
How Infosys Optimized Telecom Data Management for a European Operator Using Kubernetes and OPA
Challenge
The client’s current landscape presents several key challenges hindering the adoption of automation and AI within the network landscape. The existence of fragmented legacy systems and a complex array of tools, lacking a unified source of truth, created significant obstacles. Furthermore, the need to eliminate data silos by unifying disparate data from diverse network systems is paramount to establishing a cohesive data environment. Achieving improved interoperability to enable seamless data exchange across various applications and services is another critical hurdle. Beyond data availability, ensuring consistent, accurate, and high-quality data across the network remains a critical challenge. The widespread presence of diverse legacy systems further complicates data consistency and integration. For e.g. the diversity of data formats originating from various network vendors like Juniper, Cisco, and Nokia leads to inconsistencies, impeding unified analysis. Moreover, evolving business requirements continuously challenges the adaptability and reliability of the data. Ultimately, data inconsistency can lead to errors in service delivery and a negative impact on customer experience.
The core objective of this program is to establish a robust and agile Centralized data hub, to address the challenges and enable seamless data sharing and interoperability across the Telco ecosystem. By integrating Open Policy Agent (OPA) as the validation and transformation engine, the aim was to enforce consistent data policies and ensure data integrity, thereby streamlining operations and fostering data-driven decision-making.
Solution
To address the challenges of fragmented data systems and inconsistent network information, the Solution centers around a Network Data Store (NDS) built on a Kubernetes-based, cloud-native architecture. This platform leverages cost-effective open-source components and containerization to ensure modularity, scalability, and resilience. This also setup allows for dynamic scaling, high availability, and efficient resource utilization.
A key architectural principle is the adoption of a configuration-driven, low-code/no-code approach. An Extraction, Validation and Transformation Framework (EVTF) using Open Policy Agent (OPA) unifies the handling of data across Telecom Domains. OPA enables the definition of policies as code using the Rego language, allowing for centralized, declarative control over how data is processed and validated. This framework decouples business logic from application code, making it easier to update rules and policies without redeploying services. It also supports reusability and consistency across different components of the platform.
By leveraging OPA and external configuration files, the platform allows users to define and modify data processing rules without writing application code. This empowers non-developers to manage data workflows and policies through a user-friendly interface, potentially built with frameworks like Swagger.
The platform consumes data from diverse vendor-specific sources through the Data Collection and the Ingestion Layer. The ingested data is then taken by the Orchestration Layer to perform the extraction and validation with the help of the Policy Engine Framework. This process ensures only accurate and reliable data enters the Network Data Store.
The platform also supports data transformation capabilities to convert vendor-specific data models into standardized industry models like TM Forum, IETF, MEF etc. This again is driven through the policy engine framework. The data standardization enables interoperability and simplifies downstream consumption by various OSS and orchestration systems.
To facilitate consumption, a microservices-based serving layer exposes data through API interfaces, enabling integration with heterogeneous systems across the OSS landscape. These microservices deployed as cloud-native components on Kubernetes ensure agility, scalability, and alignment with modern cloud architecture principles.
Solution Architecture

The Solution Architecture consists of different layers (Ingestion, Orchestration, Storage, Governance and Serving Layer) which are deployed on Kubernetes for high scalability and reliability.
