
Scaling machine learning infrastructure with GPU virtualization using Kubernetes and HAMi
Background
Ke Holdings Inc. is an integrated online and offline platform for housing transactions and related services based in China. To support the company’s rapidly growing AI initiatives, a centralized infrastructure team operates the shared machine learning platform used across all business units.
The team provides end-to-end compute services for model development, training, and large-scale inference, supporting both internal research workloads and production-facing AI services. As model adoption and request volume increased across the organization, GPU efficiency and workload isolation became critical platform requirements.



By the numbers
3x
improvement in platform GPU utilization
10,000+
pods running simultaneously on the platform
10,000,000+
requests processed daily across the platform
Challenge
As Ke Holdings’ machine learning initiatives scaled, the infrastructure team faced significant challenges in GPU resource management:
- Scale and complexity:
- 5 clusters across public and private cloud environments
- Thousands of GPU cards including diverse models (H200, H20, V100, 4090, H100 A100)
- Millions of daily business requests, requiring reliable, scalable infrastructure
- Over 10,000 pods running simultaneously across the platform
- Hybrid-cloud environment:Managing GPU resources across:
- Public cloud: Volcano Engine, Tencent Cloud, Ali Cloud
- Private cloud: Self-built clusters with approximately 1,000 NVIDIA GPUs
- Diverse workload requirements:The platform needed to support two distinct workload types:
- Large-scale model training**: High-memory, long-running tasks requiring full GPU access
- Small model inference**: Lightweight services requiring minimal GPU memory (1-2GB) but high throughput
Initially, the overall GPU utilization was only 13% due to the complexity of the multi-cloud environment and diverse workload requirements, which prompted the infrastructure team to seek solutions for improving cluster resource utilization.
Solution
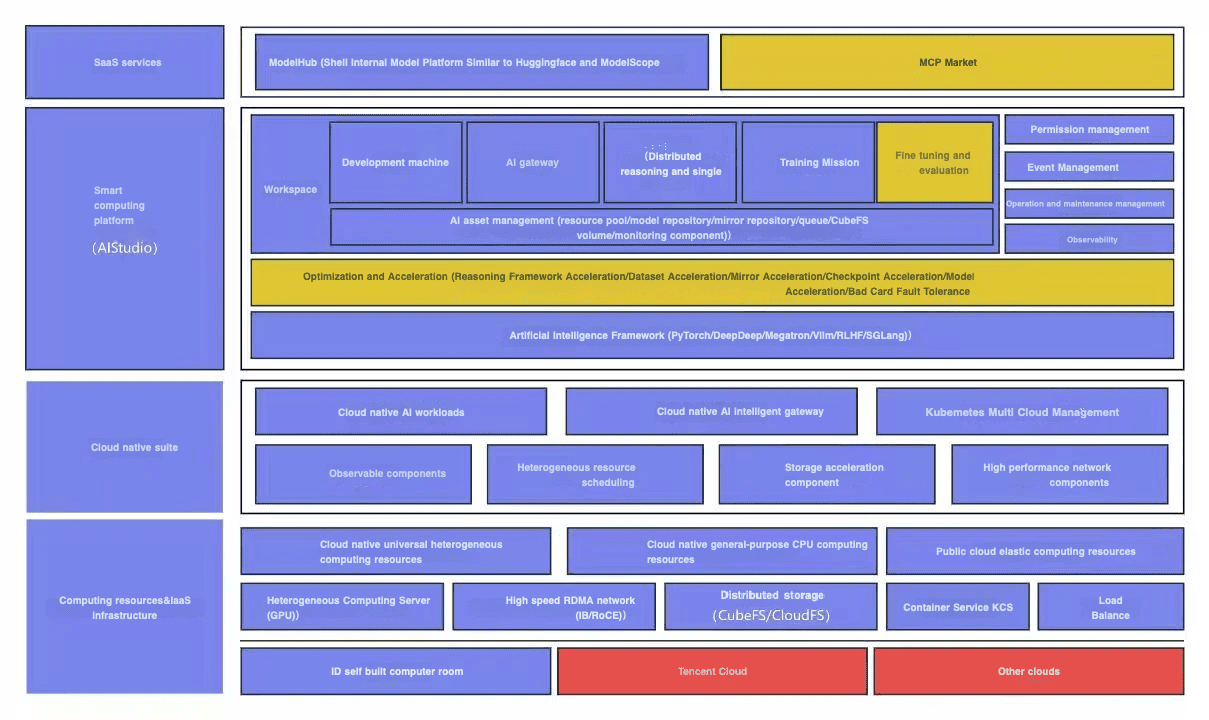
Using CNCF projects HAMi and Kubernetes as its foundation, Ke Holdings’ infrastructure team designed and implemented AIStudio, a smart computing platform that serves as the basis for the organization’s machine learning infrastructure. Leveraging Kubernetes and HAMi for GPU virtualization, it provides a unified platform that bridges upper-layer SaaS services with underlying compute resourcesIt provides the following capabilities:
- Multi-scenario support: Simultaneously supports inference services, A/B testing tasks, and training tasks, enabling diverse workloads to coexist efficiently on the same infrastructure.
