

Guest post by Evan Powell, CEO at MayaData
Last year we published a blog with a good amount of coaching and feedback from the CNCF team that set out to define the Container Attached Storage (CAS) approach. As a reminder, we tend to include OpenEBS of course as well as solutions that have similar architectures such as the proprietary PortWorx and StorageOS into the CAS category.
https://www.cncf.io/blog/2018/04/19/container-attached-storage-a-primer/
Now that OpenEBS has been contributed to the CNCF as a Sandbox project as an open source example of the CAS approach (as of May 14th 2019), I thought it timely to update this overview of the category.
Last year’s category-defining blog built on a vision of our approach that I had shared some years before at the Storage Developer Conference and which Jeffry Molanus, MayaData’s CTO has discussed in more depth at FOSDEM (Free and Open source Software Developers’ European Meeting) and elsewhere including demonstrating soon to be available software breaking the million IOPS barrier:

As a quick review:
Key attributes of CAS include:
- Using Kubernetes and containers to deliver storage and data management services to workloads running on Kubernetes;
- Additive to underlying storage whether those are cloud volumes, traditional storage SANs, a bunch of disks, NVMe or whatever;
- Per workload storage meaning each group and workload has its own micro storage system comprised of a controller or controllers which themselves are stateless and then, in addition, underlying data containers.
Key benefits of CAS:
- Immediate deployment – a few seconds and there you go – storage protecting your data and managing the underlying environment and even providing snapshots and clones for common CI/CD and migration use cases (note that some CAS solutions do have kernel modules which could slow this down depending on your environment).
- Zero operations – there really isn’t any such thing as NoOps – however, embedding your storage intelligence into Kubernetes itself can reduce the storage operations burden considerably.
- Run anywhere the same way – especially with a solution like OpenEBS that is in the user space, you can abstract away from the various flavors of storage; this is consistent with the mission of Kubernetes itself of course!
- Save money, improve the resilience of your cloud storage – thanks to thin provisioning and the ability to span availability zones and to spin up and down easily in some cases users are saving 30% or more on their cloud storage via the use of container attached storage
And the key drivers – why is it possible and even necessary now?
- Applications have changed – applications and the teams that build them now have very different requirements; see for example the growth of NoSQL and so-called NewSQL solutions.
- Kubernetes is becoming ubiquitous – providing for the first time a means to scale solutions like Container Attached Storage software.
- Containers are much more efficient – and more ephemeral – so you see 10x to 100x more containers in a typical environment than VMs and they are much more dynamic than traditional VMs.
- Storage media are perhaps 10,000x faster than when CEPH was written – the bottleneck in your environment used to be disk drives, and storage software heroically worked around this bottleneck by striping across environments; now the storage media is insanely fast, and your storage software’s inclination to stripe data adds latency
If you are interested in a hopefully humorous view of the history of storage in three slides, please take a look at this GIF-filled presentation:


