
Guest post originally published by Caleb Hailey, CEO at Sensu
This series is adapted from Sensu’s whitepaper on the top 7 APIs for cloud-native observability. Catch up on parts 1 and 2.
Welcome to part 3 of our series on Kubernetes APIs for observability! So far, we’ve covered Kubernetes metrics, Service, container, Pod, and Downward APIs. In this final installment, I’ll go over the Kubernetes Events API and API Watchers, wrapping up by reiterating the importance of visibility when performing any operation — and the clues to look out for that may indicate there are gaps in your observability strategy.
Kubernetes Events API
- First-class Kubernetes resource
- Resource state changes, errors, and other system messages
- As seen in kubectl describe output
In Kubernetes, events are a first-class resource. They give you information about what is happening inside a cluster or a given namespace, such as decisions made by the scheduler, or why some pods were evicted from the node.
If you already have a monitoring or observability solution in your Kubernetes environment, you might have seen data from this API, and you’ve definitely seen it if you’re troubleshooting deployments in Kubernetes. If you’ve ever used the kubectl describe pod command, you can see related events at the bottom of the output. That information is fetched from the Events API.
Like every other first-class resource, events have metadata and status information available to them. Events record state changes, errors, and other system messages for other resources. There are messages and attributes in these APIs that answer questions like, “What’s the reason for this failure?” or “Why did this break?” — which is exactly the sort of information we need to operate services on Kubernetes! Some simple examples of observability data you can obtain from the Events API includes ImagePullFailure, and CrashLoopBackOff events.