Key Use cases
Network Data Validation and Transformation
- Network Data Validation
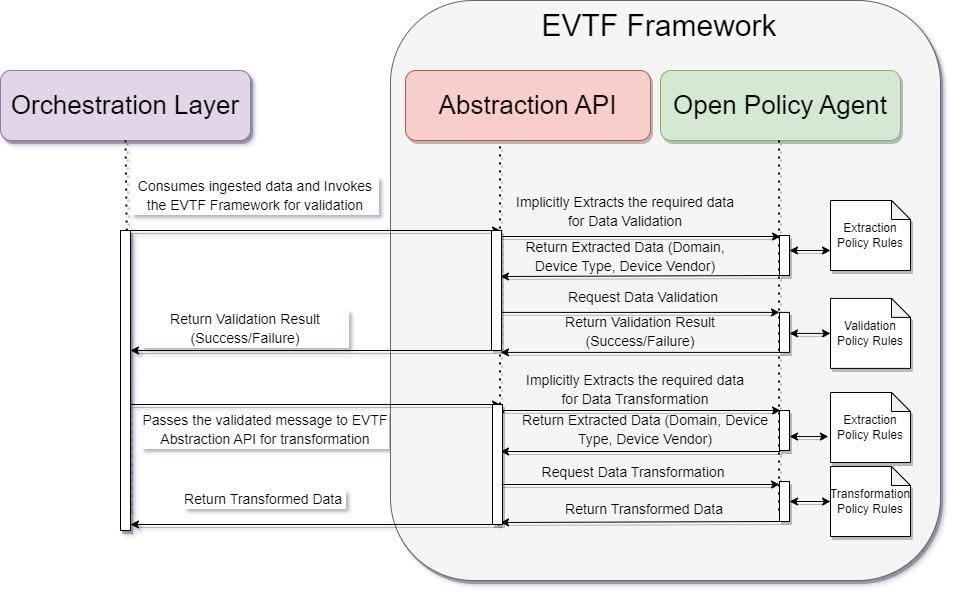
This focuses on validating incoming network data (e.g. data completeness, accuracy, and integrity) to ensure it meets business and technical standards before it is stored or processed further. The validation process is dynamic and policy-driven, leveraging OPA and an abstraction API to handle vendor-specific logic. The High-level flow of the data validation is as follows:
- Data Ingestion: Network data is collected from various sources using multiple protocols and ingested into the platform through the Collection and Ingestion Layer.
- Invocation of EVTF API from Orchestration Layer
- An abstraction API is triggered by the orchestration layer, which encapsulates business logic and performs data extraction using OPA policies.
- Based on the extracted metadata (e.g., device type, domain), the appropriate validation rules are selected and enforced using OPA
- OPA provides detailed output with information of rules that are success/failure with appropriate error messages.
- Outcome Based Routing to be performed at the Orchestration Layer
- Network Data Transformation
This focuses on transforming validated network data into standardized models to enable interoperability across OSS and orchestration systems. The transformation is governed by OPA policies and initiated through the same abstraction API. The high-level flow is as follows:
- Orchestration Layer Trigger: Successfully Validated data is picked up by the orchestration layer for the transformation into common data model.
- Invocation of EVTF API from Orchestration Layer
- The abstraction API is invoked again to extract transformation-relevant metadata using OPA.
- Based on the extracted context (e.g., vendor, domain, model), transformation rules are applied to convert the data into a domain specific common data model based on industry standards (e.g., TM Forum, IETF, MEF).
- OPA provides detailed output with the transformed data that does not require further customization.
- Outcome Based Routing to be performed at the Orchestration Layer
Impact
The implementation of a centralized data store has wide-ranging impacts across business, technical, and operational domains. It provides a centralized, scalable, and policy-driven platform for managing network and service-related data. By unifying ingestion, validation, transformation, and serving capabilities, it enhances data quality, reduces duplication, and simplifies integration with downstream systems. The use of Open Policy Agent (OPA) introduces a flexible, low-code approach to managing business rules, enabling faster adaptation to evolving needs.
Key Impacts include:
- Improved Data Consistency: Centralizes and standardizes data from multiple sources, ensuring a single source of truth for internal systems.
- Data Quality Improvement (DQI): Potentially increase DQI by ~80%, significantly reducing data errors and inconsistencies.
- Faster Decision-Making: Enables reliable and timely access to validated data, accelerating analytics and operational insights.
- Policy-Driven Design: Decouples business logic from application code using OPA, allowing rules to be updated without code changes.
- Cloud-Native Scalability: Leverages Kubernetes for high availability, scalability, and performance across ingestion and serving layers.
- Operational Efficiency: Ensure the right data is available the first time, improving efficiency by ~30% estimated across network lifecycle stages (Plan, Build, Deploy).
- Operational Cost Reduction: ~50% reduction in data management operational costs
- Service Level Improvement: Enhanced service levels by 20% through better SLA management with real-time analytics.
- Enhanced Compliance and Auditability: Supports consistent enforcement of data quality, transformation, and access control policies.
- Flexibility and Agility: Configuration-driven approach allows rapid onboarding of new use cases and data sources without major rework.
- Vendor Model Abstraction: Transforms vendor-specific data into standard models, reducing integration complexity for downstream consumers.
- Customer Retention and Experience: Boost customer retention and improve overall customer experience.
- Accelerated AI & Automation: Faster realization of AI and automation use cases i.e.~60% expected due to improved data quality and integrity.
Projects used


By the numbers
50%
reduction in data management operational costs
50%
enhanced service levels through better SLA management with real-time analytics
80%
increase in data quality index