

By Evan Powell, CEO of MayaData

Evan Powell is CEO of MayaData, the company behind OpenEBS, and previously founding CEO of Clarus Systems (RVBD), Nexenta Systems – an early open storage leader, and StackStorm (BRCD). Evan and his team have written more about the drivers of Container Attached Storage, how OpenEBS and others are building it, more more at blog.openEBS.io. They welcome feedback and look forward to additional collaboration with the broader cloud-native ecosystem and specifically fellow CNCF members.
In this blog I seek to define briefly the emerging space of Container Attached Storage, explaining the what, the why and the how of this pattern.
What is Container Attached Storage?
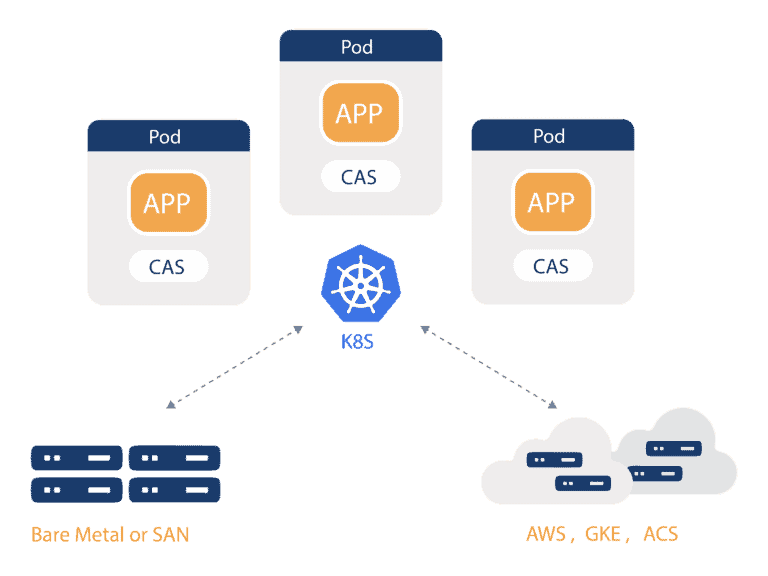
As per the above diagram, at a high-level Container Attached Storage is software that includes microservice based storage controllers that are orchestrated by Kubernetes. These storage controllers can run anywhere that Kubernetes can run which means any cloud or even bare metal servers or on top of a traditional shared storage system. Critically, the data itself is also accessed via containers as opposed to being stored in an off platform shared scale out storage system – although Container Attached Storage can run on top of such Storage Area Network “SAN” systems.
With this mind, Container Attached Storage reflects a broader trend of solutions – many of which are now being incubated by the Cloud Native Foundation – that reinvent particular categories or create new ones – by being built on Kubernetes and microservices and that deliver capabilities to Kubernetes based microservice environments. For example, new projects for security, DNS, networking, network policy management, messaging, tracing, logging and more have emerged in the cloud-native ecosystem and often in CNCF itself.