- Advanced optimization and acceleration: The platform includes acceleration capabilities for inference frameworks, datasets, images, checkpoints, and models, along with fault tolerance for hardware failures (bad card handling).
- Multi-framework support: Comprehensive support for popular AI frameworks including PyTorch,DeepSpeed, Megatron, VLLM, RLHF, and SGLang, ensuring flexibility for different use cases.
- AI asset management: Centralized management of resource pools, model repositories, image repositories, queues, CubeFS volumes, and monitoring components, providing a unified interface for all AI-related assets.
To achieve this, Ke Holdings’ infrastructure team designed and implemented a GPU resource management platform built on top of Kubernetes and leveraging HAMi for GPU virtualization. Kubernetes was selected for its exceptional stability and robust cluster scheduling and management capabilities, which significantly reduce the operational complexity and maintenance overhead of large-scale clusters. Additionally, Kubernetes’ integration with the CNCF open ecosystem enables seamless adoption of various open-source solutions tailored to different use cases, such as HAMi. HAMi was chosen as it represents the most suitable GPU multiplexing and heterogeneous computing solution for AI Studio’s requirements.
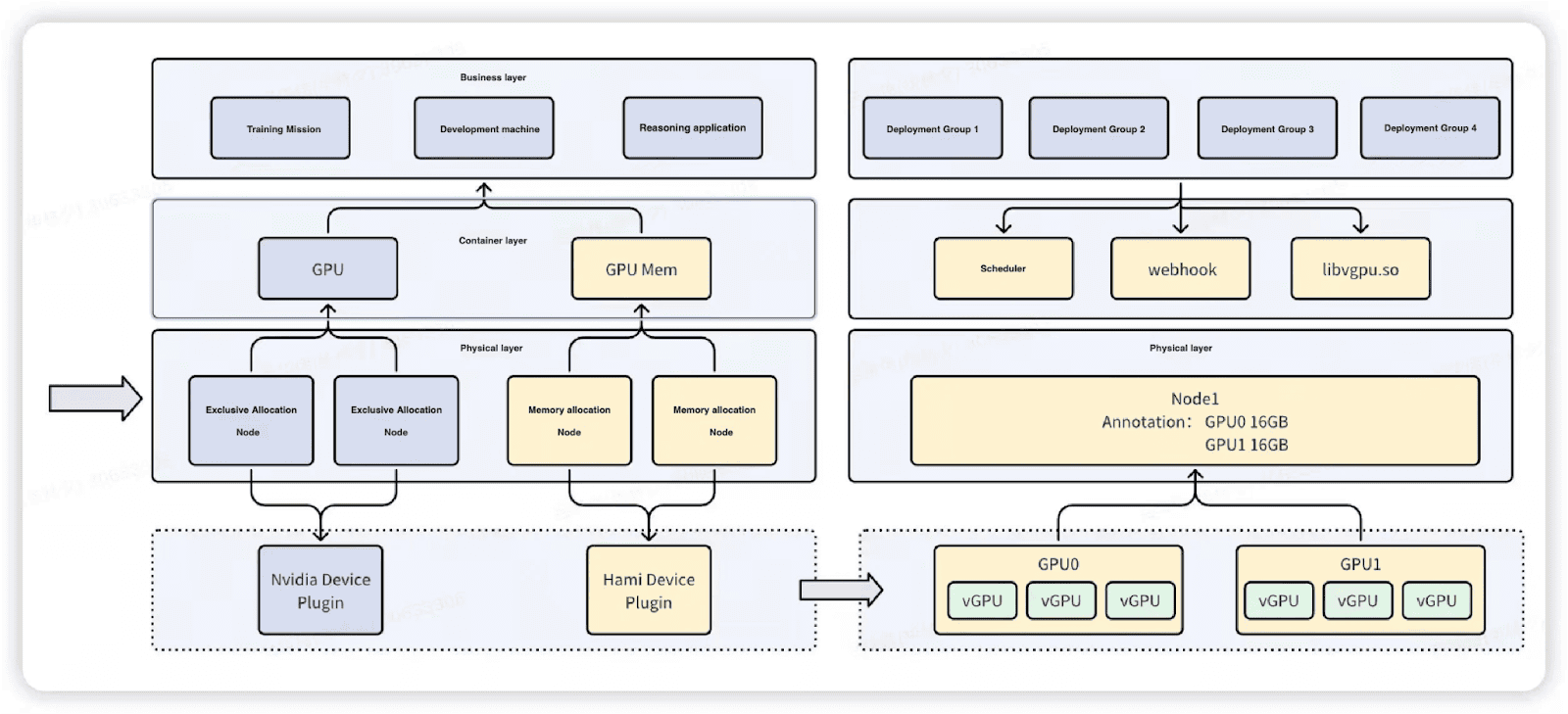
The team implemented a dual-cluster approach that separates workloads based on their resource requirements.
- GPU clusters, managed by the native NVIDIA device plugin and powered by high-performance GPUs (H200, H100), are dedicated to large-parameter LLM and training tasks that require complete GPU resources and predictable, dedicated allocation.
- vGPU clusters, managed by HAMi for GPU memory virtualization and utilizing GPUs such as H20, V100, A100 and 4090, enable fine-grained GPU memory allocation (typically 1-2GB per service) for small model inference services, such as TensorFlow-based inference workloads, lightweight language models like Qwen 8B.
