InfluxData doubles down on developer and customer happiness with Kubernetes deployment model
Challenge
In today’s world, data continues to be generated by applications at an enormous scale. And because of this, developers keep their data and applications close to avoid unnecessary latency and cost of moving data across cloud providers or regions. As a service for its developers and the applications that they are building, InfluxData knew that a multi-cloud, multi-region strategy would be key to product and service delivery. The challenge was how to do it without having to maintain separate applications to accommodate the unique characteristics of each cloud provider.
Solution
InfluxData was able to deliver on the promise of multi-cloud, multi-region service availability by leveraging Kubernetes to create a true cloud abstraction layer allowing for the seamless delivery of InfluxDB as a single application to multiple global clusters across all three major cloud providers: AWS, Google Cloud and Microsoft Azure. Additionally, InfluxData was able to use Kubernetes as a deployment mechanism to allow each software engineer to develop, test and validate in their own production-like environment.
Impact
This Kubernetes-powered cloud abstraction layer has made it possible to write a multi-tenant application that allows customers the flexibility to control their usage and costs in a way they couldn’t by provisioning their own infrastructure. Internally, the InfluxData team has been able to onboard new hires more rapidly, write and validate code more effectively and improve productivity across engineering teams. Most importantly, they’ve been able to accelerate global availability and reduce the complexity of software delivery allowing the teams to focus more time on delivering new features to delight customers.

Projects used


By the numbers
Time to awesome
Reduced deployment time of new cloud region from 1 month to 2 days
Efficiency
A code change enters CI & gets deployed in production in under 3 hours
Scale
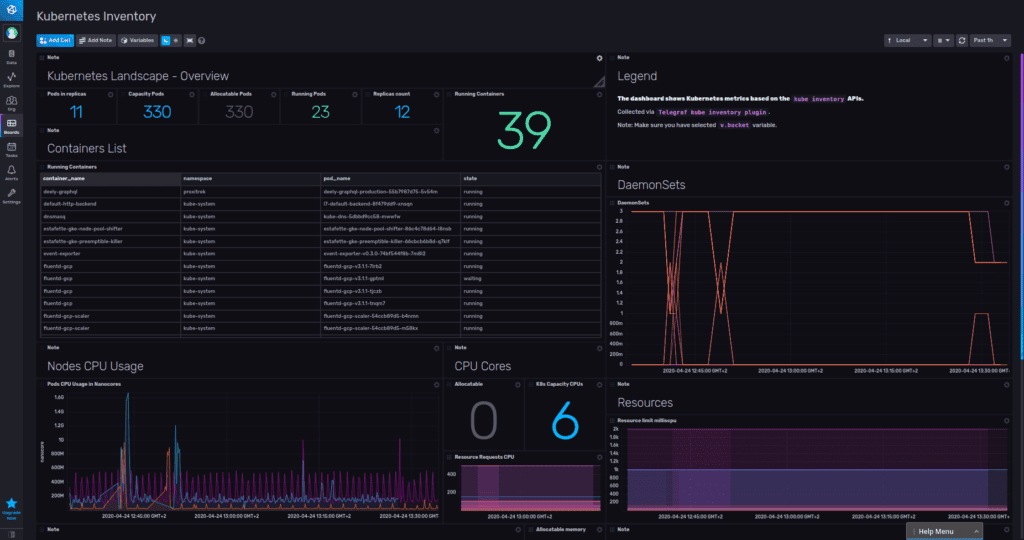
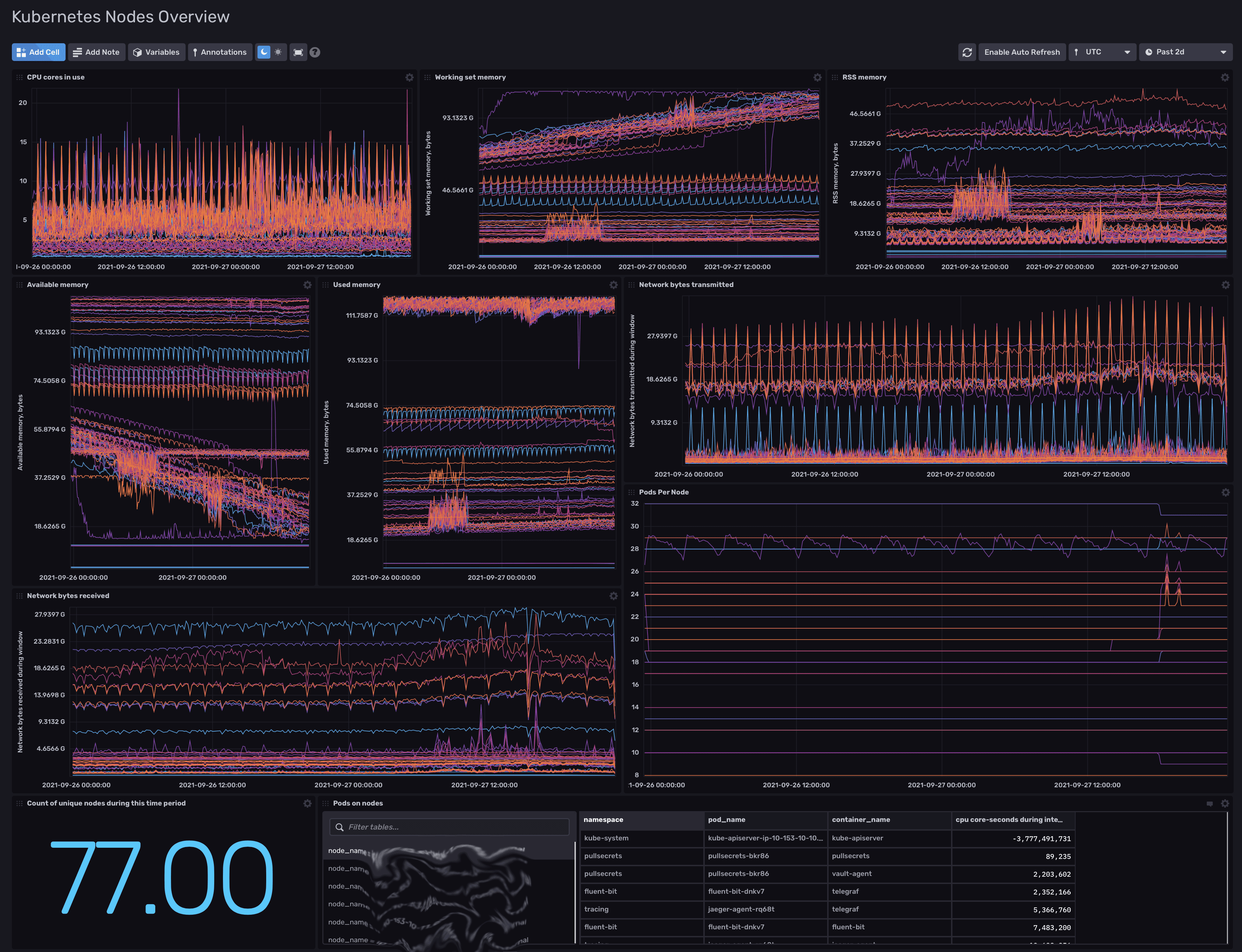
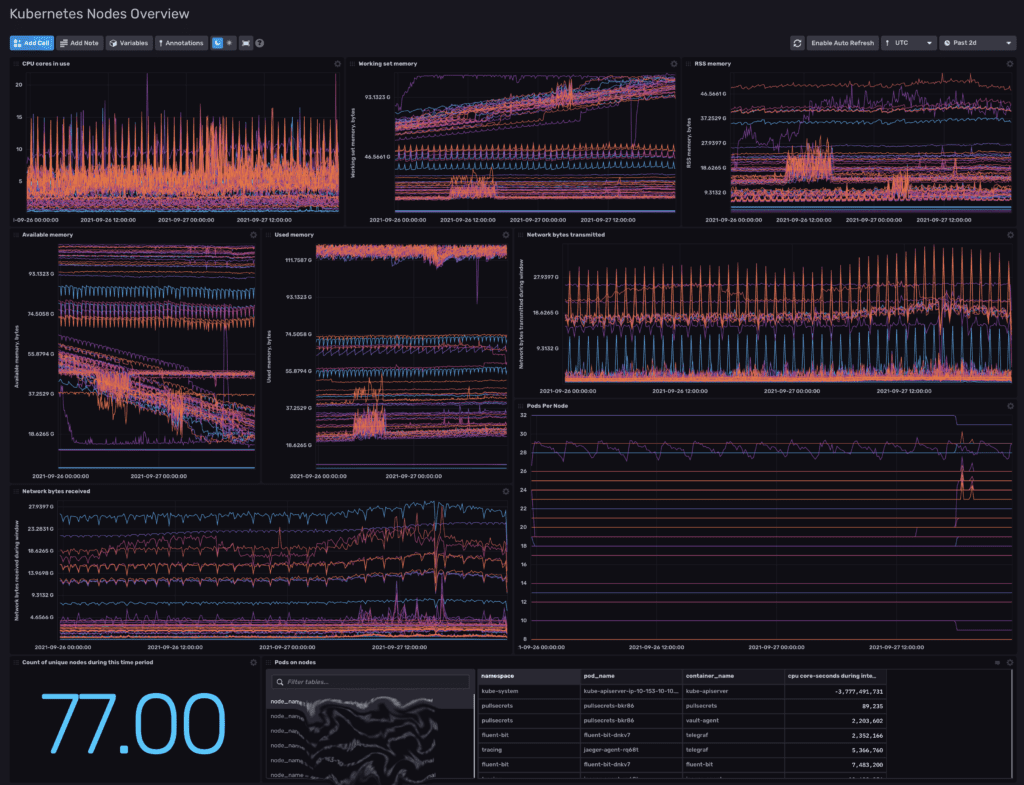
9,400+ production pods, 500+ production nodes, 17 total clusters, 11 production clusters
InfluxData is on a mission to deliver the most powerful platform for developing time series applications – one that excites and propels developers to be wildly successful

