
Guest post from Connor Gorman, Sr. Software Engineer, StackRox
The maturation of the container ecosystem has coincided in parallel with the emergence of Kubernetes as the de facto orchestrator for running containerized applications. This new declarative and immutable workload design has paved the way for an entirely new operational model for detection and response.
Kubernetes’ rich set of workload metadata augments and elevates traditional detection approaches, like anomaly detection. In Kubernetes, anomaly detection consists of observing the normal behavior of an application to learn the typical behavior of the application, creating an activity baseline derived from the information during the learning stage, and then measuring future events against that baseline, including file reads and writes, network requests, and process executions. Anything that falls significantly outside of the normal baseline can be considered anomalous and should be investigated.
Anomaly Detection in a Traditional VM Infrastructure
The challenge in anomaly detection in a traditional Virtual Machine (VM) infrastructure is that it requires more expertise to tune and is much more prone to false positives. This is because of how VMs operate. VMs run a full operating system; and to amortize the cost of running the OS, several core applications are often running inside each one. In such an infrastructure, with a significantly broader spectrum of possible activity, getting anomaly detection right means creating complex models and algorithms that rely on machine learning. Your job is to find the needle in the haystack, and with VMs the haystack is simply much larger.
Anomaly Detection in Containers and Kubernetes
In contrast with VMs, containers are lightweight, often running a single application, which is frequently comprised of a single process. This form factor combined with the declarative nature of Kubernetes improves the efficacy of anomaly detection by providing context around each application that is running.
The following diagram underscores why creating an activity baseline that leverages declarative information is more effective, as opposed to solely modeling runtime data. Each item below runtime is explicitly set by developers or operators and constitutes constraints for anomaly detection.
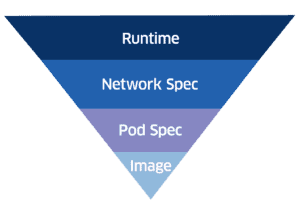
Images
The principle of Immutability that images adhere to provides the foundation for creating an activity baseline. By defining the set of binaries and packages installed in a specific version of an application, detection becomes vastly simplifed. A Dockerfile is a manifest of the required application dependencies crafted by the application developer. Since containers don’t need to support a full operating system, this architecture relies on a significantly smaller set of packages and binaries compared to a VM. With a reduced number of known binaries and packages for an application, the development team can more easily verify that only pre-existing binaries are executed. This approach catches attacks where a malicious actor inserts binaries and executes them.
What you should do:
- Strip down your image by removing all unneeded dependencies and binaries
- Regularly scan for vulnerabilities
Pod Spec
PodSpecs allow developers to build guardrails for their Pods by defining their security contexts (assigning privileges, Linux capabilities, and whether the filesystem is read-only). These configurations narrow the Pod’s activity and specify aspects of the baseline that do not need to be inferred at runtime. For example, an attempted payload drop and execution on a Pod with a read-only filesystem would be denied and the event, triggering an anomaly in your detection system. By contrast, in a VM infrastructure these tight controls are not feasible because every application on the host would need to be compatible a change of this type.
What you should do:
- Utilize Pod Security Policies
- Configure your pods’ filesystems to be read-only
- Drop unneeded Linux Capabilities
- Use Admission Controllers for custom rule enforcement
Network Spec
Similar to firewalls but at a much more granular level, Kubernetes Network Policies enable developers to describe required ingress/egress in terms of Pods and IP subnets. This shift is critical. Developers in a microservices environment have a good understanding of their application’s network interactions and can scope access solely to the known dependencies. Kubernetes abstracts away IP addresses in application-to-application communication and provides logical segmentation constructs such as namespaces and labels. Carefully defined L3/L4 segmentation augments anomaly detection by narrowing the network activity to analyze and directly exposing blocked connections.
What you should do:
- Enable namespace segmentation
- Consider enabling finer-grained Network Policies
Keeping Bad Actors at Bay
Kubernetes and containers create a unique opportunity for developers and operators to explicitly declare the environment in which their applications should run. In a traditional VM infrastructure it is difficult to effectively define an application’s activity. Alternatively, by using single-application containers, users can define a minimal set of privileges and leverage Kubernetes to provide high-level abstractions around service-to-service interactions. These fine-grained controls can augment anomaly detection by determining what behavior is malicious versus benign and highlighting activity that violates user policies. As a result, the application’s attack surface is much smaller, making it less likely that a bad actor will be able to gain a foothold in the infrastructure.
Additional Resources
9 Kubernetes Security Best Practices >