This architectural separation guarantees that training jobs receive dedicated, predictable resources while inference services achieve high density through memory sharing, eliminating resource contention between different workload types and maximizing overall infrastructure efficiency.
Impact
By leveraging open-source technologies including HAMi and Kubernetes, AI Studio developed by infrastructure team has achieved:
- Stable operation at massive scale
- Over 10,000 pods** running simultaneously
- Zero downtime** during the transition and operation
- Stable operation across 5 clusters
- Seamless integration between public and private cloud environments
- Unified platform for both training and inference workloads
- Cost-effective resource management** across multi-cloud environments
- Designed efficient memory allocation strategies for diverse workload types
- Nearly 3x improvement in GPU utilization** (13% → 37%)
- Production-grade reliability** for critical business workloads
- Consistent performance under high load
- high availability and reliability for critical workloads
- Tens of Millions of business requests per day handled smoothly
The successful integration of HAMi as a foundational component demonstrates how open-source technologies can enable organizations to achieve remarkable infrastructure efficiency.
Kubernetes (k8s) serves as the underlying platform foundation, enabling stable operations of tens of millions of daily business requests and tens of thousands of pods through its robust scheduling and management capabilities. By leveraging HAMi’s GPU multiplexing and heterogeneous scheduling optimization features, the cluster’s GPU utilization has increased by nearly 3x.
Future plans
Ke Holdings’ infrastructure team continues to innovate and expand their platform on top of HAMi and kubernetes, including:
- Adopting heterogeneous devices: Plans to incorporate Huawei Ascend and other non-NVIDIA accelerators
- Cloud expansion: Integration with Alibaba Cloud to complement existing Volcano Engine and Tencent Cloud deployments
- Advanced scheduling policies for mixed workloads: such as network topology-awareness, card type specification, and UUID-based allocation