the pull-based approach of leasing jobs, we can add or remove executor clusters easily without making any configuration changes.
What have we learned?
From our experience, we have validated our assumption that Kubernetes can be used as the compute substrate for our compute farms. It hasn’t been completely smooth sailing, and we have run into some interesting edge cases and issues along the way. Some of this is simply the migration to Linux and containers and inevitably discovering the bits of our code that were unwittingly dependent on the Windows operating system and its ecosystem. Others were issues with Kubernetes itself, which we found typically get picked up and resolved for us by the community (e.g. https://github.com/kubernetes/kubernetes/pull/90530 – fixing cluster over-allocation when using the static CPU manager). This sort of thing is validation in itself – by using Kubernetes we inherit all of the community support and momentum of the project.
Next steps
Our environments are now growing, and as our batch workloads are migrating to Linux we have a reliable and scalable platform to run them on. Kubernetes in G-Research is provisioned on OpenStack, and we are able to re-provision our existing hardware to add it into the OpenStack compute pool to be consumed by Kubernetes. It’s exciting to see the environment increase in scale as more workloads migrate across. Now that we have validated the operational stability of the platform, we want to focus on usability. We plan a simple UI for users to be able to more easily visualise their jobs flowing through the system, as well as making it easier for administrators to understand the system as a whole. We are working on improving our automation for deployment of the platform, and as much as possible make the system ‘just work’ as soon as it is deployed.
We welcome you to have a look and try it out for yourself, any feedback is gratefully received: https://github.com/G-Research/armada
If you’d like to join our teams and work on cool projects with us, G-Research is always hiring capable developers in the UK and with our remote GR Open-Source group.