
Effective GPU: A Heterogeneous AI Virtualization Pooling solution by SF technology built on top of HAMi
About
SF Technology, the technology arm of SF Express—China’s leading integrated logistics service provider—operates one of the largest and most advanced logistics networks in the world. With a strong focus on digital transformation and intelligent logistics, SF Technology leverages cutting-edge AI and cloud native technologies to optimize operations, enhance customer experience, and drive business innovation.
Challenge
As AI workloads grow in scale and diversity, SF Technology and similar organizations face significant challenges in maximizing the utilization of heterogeneous compute resources such as GPUs, NPUs, and other accelerators:
- Low resource utilization: Static allocation leads to a large amount of compute and memory resources remaining idle for long periods, making them unavailable for efficient reuse by other workloads.
- High operational costs: Organizations continuously pay for underutilized resources, significantly increasing the total cost of ownership for infrastructure.
- Inflexible scheduling: Once resources are statically assigned, the scheduler cannot dynamically adjust allocations based on real-time business needs, limiting the elasticity and scalability of the cluster.
Enterprises need a unified, flexible, and efficient way to manage and share heterogeneous AI resources across clusters and workloads, while supporting both mainstream and domestic hardware platforms.
Solution
To address these challenges, the team developed EffectiveGPU, an in-house solution built on top of the CNCF Sandbox project HAMi to provide GPU pooling technologies.

By the numbers
0 Changes
To Nvidia driver, Linux kernel, task image and source code
Up to 57%
GPU Savings for production and test clusters
Up to 100%
GPU utilization improvement with GPU virtualization
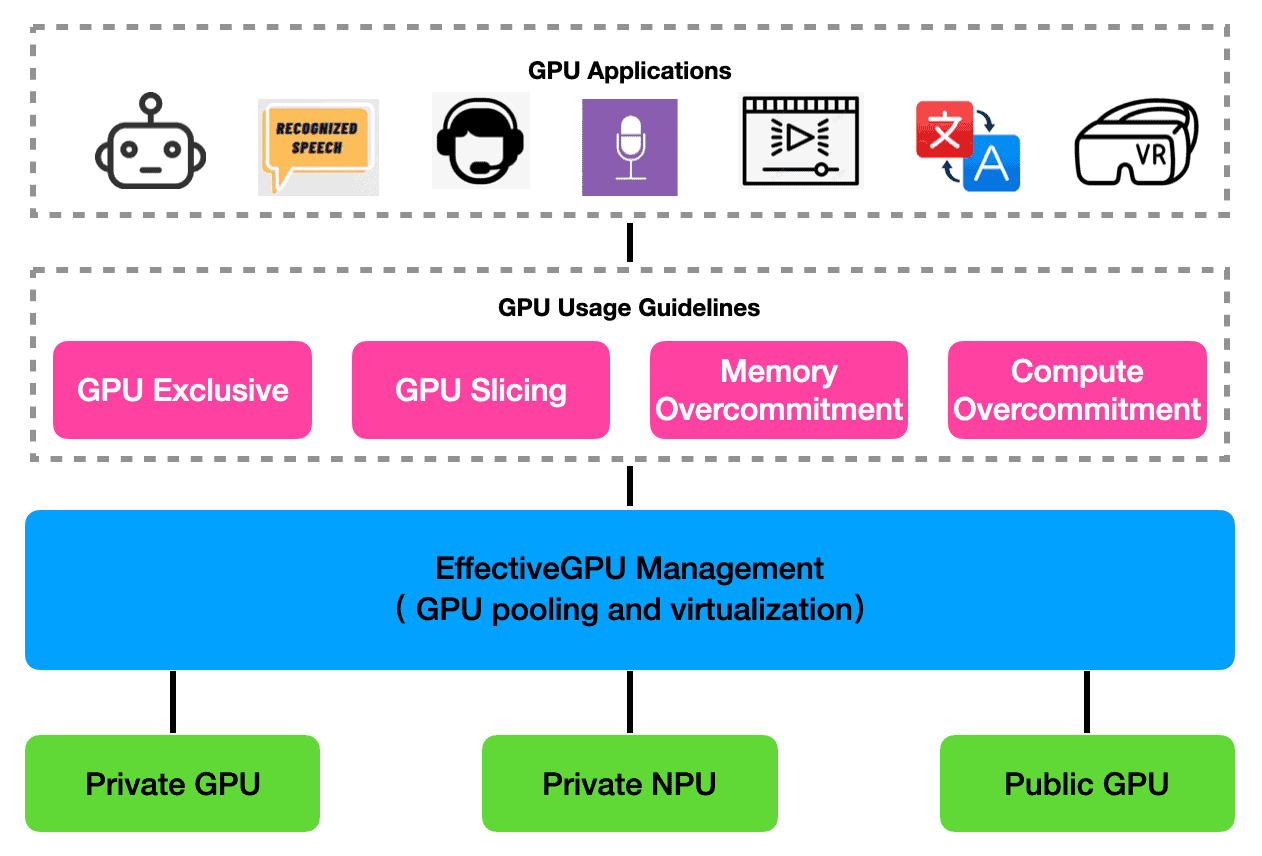
EffectiveGPU leverages several key capabilities provided by HAMi:
- Device Virtualization: Fine-grained partitioning of device compute and memory, allowing multiple pods to share a single physical device.