As with most APIs in Kubernetes, we can access Event API data using kubectl. You can use the kubectl get events command to request all events in the current namespace. One of the first things you might notice is that the Events API will return “Normal” and “Warning” events. Even at a small scale, the Normal event output can become overwhelming, because there are lots of normal events.
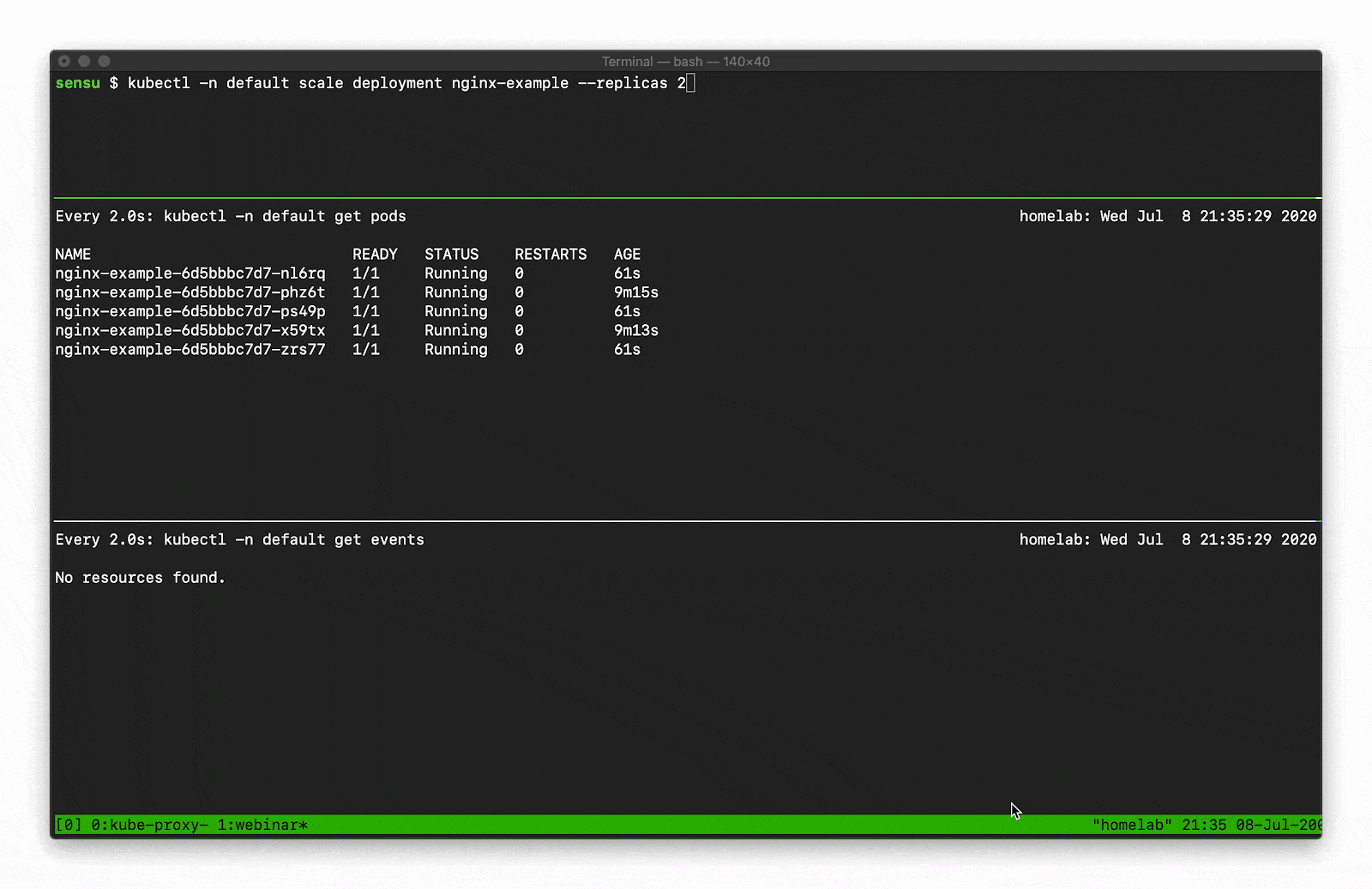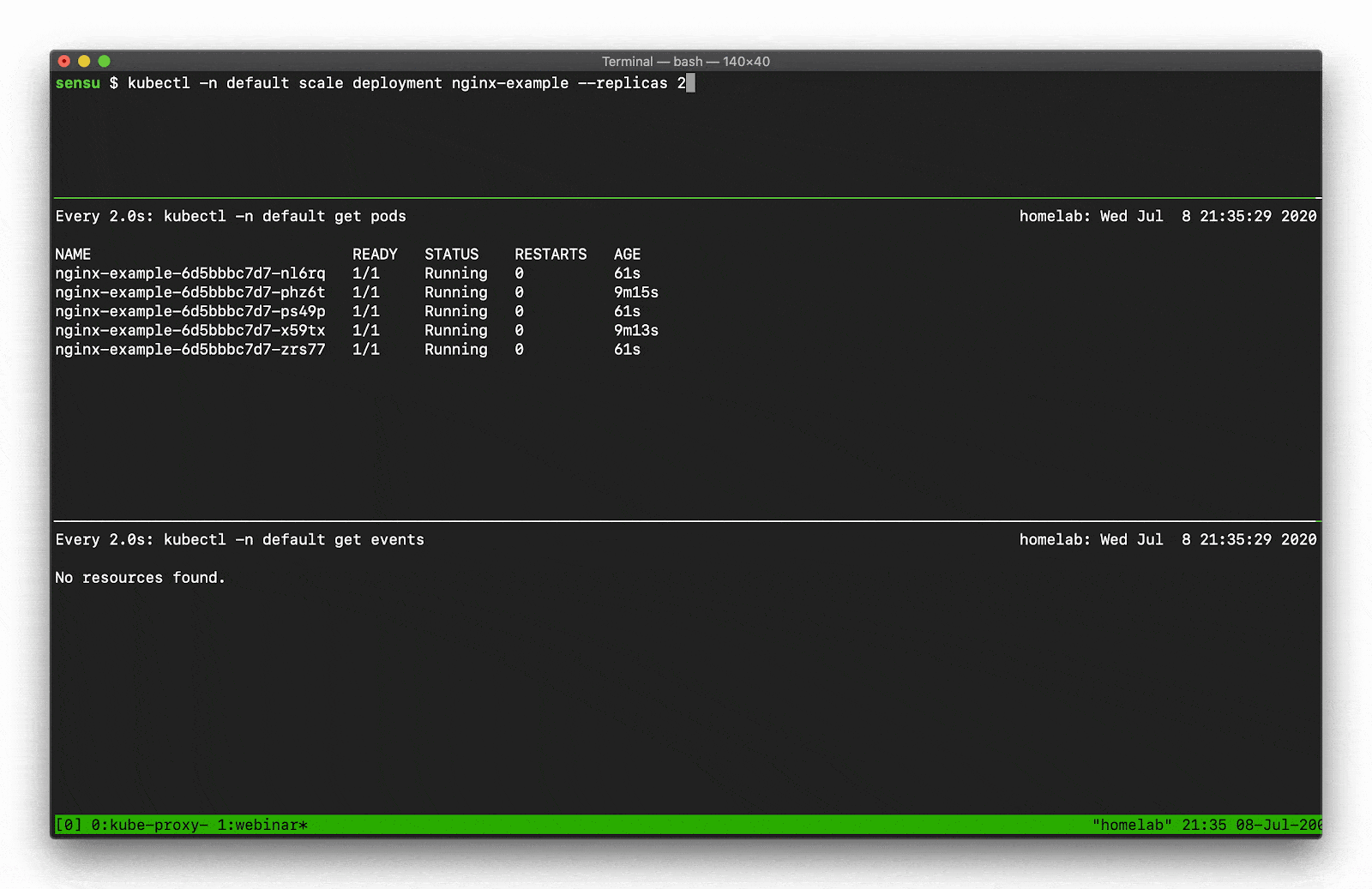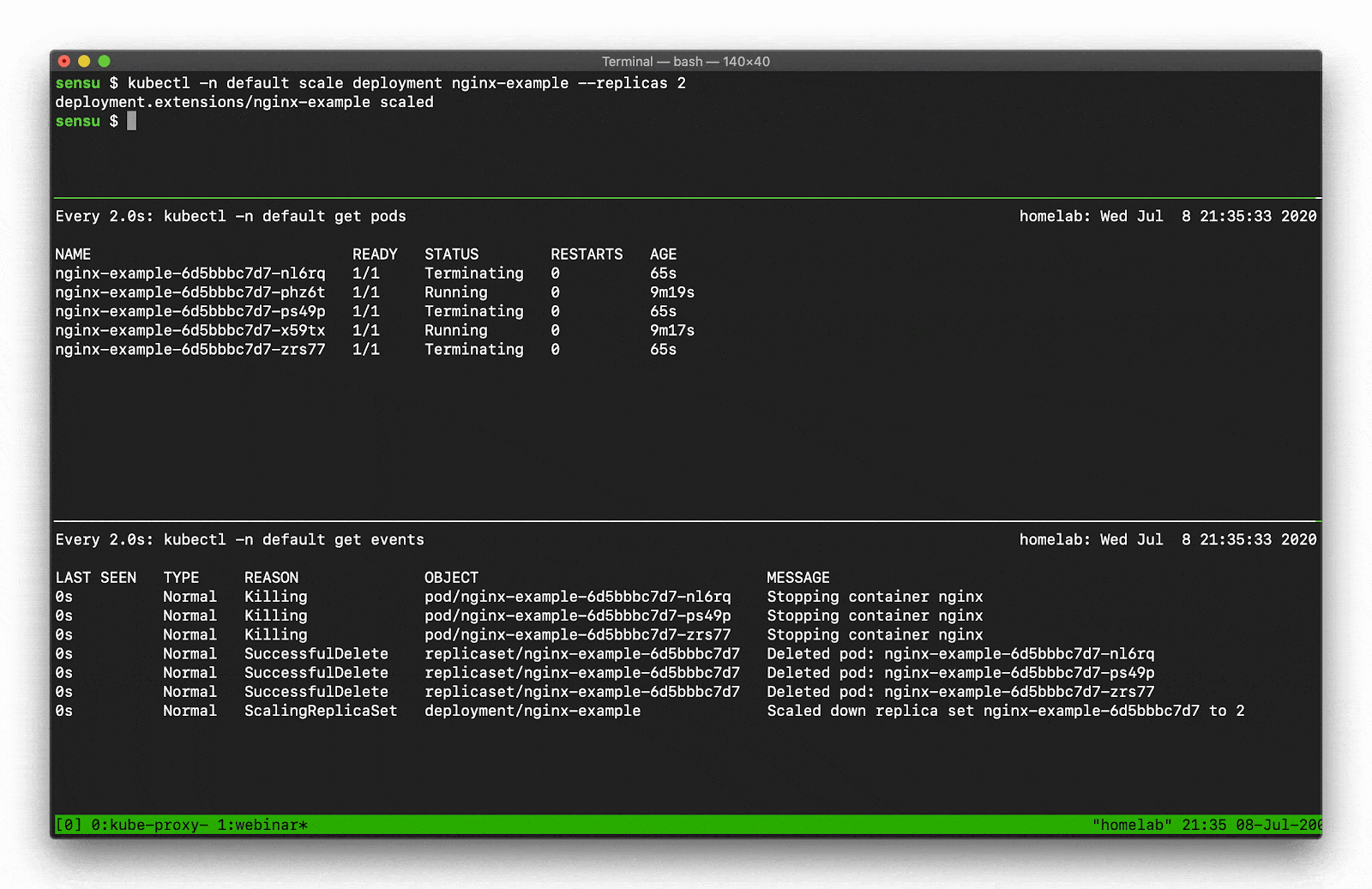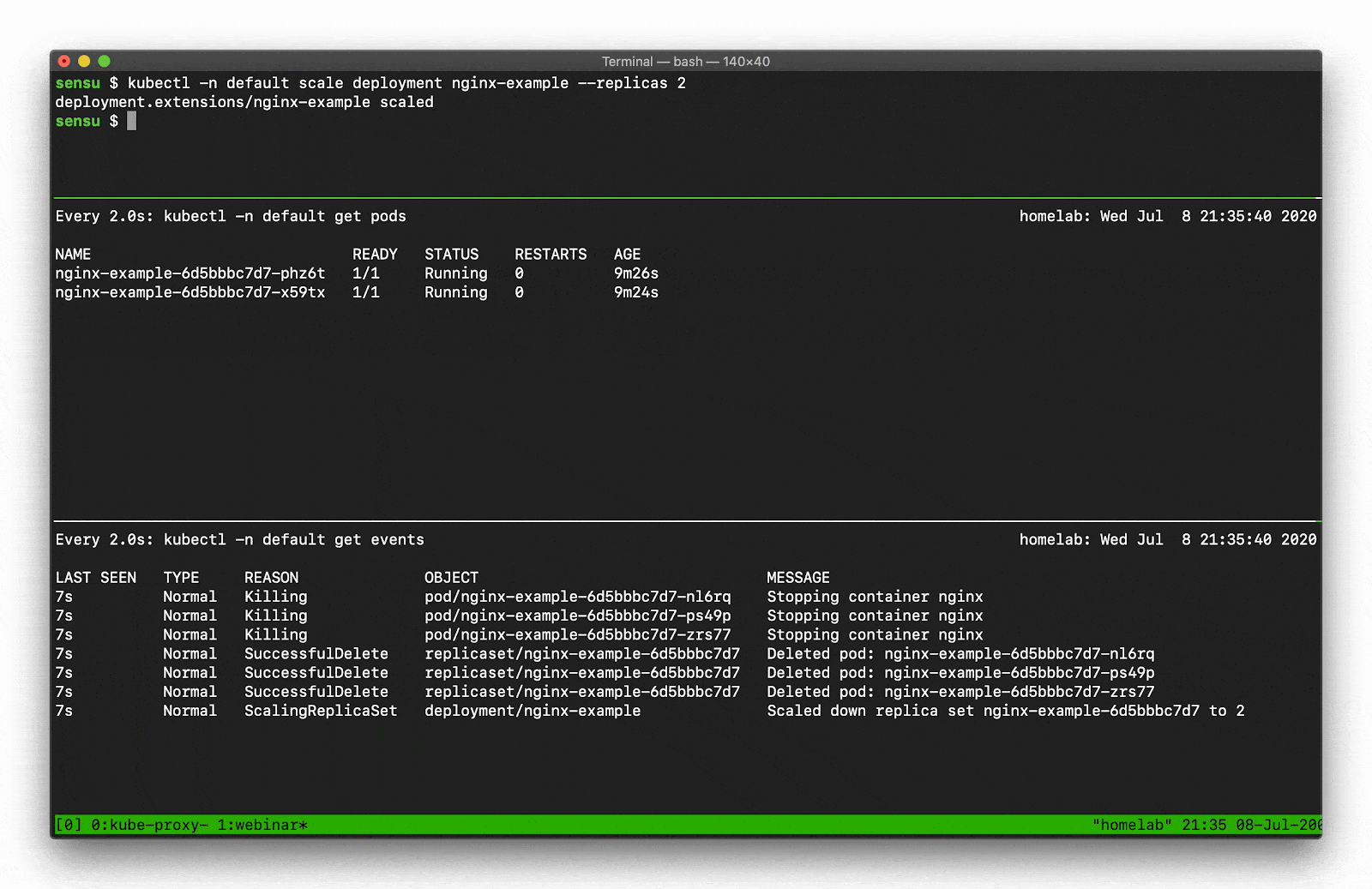
