
How XiaoHongShu (Red Note) handled TikTok refugee surges with Karmada
Company overview
Xiaohongshu (RedNote) is a leading lifestyle and social e-commerce platform in China with over 300 million monthly active users. The platform’s core business centers on search, advertising, and recommendations, complemented by social networking and e-commerce capabilities. These services demand massive computational resources and handle enormous data volumes, with individual index tables reaching terabyte scale.
To meet these resource demands while maintaining business agility, Xiaohongshu operates a hybrid cloud infrastructure combining self-built data centers with multiple public cloud providers, with Karmada as the core orchestration layer. This architecture enables elastic scaling and ensures the platform can respond quickly to traffic surges, spanning 200+ Kubernetes clusters with over 10 million CPU cores.
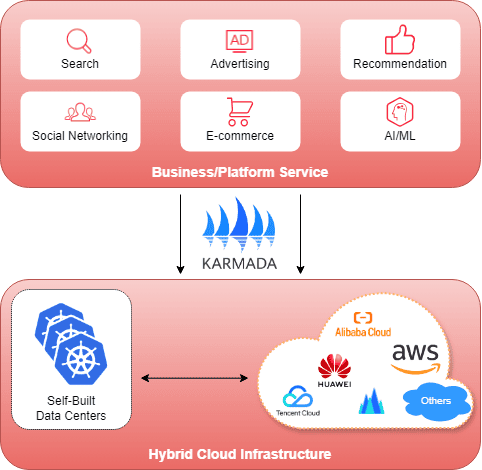
“Karmada has become essential to our multi-cloud strategy, enabling us to manage resource fragmentation as a competitive advantage rather than a operational burden. The platform’s Kubernetes-native approach meant zero migration cost, while its extensibility allowed us to build production-grade features. Most importantly, during periods of unexpected traffic surges, Karmada’s federation capabilities proved invaluable—we could elastically burst to cloud resources for specific services rather than entire chains, delivering the lowest risk and cost profile during peak demand.”
Yuqi Huang, Director of Cloud Native Infrastructure at Xiaohongshu

Projects used


By the numbers
10x
traffic spike during TikTok migration event
200+
Kubernetes clusters with over 10 million CPU cores
300+
million monthly active users
The Challenge: Resource fragmentation
As Xiaohongshu’s business grew rapidly, its infrastructure demands quickly outpaced the capacity of individual Kubernetes clusters. Both self-built data centers and managed Kubernetes services (TKE/ACK) from cloud vendors have cluster size limits for stability reasons. To accommodate the expanding workloads, the platform evolved into dozens of Kubernetes clusters spread across multiple cloud providers and self-built data centers.
While this multi-cluster approach solved the capacity problem, it introduced a new challenge: resource fragmentation.
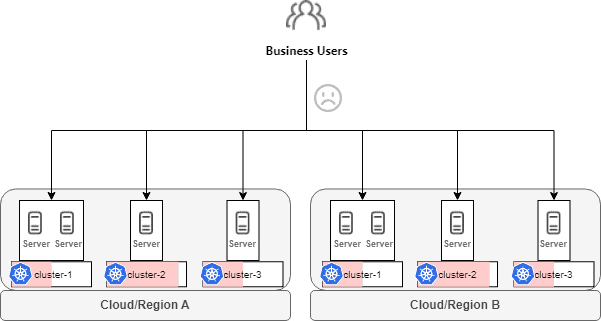
The fragmented infrastructure created multiple operational problems:
- Cluster-Aware Deployment Burden: Each cluster operated as an isolated resource silo. Business teams had to be aware of individual clusters when deploying applications, leading to a fragmented platform experience and significant communication overhead.
- Endless Migration Cycles: With rapid business growth, clusters would fill to capacity within months. Teams then had to migrate applications to new clusters—a frequent, labor-intensive process that consumed significant operational effort and introduced migration risks.
- Maintenance Blocks Business: Platform engineers conducting cluster maintenance inevitably impacted business teams, requiring them to pause releases or coordinate migrations. The lack of flexibility created friction between platform and application teams.