- Resource Hard Isolation: Enables limiting container memory and compute specifications, ensuring tasks cannot exceed their allocated quotas.
- Heterogeneous AI Computing Support and Adaptation: The computing framework supports heterogeneous AI computing platforms such as Huawei Ascend, Baidu Kunlun, and Sunway Smart Cards, while adapting to mainstream AI frameworks and heterogeneous computing AI frameworks.
- Priority-Based GPU Computing Preemption: Tasks can define custom priorities, allowing high-priority tasks to preempt computing resources from low-priority tasks. When high-priority tasks request computing resources, low-priority tasks are automatically suspended, and when high-priority tasks have no computing requests, low-priority tasks resume execution.
- Unified Scheduling: A scheduler extender and mutating webhook for Kubernetes, supporting both kube-scheduler and Volcano, enabling topology-aware and policy-driven resource allocation.
- Zero Application Changes: Users can leverage device sharing and isolation without modifying their existing applications.
EffectiveGPU further extends the capabilities of HAMi and provides the following advanced features:
- Cross-Node Computing Collaborative Scheduling: Researches AI computing collaborative scheduling methods to fully utilize low-computing node resources, alleviate resource competition on high-computing nodes, achieve cross-node computing scheduling, and improve the efficiency, availability, and reduced resource competition of cloud AI computing platforms.
- Adaptive Domestic AI Computing Scheduling: For domestic AI computing resources, researches adaptive scheduling algorithms that determine allocated computing types and shares through predictive algorithms based on task categories and resource affinity, achieving precise scheduling. Considers heterogeneous resource topology information between nodes, executes minimum-conflict resource allocation schemes, and supports elastic scheduling strategies.
- Memory Over-Subscription Technology: Introduces memory over-subscription technology that, without changing physical memory, optimizes memory allocation strategies and management mechanisms to enable the system to support more concurrent tasks, effectively solving the high demand for memory resources in multi-task scenarios and improving memory utilization and system parallel processing capabilities.
- Resource Allocation and Scheduling Mechanisms: Designs a flexible resource allocation and scheduling mechanism that dynamically allocates appropriate memory and other computing resources based on task priorities and resource requirements. In resource-constrained situations, prioritizes resource supply for high-priority tasks while reasonably adjusting resource usage for low-priority tasks, ensuring optimal system resource utilization.
- Resource Preemption and Recovery Strategies: Establishes resource preemption and recovery strategies that allow high-priority tasks to preempt partial resources from low-priority tasks when needed to meet their own requirements. Simultaneously, when tasks complete or resources are exhausted, promptly recovers resources for reuse by other tasks, improving resource turnover efficiency.
- Performance Optimization and Load Balancing: Reduces task delays and blocking during resource waiting through performance optimization, improving task execution efficiency. Considers overall system load conditions to achieve load balancing, preventing over-occupation of certain resources that could lead to system performance degradation, ensuring system stability and efficiency during multi-task parallel execution.
By leveraging these technologies, the team can deploy more services with fewer GPUs, dynamically adjust resource allocation based on real-time demand, and support heterogeneous compute environments.
Impact
1. Large Model Inference Services
In AI production model services, traditional GPU resource allocation methods often result in low resource utilization and high costs. By adopting EffectiveGPU technology, resource utilization can be significantly improved and operational costs reduced. For example, AI production model services that have switched to EffectiveGPU deployed 65 services using only 28 GPUs, saving 37 GPUs. This approach not only increases GPU utilization but also makes service deployment more flexible, allowing dynamic resource allocation based on actual needs and avoiding resource waste.
2. Test Service Cluster Scenarios
In cluster testing services, flexible resource allocation and efficient utilization are crucial for testing efficiency and cost control. EffectiveGPU technology enables test services to flexibly allocate GPU resources according to different testing task requirements through partitioning. For instance, Testing services using EffectiveGPU deployed 19 services on 6 test GPUs, saving 13 GPUs. This not only improves testing efficiency but also reduces testing costs, enabling more rational resource utilization.
3. Speech Recognition Scenarios
Speech recognition services require efficient computing resources to ensure real-time performance and accuracy. EffectiveGPU provides flexible support for speech recognition through priority scheduling and resource over-provisioning. GPU resources can be dynamically allocated based on the urgency and resource requirements of speech recognition tasks, ensuring that high-priority tasks receive sufficient resources in a timely manner and improving the quality of speech recognition services.
4. Domestic AI Hardware Adaptation Scenarios
EffectiveGPU technology supports not only mainstream GPU hardware but also domestic AI computing platforms such as Huawei Ascend and Baidu Kunlun. This provides strong support for the application and promotion of heterogeneous AI technologies, enabling efficient management and resource utilization in localized environments. For example, in scenarios using heterogeneous AI chips, EffectiveGPU’s scheduling and management can fully leverage the advantages of heterogeneous AI computing devices, promoting the development and application of heterogeneous AI technologies.