
NIO improves GPU utilization for autonomous driving workloads with HAMi
NIO operates large-scale cloud infrastructure to support autonomous driving workloads, including model training, simulation, CI/testing, and online inference. The team focuses on GPU performance optimization and participates in GPU and compute resource planning decisions.
Challenge
NIO’s large-scale cloud infrastructure supports diverse autonomous driving workloads, including training, simulation, CI/testing, and online inference. The team is responsible for GPU performance optimization and resource planning. This diversity led to persistent efficiency challenges due to workload–resource mismatch.
Workloads with low GPU utilization
CI and Testing Tasks
Most of the execution time for CI tasks is spent on CPU-intensive operations such as compilation, file fetching, and preprocessing. GPUs are only used intermittently. Under full-GPU allocation, average GPU utilization was typically 5–10%.
Simulation workloads
Simulation pipelines process video streams, radar data, and inference validation. Individual tasks have relatively low compute requirements and are not latency-sensitive, making them suitable for concurrent execution on shared GPUs.
Online inference and small model inference
Many inference services require only ¼ or ½ of a GPU. Allocating an entire GPU is both inefficient and costly.
- The GPU cluster size is limited, and part of the capacity is sourced from public cloud providers with time-based billing.
- Low GPU utilization results in wasted GPU hours, directly increasing operational costs.
- Inefficient allocation also prolongs queue times for high-demand training jobs.
NIO needed a way to improve GPU utilization without sacrificing workload stability, while supporting multiple workload types within the same Kubernetes environment.
Projects used


By the numbers
600
GPUs across ~80 nodes supporting autonomous driving workloads
10×
GPU utilization improvement in CI pipelines
30%
reduction in GPU hours for simulation workload
Solution
NIO adopted a hybrid GPU sharing strategy, selecting different GPU allocation mechanisms based on workload characteristics rather than enforcing a single approach.
The following diagram illustrates the GPU management architecture after integrating HAMi into Kubernetes.
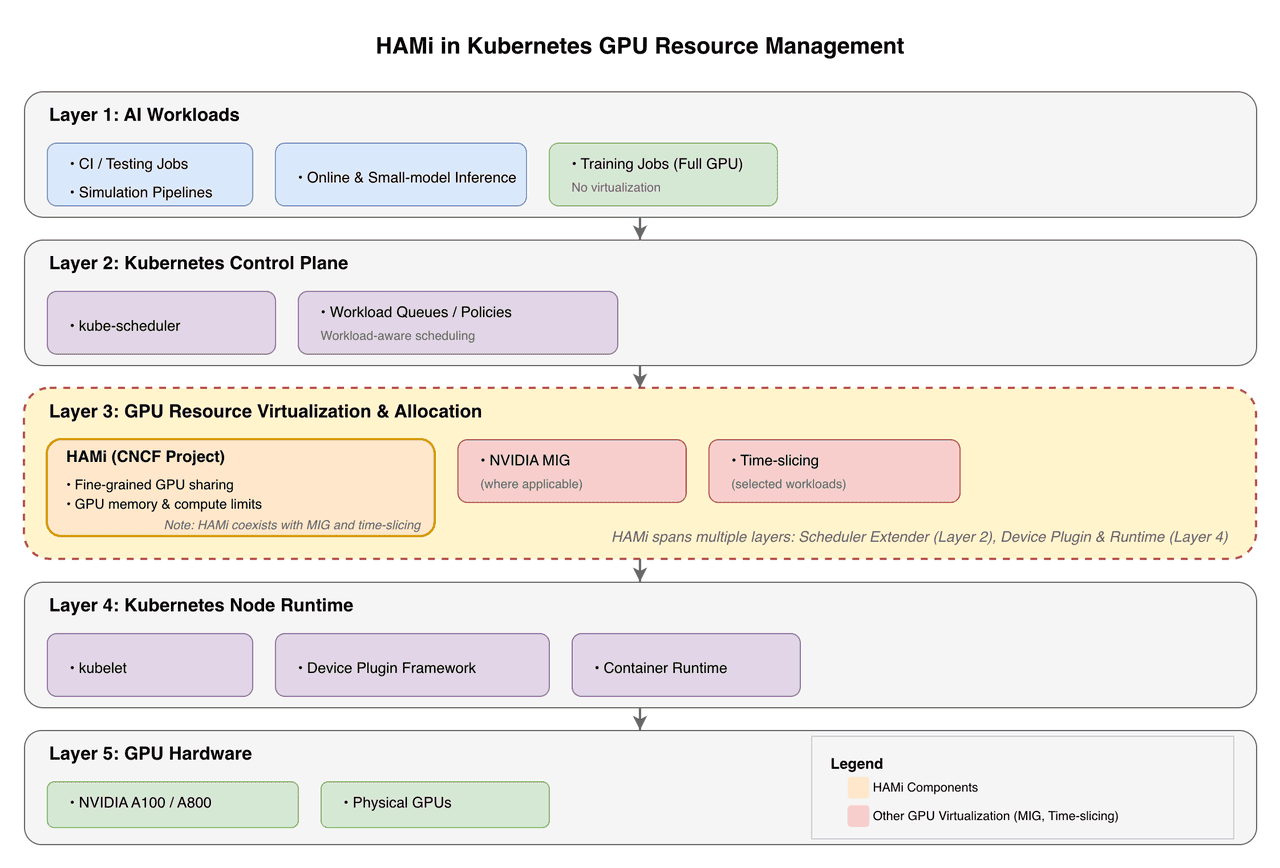
HAMi extends Kubernetes with fine-grained GPU sharing capabilities through scheduler extensions (Layer 2) and device plugin integration (Layer 4), enabling flexible GPU resource allocation while coexisting with NVIDIA MIG and time-slicing strategies.