- Scattered GPU, Wasted Capacity: As AI workloads grew rapidly, tens of thousands of GPU cards became scattered across dozens of clusters. Without unified management, GPUs were not effectively utilized—some clusters had long queues waiting for GPU resources while others sat idle.
- No Cross-Cluster Elasticity: The platform lacked the ability to intelligently distribute workloads. Ideally, it should prioritize self-built data center resources while automatically bursting to cloud when capacity became insufficient—but this required coordinated scheduling across isolated clusters.
The ideal deployment model
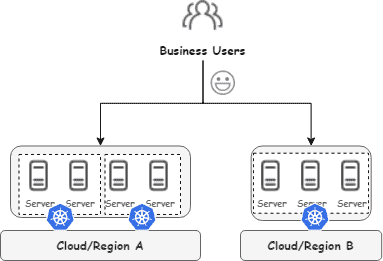
The ideal deployment model is straightforward: business teams select a region, and the platform provides a unified resource pool. This directly addresses the pain points above by: Business teams no longer perceive cluster details—deploy once to a region and let the platform handle placement. Infrastructure gains the flexibility to balance capacity, pool GPUs, and burst to cloud without handoffs to the business side.
The TikTok refugee crisis: A wake-up call
In January 2025, when TikTok faced potential restrictions, millions of users suddenly migrated to Xiaohongshu, causing massive traffic spikes. The self-built data centers’ resources were immediately exhausted. The team faced three difficult options:
- Emergency server procurement: But with Chinese New Year approaching, delivery was uncertain and costs would be astronomical
- Traffic redistribution: Shift more traffic to cloud regions, but this would require scaling entire service chains, not just individual services, dramatically increasing costs and complexity
- Leverage federation: Use the federated cluster system to elastically burst to cloud resources only for services under pressure
The third option, enabled by Karmada-based federation, proved to be the solution.
The solution: Karmada-based multi-cluster federation
Xiaohongshu chose to build a federated cluster system with Karmada at its core, focusing on two key principles:
- Hide cluster complexity from business teams: Enable teams to think in terms of regions, not individual clusters
- Unify resource scheduling: Create a global resource pool from fragmented clusters