As data continues to be generated in massive volumes by and for today’s applications, the gravity of that data can become a challenge as organizations attempt to limit the costs and latency associated with moving masses of data from one point to another. Since InfluxData delivers a data platform for developers and the applications they are building, they knew that a multi-cloud, multi-region strategy would be critical. The InfluxData engineering team was challenged with the possibility of having to build a separate bespoke application for each cloud provider. At the start of this project, that number was only three, but the roadmap projected at least six more locations that needed to be supported. Maintaining three apps over time was daunting enough, adding on top of that more locations and more features was a recipe for disaster.
To optimize productivity, the reliability teams needed a standardized way to deliver resources and infrastructure while still ensuring best practices were followed. The software engineers, on the other hand, needed the ability to develop and test in a production-like environment while minimizing the impact to their own systems and those of the team.
The InfluxData engineering team knew that they needed to build a solution that could scale with the needs of the business as it added more cloud vendors and locations without adding a giant team of developers to support it. So they decided to use Kubernetes to build a cloud abstraction layer so they could stand up a Kubernetes cluster in any region on any cloud provider and then deploy the application to it at that level.
Deploying the product software via Kubernetes also made infrastructure and operations management easier. It allowed the site reliability engineering (SRE) and development teams to have a standard framework and common terminology for collaborating that streamlined and accelerated onboarding for new engineering hires. More importantly, adopting Kubernetes enabled the SRE team to enforce immutable infrastructure that reinforced best practices while enabling developers to select and provision the infrastructure they need.