Let’s say, for example, you want to scale a Deployment. Recall that there are several moving parts, and a few degrees of separation between the controller (in this case, a Kubernetes Deployment) and the Pods. Kubernetes performs several actions in order to fulfill the request to scale a Deployment, including: creating or updating a ReplicaSet, scheduling/deciding which Kubelet each Pod should run on, verifying that the correct container images are cached/available on those Kubelets, and finally start the Container… oh, and Kubernetes will then update any related Services (e.g., load balancers) so that they will send traffic to the new Pods. That’s a lot of steps! Every one of these actions will produce a “Normal” event (if successful), so you’re going to see a LOT of data come out of the Events API. What can you do to make this useful? Well, you can filter the results with field selectors! Field selectors give you the ability to choose only Warning events, or only events from a certain resource type (e.g., “Deployment” or “Service”).
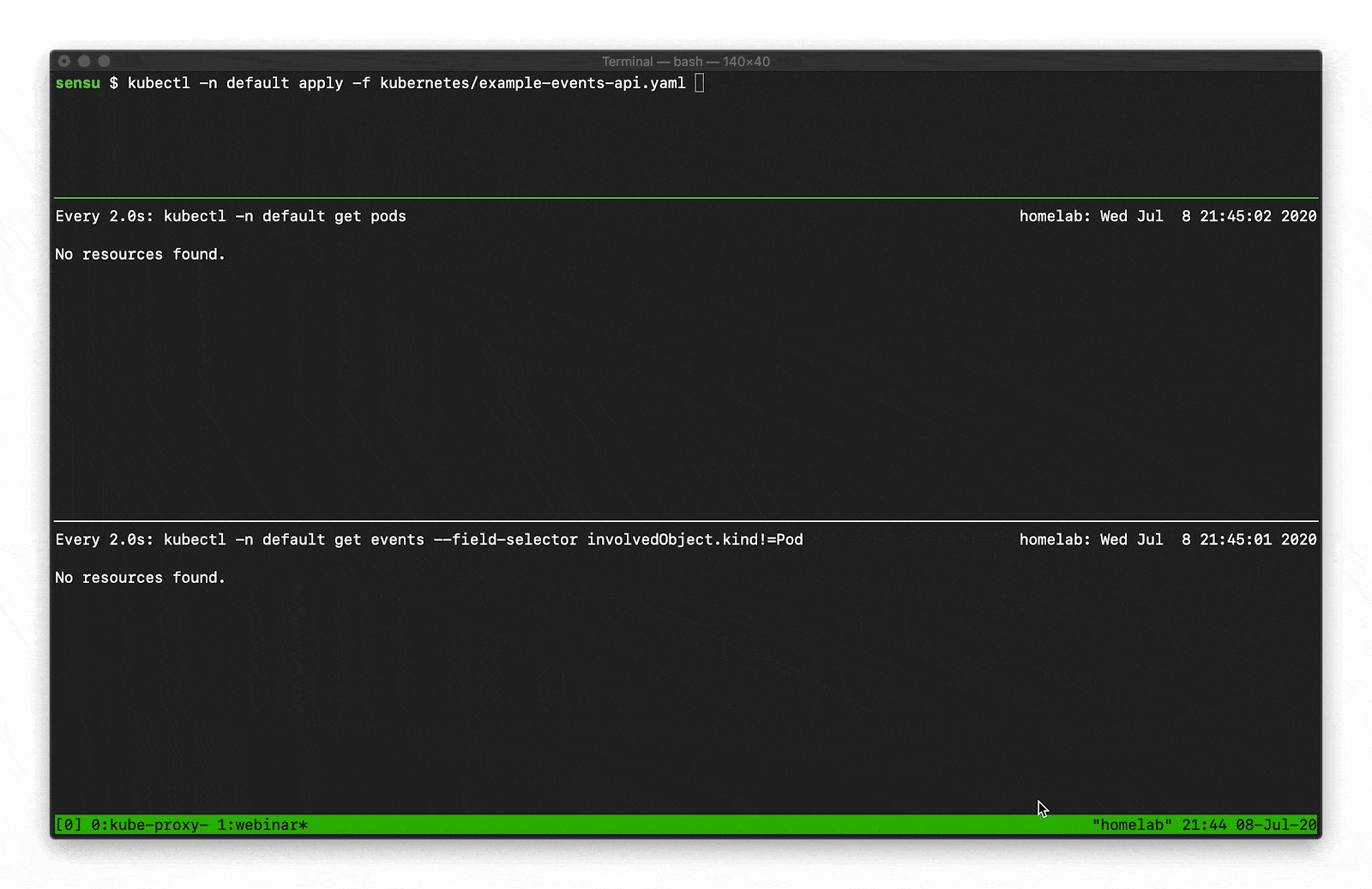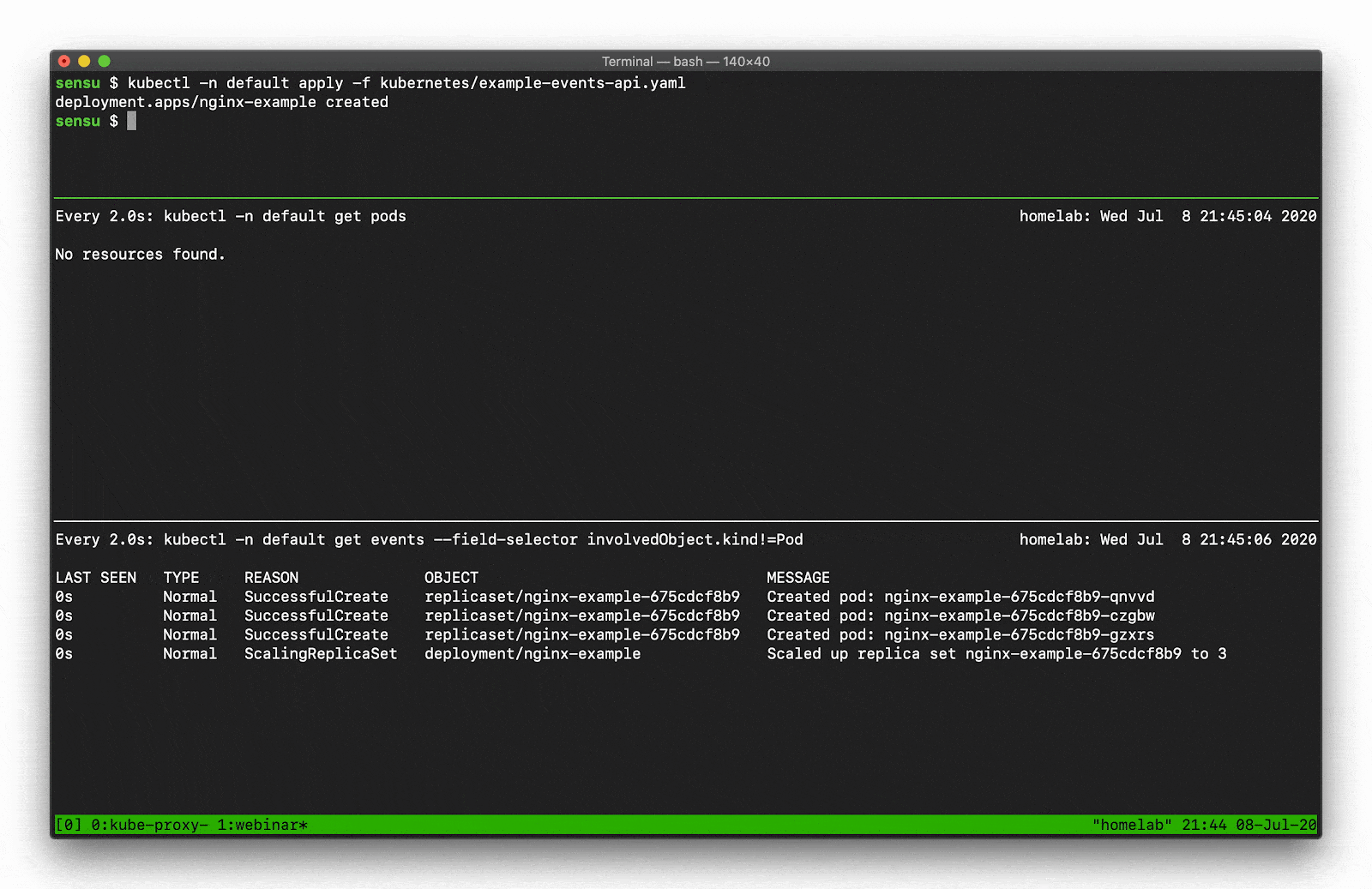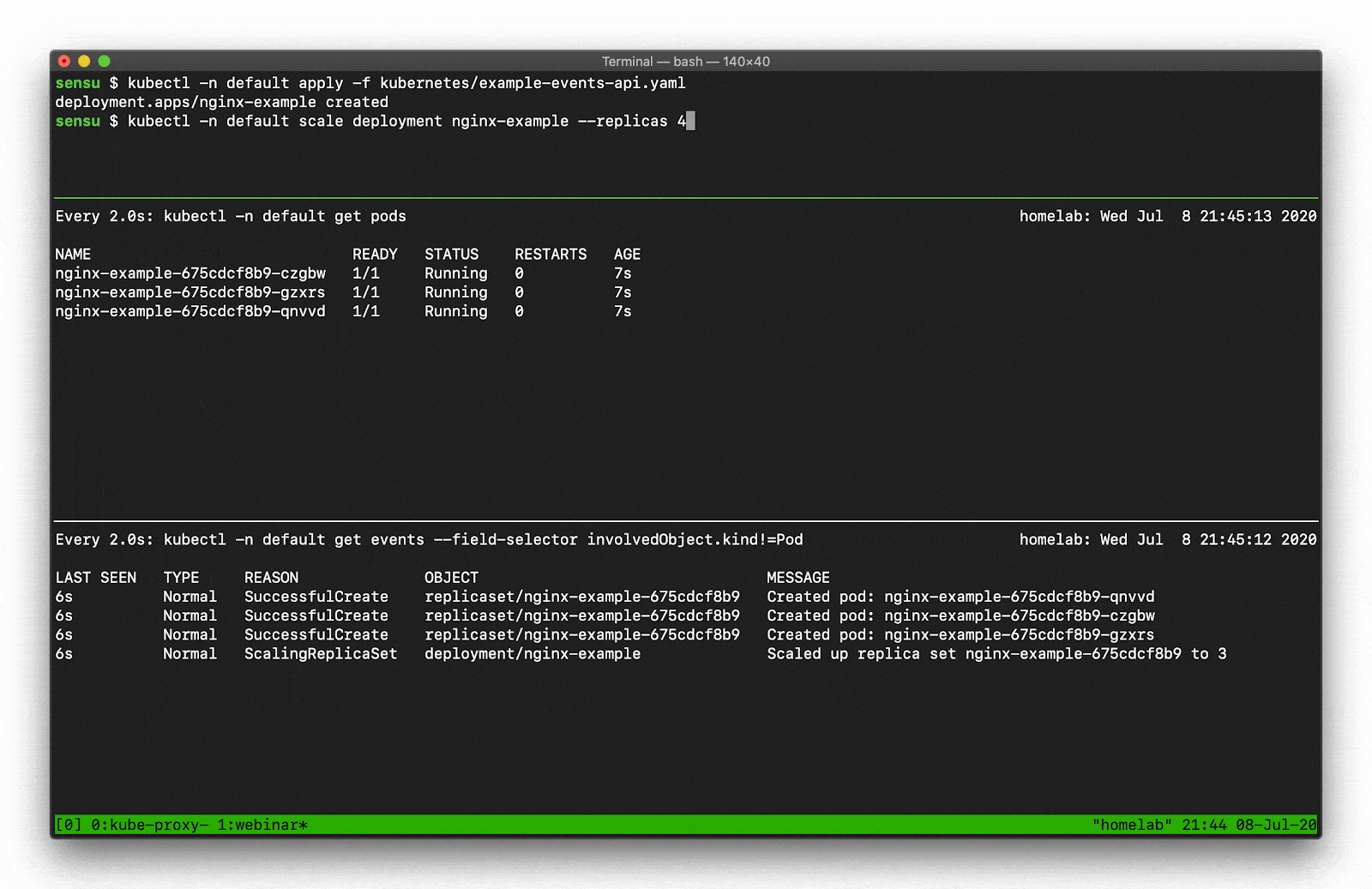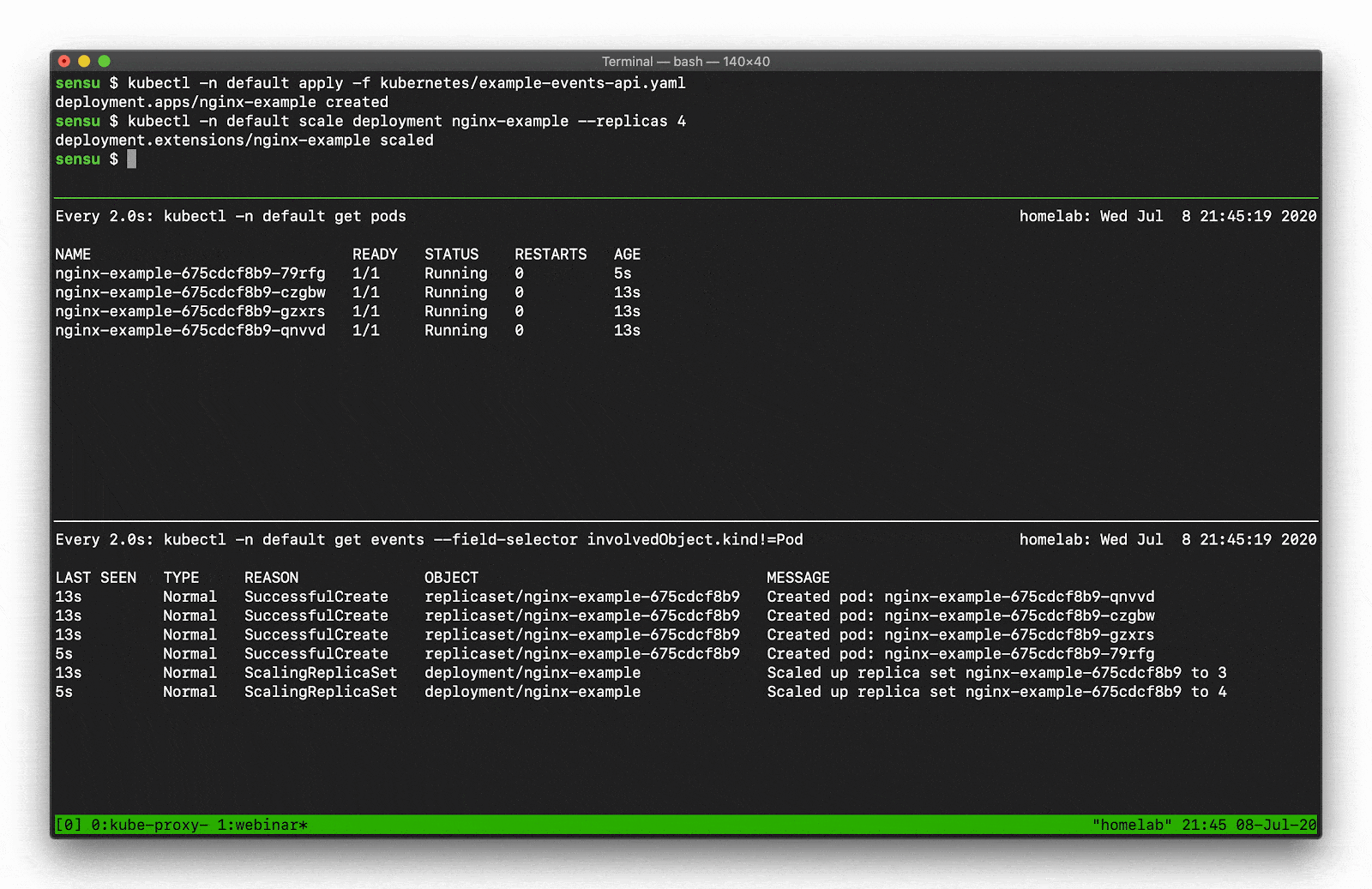