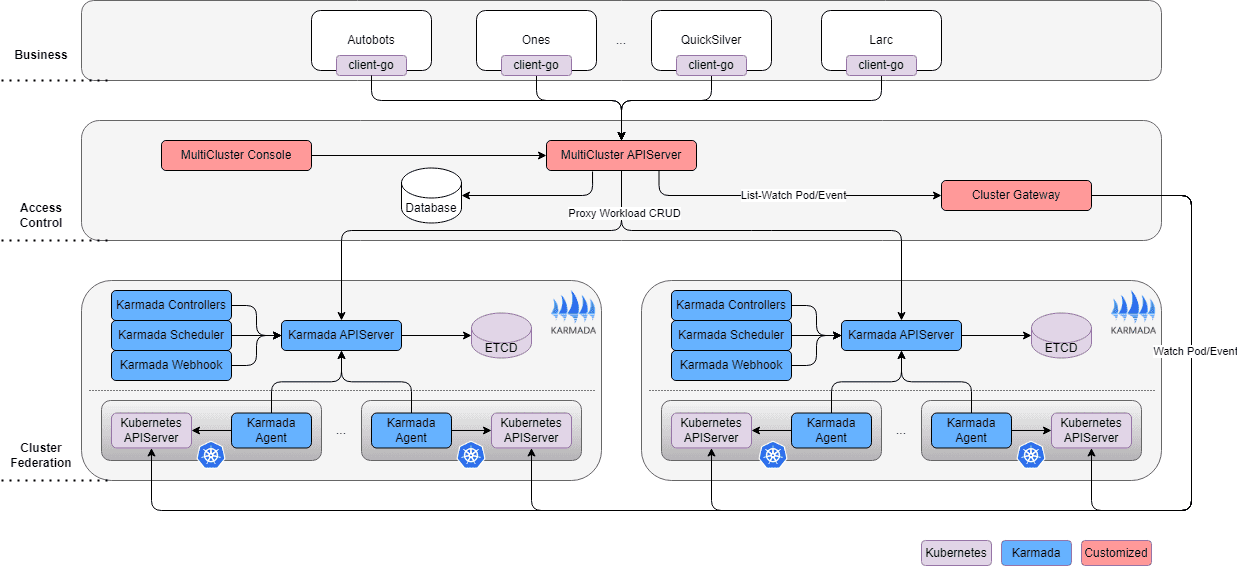
Architecture design principles
The solution included three core components:
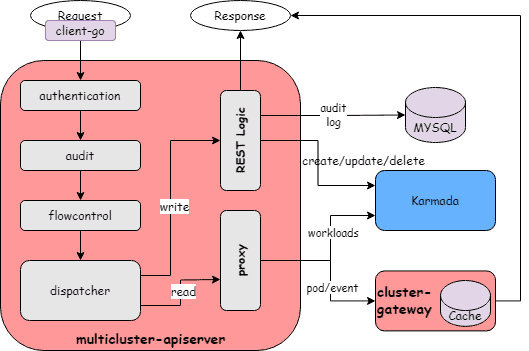
1. Unified API gateway
Xiaohongshu maintained Kubernetes API compatibility to ensure zero migration cost for existing platforms and applications. They built a custom access layer that intelligently routes requests:
- Workload resources (Deployments, StatefulSets) route to Karmada’s control plane
- Pod and PVC queries route to ClusterGateway, a custom component that aggregates data from member clusters
This design allows standard Kubernetes clients (kubectl, client-go) to work seamlessly without modification.
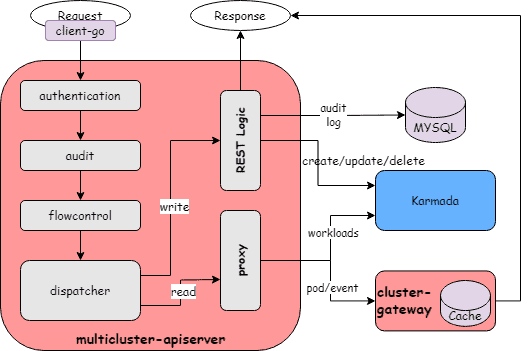
2. Multi-tier scheduling system
The scheduling architecture uses a “self-built first, cloud backup” policy:
- Regional scheduling: Prioritizes self-built data center resources, automatically bursting to cloud when capacity is insufficient
- Pre-scheduling capability: Captures resource snapshots from member clusters and simulates complete scheduling logic to determine optimal replica distribution
- Smart scaledown: Automatically removes cloud resources first during scaledown operations
3. Enhanced workload orchestration
In Xiaohongshu’s practice, workload changes require strict control over the rollout pace, similar to MaxUnavailable and MaxSurge configuration in Deployment. Working together with the community, they designed an extension solution that implements federation-level rolling update strategies by extending the Resource Interpreter.
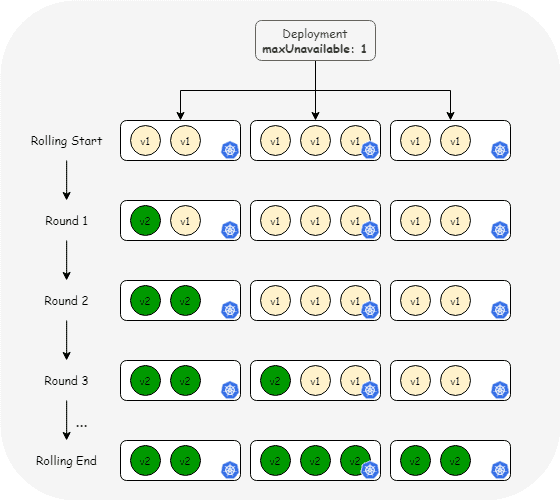
As shown in the diagram, during each application update, regardless of how many clusters the replicas are distributed across, each rolling phase updates only one replica at a time, effectively improving the safety of the changes.
Federated HPA
Traditional HPA operates at the individual cluster level, requiring each cluster to independently monitor metrics and make scaling decisions. This approach becomes inefficient in a federated environment where workloads span multiple clusters. Xiaohongshu moved the autoscaling logic to the federation layer, creating a unified view of application health and resource utilization across all clusters.