Evaluated approaches
NVIDIA MIG
Provides strong isolation but supports only predefined partition sizes, making it difficult to match finer-grained requirements (e.g., 1/6 or 1/8 of a GPU).
Time-Slicing
Allows workloads to compete freely for GPU resources with minimal overhead. However, it lacks strict limits on memory and compute usage, making it unsuitable for certain production workloads.
HAMi (a CNCF Sandbox project)
Supports fine-grained control over both GPU memory and compute allocation, enabling proportional allocation based on actual workload requirements. This approach introduces some overhead compared to full GPU allocation.
Production strategy
Rather than replacing existing mechanisms, NIO combined them:
- MIG: Used for algorithm development and environments requiring strong isolation
- HAMi: Used for CI tasks and selected inference and simulation workloads
- Time-slicing: Used for workloads that can tolerate resource contention
This hybrid approach improved GPU utilization while maintaining correctness and operational safety.
Implementation
- HAMi was deployed on selected GPU clusters, not across all clusters.
- Large-scale training jobs continue to use full GPUs by default.
- HAMi primarily covers workloads suitable for fractional GPU allocation.
Deployment scale:
- Approximately 50–70 active nodes
- Approximately 400–560 GPUs (assuming 8 GPUs per node)
Resource allocation design
For simulation workloads, NIO treated GPU memory (VRAM) as the primary constraint:
- Insufficient compute capacity can be mitigated through scheduling delay.
- Memory exhaustion immediately triggers failure (OOM) and cannot be deferred.
The team also found that finer partitioning is not always better. For certain simulation workloads, allocating approximately 1/6 of a GPU provided optimal efficiency. Smaller fractions (such as 1/8) introduced additional scheduling and virtualization overhead, reducing overall throughput.
Impact
CI Workloads: From Waste to Reuse
Before HAMi:
Because CI tasks were primarily CPU-bound, average GPU utilization was approximately 5% (5–10%).
After HAMi:
By partitioning GPUs into ¼ or smaller fractions, effective GPU utilization in CI pipelines increased by approximately 4×, reaching 30–50%.
Simulation workloads: Higher throughput, fewer GPU hours
- Fine-grained GPU sharing reduced overall GPU hours by approximately 30%.
- End-to-end simulation tasks that previously required about 3 days were reduced to about 2 days.
These improvements increased overall system throughput while directly reducing GPU costs.
Lessons learned
GPU partitioning is not “the finer, the better.”
Each workload has an optimal partition size. Over-fragmentation can reduce efficiency.
Version upgrades require performance validation.
New GPU virtualization components may introduce performance regressions. NIO adopted a phased upgrade strategy, validating performance benchmarks before allowing different HAMi components to run at different versions.
Operational changes must ensure production safety.
For online inference workloads, device plugin upgrades follow a blue–green deployment–like process: traffic is migrated first, new Pods are deployed, and old instances are gradually decommissioned.
Toolchain compatibility is critical.
Certain compiler or library features (such as pointer or address analysis) may conflict with GPU interception mechanisms. Careful trade-offs between functionality and stability are required.
NIO’s deployment of HAMi demonstrates how fine-grained GPU sharing can significantly improve infrastructure efficiency for autonomous driving workloads. By combining HAMi with Kubernetes and existing GPU allocation mechanisms such as MIG and time-slicing, NIO increased GPU utilization, reduced overall GPU hours, and improved workload throughput without compromising stability.
This hybrid resource management strategy enables NIO to support diverse AI workloads, from CI pipelines to simulation and inference—more efficiently within the same Kubernetes environment.