In this example you can see how managing a single Deployment resource (creating and scaling the deployment) results in several “Normal” events just for the underlying “Pod” resources (not including several additional events for the related Deployment and ReplicaSet resources).
Now let’s see what happens if we exclude the Normal events.
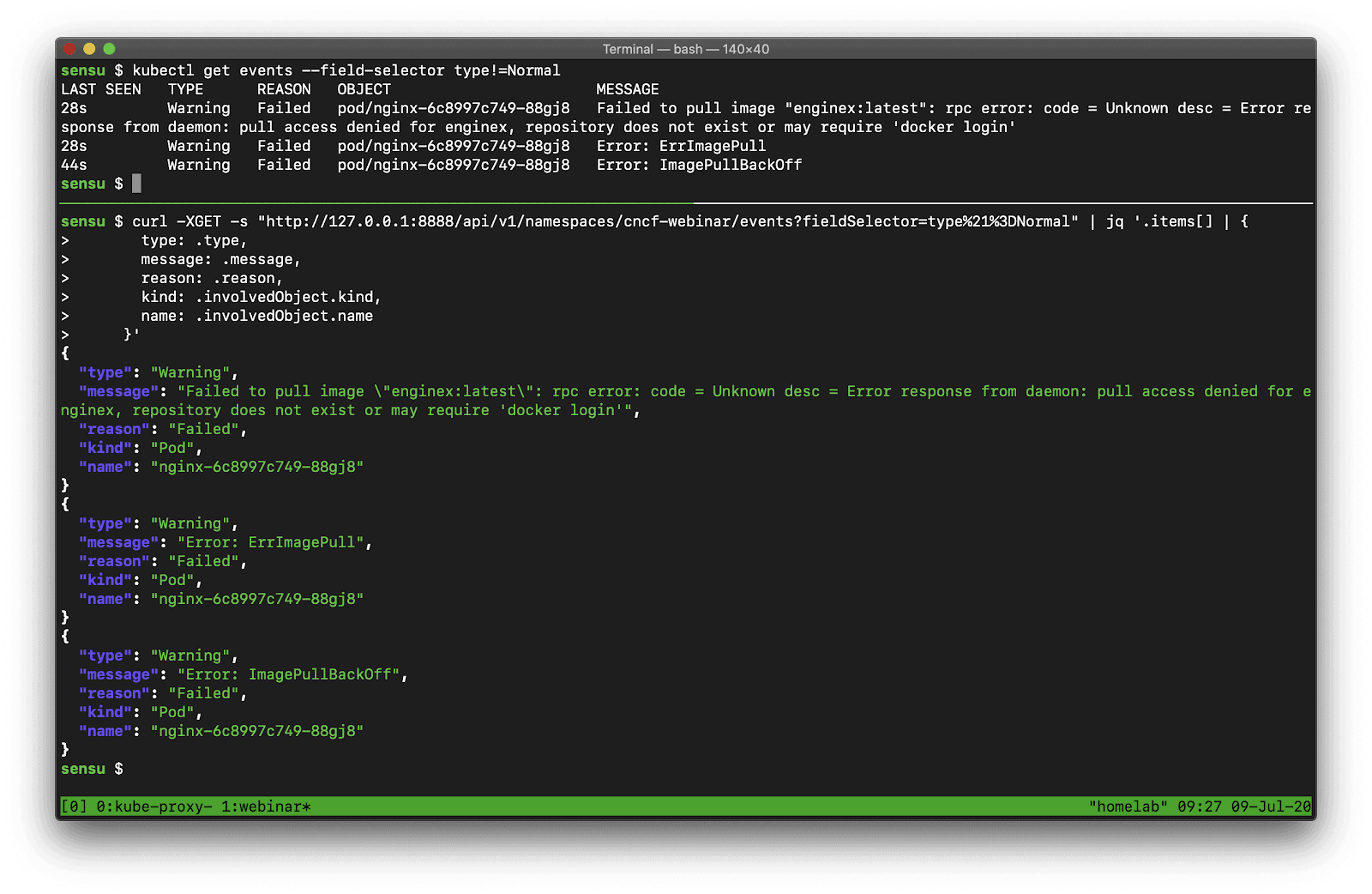
In this example I’m managing another Deployment resource, but this time my Deployment template is configured with an invalid Container image, so when I go to update that Deployment in Kubernetes it’s going to result in some errors.