The Federated HPA Controller (FHPA) collects pod-level metrics from member clusters, aggregates them at the workload level, and makes intelligent scaling decisions based on the complete application state.
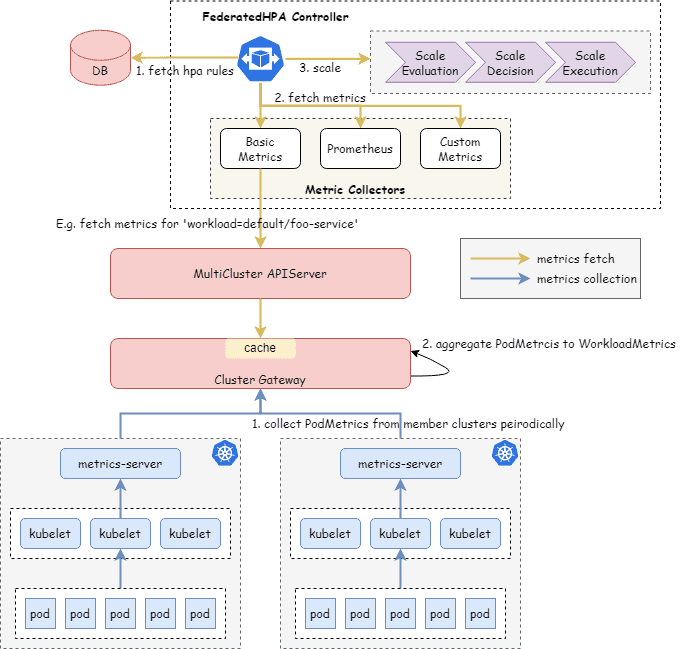
This architecture enables more efficient resource utilization across clusters. For example, during traffic spikes, FHPA can intelligently scale up replicas in the most appropriate clusters based on available capacity and scheduling policies, rather than requiring each cluster to independently react to local metrics.
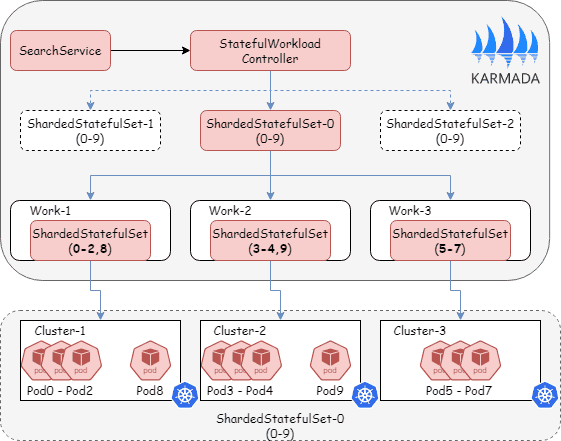
Custom StatefulSet Developed a stateful workload controller with customizable index orchestration for search and recommendation services. This enables:
- Customizable pod indexing across clusters (e.g., cluster 1: pods 0-2, cluster 2: pods 3-5)
- Detailed status reporting for each pod index
- Precise rollout control with fine-grained parameters like
MaxUnavailableandMaxSurge - Incremental data updates without full reloads
Results and benefits
- Operational efficiency: Eliminated manual multi-cluster deployments and migrations
- Resource utilization: Significantly improved through global resource pooling and federation-level HPA
- Cost optimization: Service-level scaling instead of chain-wide scaling during traffic surges
- Developer experience: Zero-cost migration for existing applications due to full Kubernetes API compatibility
- GPU efficiency: Reduced minimum replica counts from 10x per model to 1x per model, freeing hundreds of GPU cards
- Resilience: Successfully handled unexpected 10x+ traffic spike during TikTok migration event
Search and recommendation: Precise management at scale
The search and recommendation services are among the most critical systems at Xiaohongshu, processing massive index tables reaching terabyte scale. With the custom StatefulSet controller, these large-scale stateful workloads can now be precisely managed and orchestrated across the federation:
- Large-Scale Management: Successfully manages massive distributed applications with thousands of replicas across multiple clusters while maintaining data consistency
- Precise Release Control: Enables fine-grained rollout orchestration with parameters like
MaxUnavailableandMaxSurge, ensuring safe and controlled deployments without service disruption - Elastic Cross-Cluster Deployment: Applications can elastically expand across clusters based on demand, providing the flexibility needed for critical business workloads
GPU resource pool unification for LLM inference
Large language model inference had unique challenges:
- GPU scarcity: Tens of thousands of GPU cards scattered across dozens of clusters
- HPA inefficiency: Without federation, HPA required at least one replica per cluster. For 100 models across 10 clusters, this meant 1,000 minimum replicas even during low traffic
- Deployment complexity: Teams had to manually deploy models to multiple clusters
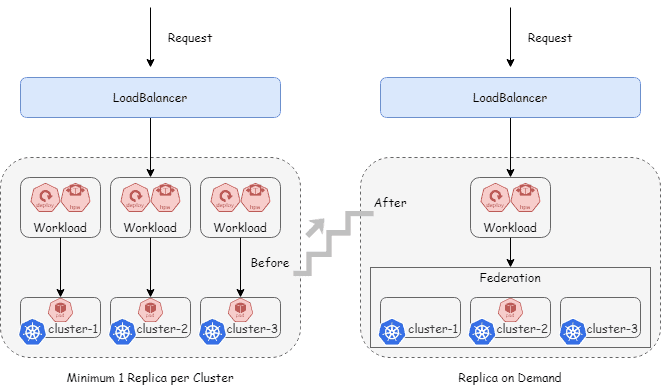
With federation:
- Single deployment: Business teams deploy once; federation handles distribution
