Found 2309 posts

Staff Post
Konnichiwa, Yokohama! KubeCon + CloudNativeCon returns to Japan in 2026
The inaugural KubeCon + CloudNativeCon Japan 2025 was an overwhelming success. There were more than 700 speaking session submissions. Registrations and sponsorships completely SOLD OUT. This is why I’m thrilled to share KubeCon + CloudNativeCon will...
July 8, 2025 | Chris Aniszczyk

Member Post
Why Policy as Code is a Game Changer for Platform Engineers
Originally posted on Nirmata’s blog. Platform engineers, let’s talk about a fundamental shift that’s revolutionizing how we build and manage internal developer platforms: Policy as Code (PaC). This isn’t just another buzzword; it’s the key to...
July 8, 2025 | Jim Bugwadia, co-founder and CEO of Nirmata

Kmesh v1.1.0 Officially Released!
We are excited to announce the release of Kmesh v1.1.0—a major milestone shaped by contributions from our global community, including key support from LFX Project participants, whose dedication have been pivotal in driving this release forward....
July 3, 2025 | Lexi Wang

Project Post
OpenYurt Becomes a CNCF Incubating Project
The Cloud Native Computing Foundation (CNCF) Technical Oversight Committee (TOC) has voted to accept OpenYurt as an incubating project. OpenYurt joins a growing ecosystem of technologies tackling real-world challenges at the edge of cloud-native infrastructure. What...
July 2, 2025 | OpenYurt Project Maintainers

Cloud Native Glossary — The Vietnamese Version is Live!
The Cloud Native Glossary is a project that aims to define cloud native concepts in clear and simple language, making them accessible to anyone without requiring any previous technical knowledge. This project thrives on open contributions...
June 26, 2025 | Cloud Native Glossary Vietnamese Localization Team

Cloud Native App Local Development Made Easy with Microcks and Dapr
Cloud native application development can be intimidating sometimes! Architecting distributed applications that need to access and connect to complex infrastructure requires developers to learn different technologies and cloud services, which slows down their development tasks. It...
June 25, 2025 | Mauricio Salatino and Laurent Broudoux

Joining CNCF as Executive Director: Let’s Build What’s Next
The CNCF community represents the best of open source: innovative, passionate, diverse, and collaborative. It’s a community reshaping how the world runs software in production, and I’m excited to serve as the new Executive Director. I...
June 24, 2025 | Jonathan Bryce
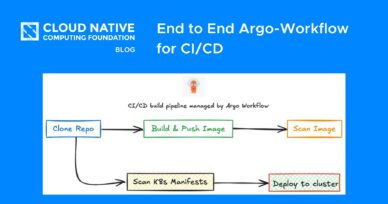
End to End Argo-Workflow for CI/CD
Argo Workflows is a powerful open-source container-native workflow engine designed to automate CI/CD processes by defining them as custom resources. It allows for the creation of multi-step workflows where each step runs within a container, enabling...
June 21, 2025 | Afzal Ansari
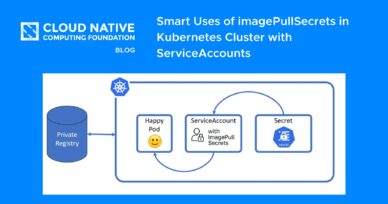
Smart Uses of imagePullSecrets in Kubernetes Cluster with ServiceAccounts
Kubernetes is everywhere nowadays, so are the container images and fetching the images from a private registry is a norm because of N number of reasons including security, that being the topmost. Recap Just to give...
June 20, 2025 | Sunny Bhambhani

Member Post
Announcing KServe v0.15: Advancing Generative AI Model Serving
Originally posted on KServe blog. We are thrilled to announce the release of KServe v0.15, marking a significant leap forward in serving both predictive and generative AI models. This release introduces enhanced support for generative AI workloads,...
June 18, 2025 | Alexa Griffith, Dan Sun, Yuan Tang, Johnu George, Lize Cai

Staff Post
CNCF Slack Workspace Changes Coming on Friday, June 20
We’ve received notice from Salesforce that our Slack workspace WILL NOT BE DOWNGRADED on June 20th. Stand by for more details, but for now, there is no urgency to back up private channels or direct messages. The...
June 16, 2025 | Daniel Krook

Staff Post
Introducing the Certified Cloud Native Platform Engineering Associate (CNPA): Community-Driven Certification for Platform Engineers
The Cloud Native Computing Foundation (CNCF) and Linux Foundation Education are excited to announce the launch of the Certified Cloud Native Platform Engineering Associate (CNPA) certification! Why CNPA, and why now? At recent KubeCon + CloudNativeCon,...
June 15, 2025 | Katie Greenly

A Year of Envoy Gateway GA: Building, Growing, and Innovating Together
A year of GA What Does GA Mean? A lot can happen in a year, and a lot has happened for Envoy Gateway since it reached general availability a little over a year ago. Before exploring...
June 11, 2025 | Erica Hughberg

Opening the TAB: Our Priorities for the Year
The CNCF End User Technical Advisory Board (TAB) serves as the voice of the end user community to ensure that the needs and perspectives of end users are represented effectively in CNCF community decisions. Since its...
June 10, 2025 | CNCF End User Technical Advisory Board

Scholarship Post
My Journey to KubeCon + CloudNativeCon 2024: A Story of Volunteering and Growth
My name is Oscar Ayra and I am from Lima, Peru. In 2024, I had the privilege of being part of the volunteer team at Kubernetes Community Days (KCD) Lima. It was an enriching experience where...
June 10, 2025 | Oscar Ayra

Ambassador Post
Newbie No More: Lessons from My First KubeCon + CloudNativeCon as a Speaker
Introduction April in London has never felt so electric. From the first footstep in the ExCeL halls to the hallway conversations, KubeCon + CloudNativeCon Europe 2025 was a whirlwind of new ideas, familiar faces, and those...
June 10, 2025 | Sandipan Panda

Ambassador Post
GitOps in 2025: From Old-School Updates to the Modern Way
1. Introduction: Why Everyone’s Talking About GitOps in 2025 It’s 2025, and building software is more cloud-driven than ever. Cloud computing offers incredible speed and flexibility, but it also brings complexity. Companies are expected to ship...
June 9, 2025 | Gerardo Lopez and Saloni Narang

A Farewell from Priyanka Sharma, Executive Director of CNCF
After five extraordinary years, I’m stepping down from my role as Executive Director of the Cloud Native Computing Foundation. A Journey of Growth and Impact Leading CNCF has been the honor of a lifetime. I joined...
June 6, 2025 | Priyanka Sharma

Project Post
Kubeflow Advances Cloud Native AI: A Glimpse into KubeCon + CloudNativeCon Europe 2025
The Kubeflow community is rapidly growing due to its contributions to advancing AI by streamlining the AI/ML experience in Kubernetes. Kubeflow provides a composable ecosystem for implementing end-to-end solutions for AI/ML. Kubeflow includes the following projects:...
June 6, 2025 | Valentina Rodriguez Sosa

Member Post
Securing Kubernetes Traffic with Calico Ingress Gateway
Kubernetes, Envoy, GatewayAPI, cert-manager, CNI, Calico If you’ve managed traffic in Kubernetes, you’ve likely navigated the world of Ingress controllers. For years, Ingress has been the standard way of getting our HTTP/S services exposed. But let’s...
June 6, 2025 | Reza Ramezanpour