Again, all of this event data we’ve shown coming out of the kubectl is just fetching from the Events API, so we can access all of this same information programmatically. Here’s an example to underscore this point:
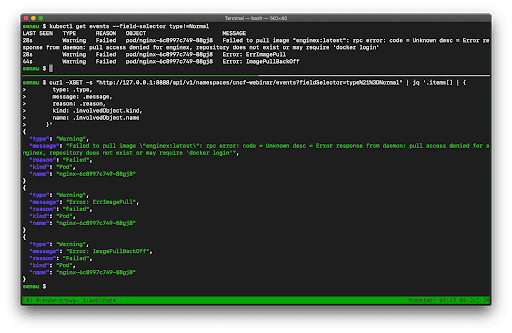
In this example, we are comparing the data we get from kubectl versus the exact same data from the Events API (via curl).
NOTE: Because the resources that come out of the API are extremely rich, there’s a lot of data here. I’m using jq to filter the API output and show the same properties I see from kubectl. Chris Short recommended during the presentation that once you learn all the kubectl commands you want to use, you should learn jq right after that – and I agree! It’s a Swiss Army knife for interacting with JSON APIs .
So that’s the Kubernetes Events API. It’s an incredibly rich resource full of critical data for monitoring and observability. If you aren’t already collecting Kubernetes Events as part of your cloud native observability strategy, it should be near the top of your priority list.
Kubernetes API Watchers
- Change notifications for all Kubernetes resources
- Supports resource instances and collections
- Returns ADDED, MODIFIED and DELETED change notifications
Our No. 1 Kubernetes API (in terms of the list we laid out in part 1) isn’t really an API at all. It’s a function of the Kubernetes API. Watchers are change notifications for any Kubernetes resource.
Watchers support resource instances and resource collections. When you run the kubectl get pods command or query the /pods API endpoint, you are fetching a Pod resource collection (i.e., a “list”).
GET /api/v1/namespaces/{namespace}/pods
GET /api/v1/watch/namespaces/{namespace}/pods?resourceVersion=123456789
GET /api/v1/watch/namespaces/{namespace}/pods/{name}?resourceVersion=123
These API endpoints return lists of Pods, which lists are themselves a resource type in Kubernetes. These lists are versioned, so we can record the version of that pod list and compare it with later versions to see what has changed over time.
Kubernetes API Watchers tell you if a resource has been ADDED, MODIFIED, or DELETED. And as we’ve explained above, the loosely coupled nature of Kubernetes results in a surprising number of resources changes that can be tracked using Watchers.
Note that you can use a Watcher on the Events API, combining these concepts to observe state changes. I illustrate this below:
In this example I’m using Kubernetes Watchers with the Pod API to observe changes to pod resources. When I delete a pod that is managed by a controller (in this case, a Kubernetes Deployment), the controller will automatically replace the deleted pod with a new one – once again resulting in more changes than you might expect. To learn more about Kubernetes pod state changes in the very excellent Kubernetes pod lifecycle documentation.
NOTE: If you haven’t played with the Kubernetes API before, you can get access to it with the kubectl proxy command. See the Kubernetes documentation for more information.
Kubernetes Watchers are a powerful tool for observing state changes in your Kubernetes clusters. And they’re not only useful for observing the building block resources (e.g., Service and Pods) – they can be combined with any Kubernetes API, including the Events API. If you’re experiencing a gap in your existing observability solution around resource changes that are impacting service reliability, Kubernetes Watchers might help fill that gap.
You can’t perform any operation without proper visibility
Just as we require actual visibility when we drive a car, or as surgeons rely on various tools to provide the necessary visibility into patient conditions when they perform operations on humans, so we as systems operators need to understand our systems if we want to run them efficiently and securely. We need a holistic view of everything that’s going on in Kubernetes — and there sure is a lot!
We set up tools to give us observations, but are these tools giving us all the rich context we need? If you’re seeing any gaps in your observability strategy, then I hope you learned something here that you can use to fill those gaps and tune your existing solution.
To the degree that you were already familiar with the kubectl commands I covered because you rely on them to diagnose issues with the workloads you’re running on Kubernetes, that might be a clue that there are gaps in your current Kubernetes observability strategy. The good news is, those kubectl commands are just talking to the underlying Kubernetes APIs, which means we can collect this data using our observability tools and spend more time improving our systems (instead of spelunking around Kubernetes because we’re missing context).