- Optimized HPA: Federation-level HPA can scale to a single replica globally during low traffic
- Dramatic efficiency gains: GPU utilization improved significantly by eliminating mandatory per-cluster replicas
Surviving the traffic surge
During the TikTok user migration crisis, the federation system proved its value:
- Rapid response: Cloud clusters (ACK) were dynamically added to the federation
- Targeted scaling: Only services experiencing pressure scaled to the cloud, not entire service chains
- Automatic scaledown: After traffic normalized, cloud resources were released automatically
- Cost optimization: Service-level precise scaling minimized costs compared to chain-wide scaling
This approach delivered the lowest risk and cost profile during the crisis.
Why Karmada?
Xiaohongshu evaluated multiple federation solutions and selected Karmada for several reasons:
- Kubernetes-native API: No application refactoring required; standard Kubernetes clients work without modification
- Resource-centric design: Focus on resource scheduling aligns with Xiaohongshu’s efficiency goals
- Flexible cluster access: Both push and pull modes support diverse network topologies
- Active community: Open governance and responsive community support ongoing improvements
- Extensibility: Provides out-of-the-box and configurable capabilities, making it convenient to extend controllers and scheduling policies
Future plans
Xiaohongshu continues to expand their Karmada-based federation with plans to:
- AI Training and Big Data Workload Federation: Extending federation support to AI training workloads and Spark big data jobs, leveraging community contributions and existing ecosystem solutions
- Contributing Extensions Back: Sharing Xiaohongshu’s custom enhancements, including Fleet-Root and other production-grade features, back to the Karmada community to benefit other users
- Intelligent Scheduling Policies: Contributing cost and latency-aware scheduling strategies to help optimize resource allocation across hybrid cloud environments
- Community Performance Optimization: Joining the Karmada community’s performance optimization efforts to help continuously improve the platform’s efficiency and reliability
Conclusion
Xiaohongshu’s journey with Karmada demonstrates how multi-cluster federation can transform hybrid cloud operations from a management burden into a competitive advantage. By focusing on resource efficiency, maintaining Kubernetes compatibility, and extending Karmada thoughtfully, the company built a system that not only solved immediate operational pain points but also provided the foundation for handling unexpected challenges—like a sudden 10x traffic spike from millions of new users.
The success during the TikTok migration event proved the architecture’s core idea: unified resource scheduling across fragmented clusters enables both operational efficiency and business resilience. As Xiaohongshu continues to scale, Karmada remains central to their strategy for managing complexity while maintaining agility in a dynamic multi-cloud environment.