Data on what we have learned in the last year:
The momentum MayaData has and other CAS solution provides are experiencing validates that the Container Attached Storage approach makes a lot of sense for many users.
We have learned a lot about these deployment patterns and common workloads, some of which I summarize here. The following data is from a survey of OpenEBS users however the patterns are similar for CAS more broadly – keeping in mind that OpenEBS is open source and especially lightweight so it may skew slightly more towards cloud deployments for example.
What Kubernetes?
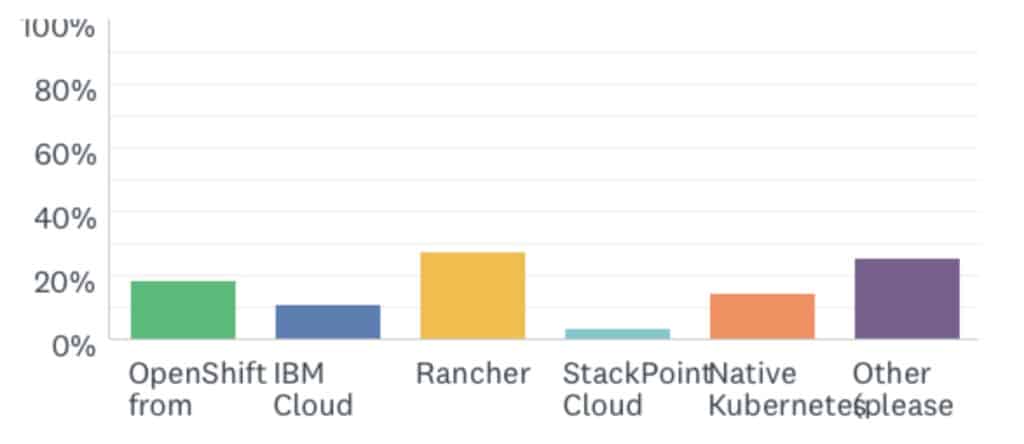
- Similarly, when asked what workloads they are running on OpenEBS, we again see a great diversity of answers:
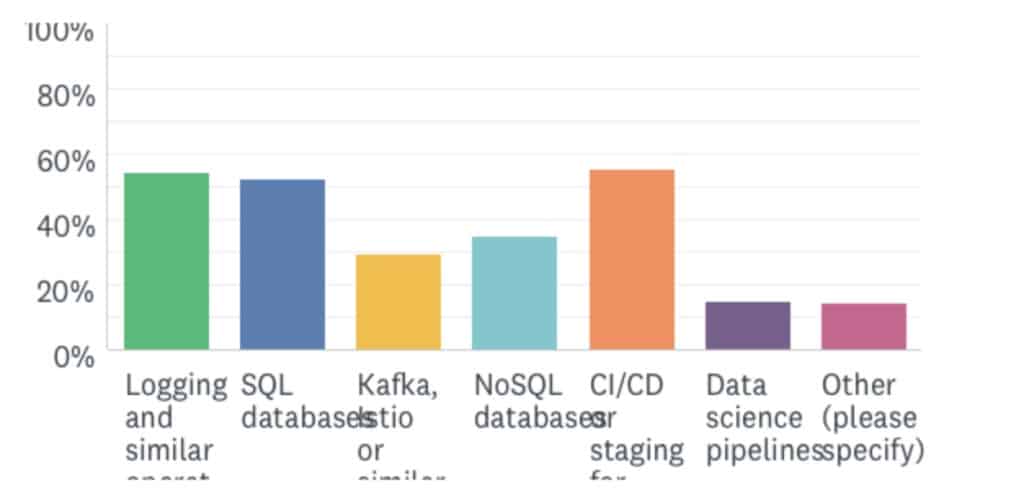
What we have found is similar to what I think everyone that has worked in storage has found over the years – workloads and solutions pull storage along.
Over the last year, we have seen opportunities for collaboration with other CAS solution providers as well. As an example, we collaborated with Portworx in supporting and improving WeaveScope. The MayaData team contributed extensions to the WeaveScope project to add visibility of PVCs and PVs and underlying storage and Portworx engineers provided feedback and insight into use cases. The software is of course upstream in WeaveScope itself and then we also offer a free monitoring and management solution called MayaOnline for community members as well that incorporates this code.
While CAS approaches allow Kubernetes to orchestrate the data along with, the workloads – the natural question that is often asked is essentially “Dude, where’s my data?” As you can see WeaveScope and MayaOnline provide an up to date answer to that and related questions:
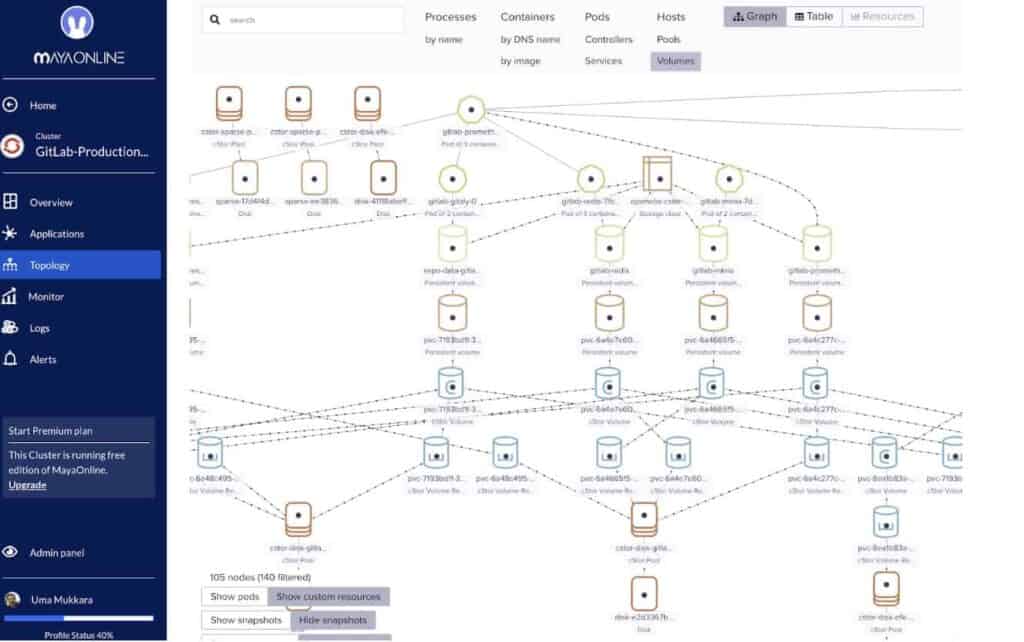
Conclusion
Thank you all for your feedback and support over the last couple of years since we first open sourced OpenEBS in early 2017 and since we helped to define the Container Attached Category in the Spring of 2018. We increasingly hear and see the CAS category used by commentators and “thought leaders” – which is great. The idea of an additive and truly Kubernetes native solution for data services just makes too much sense.
After all – what is good for the goose (the applications and workloads themselves) is good for the gander (in this case all manner of infrastructure, including storage services). Even though addressing cloud lock-in could impact the primary source of revenues for clouds, we still, on the whole, see support in the Kubernetes and cloud-native community for the CAS pattern.
We are getting closer than ever to the openness and agility we need for our data to keep up with our applications. Thanks again for your interest in the CAS pattern. Please keep in touch with your feedback, use cases, and insights.