Similarly, while Container Attached Storage addresses many of the use cases of storage by being itself microservices that rely on Kubernetes and other orchestrators.
Why is Container Attached Storage being adopted?
The first reason that Container Attached Storage is being adopted that it is a microservice based architecture which means it fits into the way that systems are being built and operated in order to accelerate development – aka agility. In the case of OpenEBS, we see users adopting Container Attached Storage by specific teams to extend and customize their ability to match storage policies to workloads. As one user put it, if they only use shared storage their workloads have to contend with every other workload that is using shared storage and must pass through the so-called “I/O blender” whereas by adding OpenEBS, they can have their own block sizes, replication patterns, back up policies and more -> and they don’t have to ask for permission from a central storage authority. With Container Attached Storage the default mode of deployment is hyper converged, with data kept locally and then replicated to other hosts which has other benefits as well.
The second reason that Container Attached Storage is being adopted is due to the strategic decision of many enterprises and organizations to avoid lock-in. This desire to avoid lock-in, of course, seems to be one of the impulses behind the adoption of Kubernetes – which “runs anywhere” and ensures that the orchestration framework itself does not become a source of difficult to escape lock-in. Where Kubernetes leaves off – Container Attached Storage *can* pick up. If the Container Attached Storage is built in a way that it does not rely on kernel modifications then it truly can follow the workloads across clouds; actually, the workloads it is following may be moved with the help of the Container Attached Storage. Whereas stateless workloads are relatively easy to “move”, stateful workloads, of course, need to be drained before being moved, and the data upon which they rely must also be moved. Container Attached Storage from OpenEBS and others is increasingly able to do this data migration in the background so that cloud lock-in due to data gravity is addressed.
A third reason we see Container Attached Storage being adopted is somewhat related to the first – and that is that direct-attached storage is now often the pattern assumed by workloads and by application architectures and architects. Container Attached Storage can provide “just enough” storage management capabilities without introducing the unfamiliar “anti-pattern” of shared storage into environments that are not already familiar with SAN and other shared storage. Ironically one way that Container Attached Storage is adopted is running on top of OpenShift or some other Kubernetes environment that is backed by shared storage. Nonetheless, to the developers and workloads, Container Attached Storage looks a lot more like DAS in terms of performance and failure domains than shared storage.
How does Container Attached Storage work?
There are a variety of Container Attached Storage solutions available today, including PortWorx and StorageOS as well as OpenEBS, and each have their own strengths and weaknesses. These solutions also share certain characteristics in how they are built and deployed.
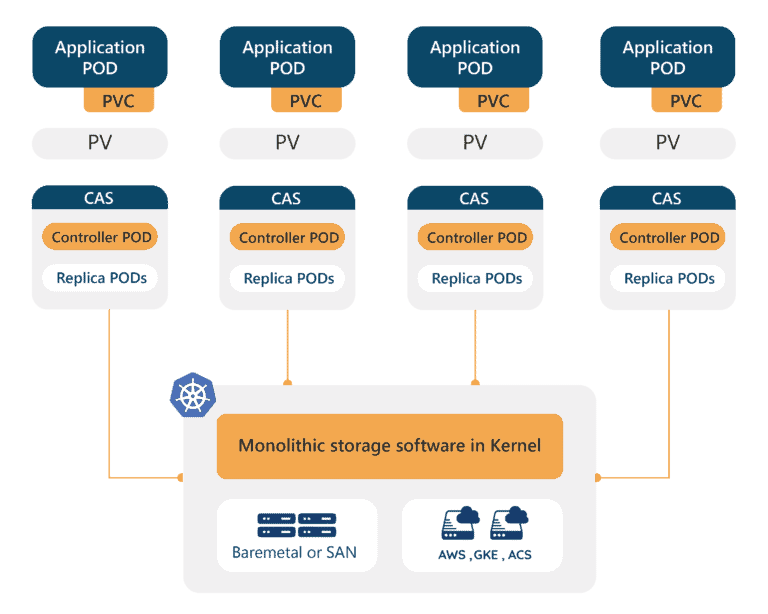
The first common characteristic is that Container Attached Storage solutions are comprised of microservices that run on top of Kubernetes and sometimes other orchestration layers. This means that traditional storage controllers have been decomposed into constituent parts that can then be run independently from each other. Thanks to this many questions of high availability and horizontal scalability are addressed “for free” thanks to leveraging Kubernetes abstractions or primitives.
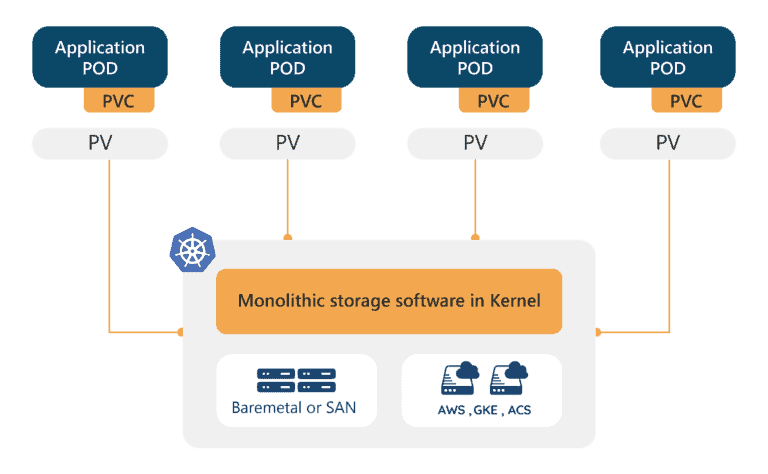
The second common characteristic of Container Attached Storage is that they pool as little I/O as possible thanks to each workload having its own controller or controllers – hence avoiding the “I/O blender” mentioned above. Why this is so important is that Input / Output operations can become the bottleneck for the performance of a stateful workload and the performance of that stateful workload can become the bottleneck for the performance of an application; in other words, when you click “buy” on your favorite travel site, the speed at which that transaction occurs might be directly related to the I/O performance of the underlying storage. It turns out applications have different needs when it comes to I/O and pooling these I/Os tends to lessen performance significantly – for example, some systems will actually be constrained more by throughput than I/O and will write large blocks to media whereas others will be constrained by I/O and will write 10 or 100x smaller blocks to media.
A quick digression – when shared scale-out storage was developed it accelerated performance versus single system direct attached storage and it simplified management as well by grouping the challenges of distributed systems management into one self-contained system. Today shared storage is almost always an order of magnitude or more *slower* than the DAS systems available thanks to solid state devices and locality and this disparity will only increase thanks to the emergence at long last of nonvolatile memory. Additionally, today distributed systems are all we do – that’s what cloud-native architectures are after all – so having another distributed system underneath the microservices environment that behaves differently is less beneficial and is sometimes seen as an “anti-pattern.”
Conclusion and what’s next?
This blog is intended to review what to those of us in the weeds of day to day support of users on Kubernetes seems pretty obvious – microservices, containerization, and especially Kubernetes have opened some new possibilities regarding the way that data is managed and stored. While shared storage will surely be with us for a long time – it has earned its place after all as the most expensive and traditional piece of the IT stack – Container Attached Storage is emerging as way to provide the level of control and performance and freedom from cloud lock-in needed by many microservice stateful workloads and by enterprises adopting cloud services, often by extending the functionality of underlying shared storage.