Furthermore, Kubernetes has enabled the InfluxData development team to build, test, and ship code faster. The team created a hybrid remote-local development environment, “remocal” for short, that allows each developer the ability to spin up a near-production remote environment within an internal Kubernetes cluster to develop and test code changes against. Prior to the rollout of the “remocal” dev environment, each engineer would have to run a local copy of the application using Docker and Kind, resulting in lots of frustration as it bogged down machines and slowed feature development. Today, InfluxData developers have the flexibility and freedom to test their changes in real time in their own environment that parallels the production environment.
“The cloud abstraction layer and our Kubernetes deployment model allow us to dramatically accelerate the time required to roll out a new cluster with automation. The first region took at least a month to set up, but now we can spin up a new region in just two days.”
Balaji Palani, Director of Product Management, Cloud at InfluxData
InfluxData is now able to comfortably sell an elastically scalable solution that fits in perfectly with the needs of their developer customers. And as the developer’s customer reach goes further to other locations, the company has confidence that it can add those locations with ease. With InfluxDB available across providers and regions, users are able to host their data near their applications to eliminate the expense and latency that results from moving massive volumes of data across the regions.
For the InfluxData developers building the application, they no longer have to maintain separate code bases — they are just writing a single application on top of this abstraction layer, making it easier to maintain and more importantly continue to add those features from the product backlog that keeps the service useful to customers. The “remocal” solution allows any member of the development team to be able to build their features in a full environment which helps them write better code, validate changes and reduce the chance of introducing new issues into the codebase.
“Without Kubernetes, InfluxData would have had to create and maintain multiple versions of the core application, one for each cloud provider. The development teams would have lost time developing the same functionalities in parallel. Instead, with the Kubernetes-powered cloud abstraction layer, they can focus on delivering value and benefits to users in a single application.”
Rick Spencer, VP of Products, Influxdata