
Preparing for Big Billion Days: How Flipkart built a multi-tenant chaos engineering platform with LitmusChaos
This case study was the winner of the CNCF End User Case Study and Reference Architecture Contest for KubeCon + CloudNativeCon India 2026. The FlipKart story was presented onstage as a keynote on June 18th 2026.
Executive summary
Flipkart operates one of India’s largest digital commerce platforms, serving hundreds of millions of customers through a cloud native architecture built on Kubernetes. As marquee events such as Big Billion Days drive massive traffic spikes across hundreds of interconnected services, resilience and operational readiness have become critical business requirements.
To scale chaos engineering across the organization, Flipkart’s Central Reliability Engineering team adopted LitmusChaos, the CNCF-hosted chaos engineering project, and built a centralized multi-tenant resilience platform that supports both Kubernetes and virtual machine workloads. By extending LitmusChaos with new operational capabilities, integrating resilience validation into cloud native workflows, and contributing improvements back to the open source community, Flipkart transformed chaos engineering into a repeatable practice that strengthens incident readiness across the organization.
Projects used


Introduction
Flipkart, one of India’s leading digital commerce companies, operates hundreds of interconnected services across Kubernetes and virtual machine environments. During marquee events such as Big Billion Days, Independence Day Sale, and Diwali Sale, even minor disruptions can quickly propagate through the platform, making reliability a business-critical capability.
To strengthen operational readiness, Flipkart’s Central Reliability Engineering team set out to transform chaos engineering from an occasional exercise into a repeatable organizational practice. After evaluating multiple chaos engineering platforms, the team selected LitmusChaos, the CNCF-hosted chaos engineering project, as the foundation for a centralized resilience platform.
Building on LitmusChaos, Flipkart developed a hybrid multi-tenant architecture, introduced a high-availability chaos injection model, extended chaos testing to VM workloads, and created new capabilities for modeling complex operational scenarios. The resulting platform enables teams across the organization to validate resiliency, rehearse failure scenarios, and improve incident readiness before high-stakes business events.
Today, chaos engineering has become an integral part of Flipkart’s reliability strategy, helping teams move from prevention to practice and from panic to procedure.
By the numbers
- 2000+ experiment executions, ~500 unique scenarios and around 100 namespaces targeted.
- 15 central platform teams as tenants (DBaaS, KaaS, NetSvc, etc.)
- 5+ upstream contributions made back to the LitmusChaos project
- Hundreds of microservices supported across Kubernetes and VM environments
- One centralized chaos engineering platform serving multiple platform and application teams
- 6+ critical misconfigurations in alerting and deployment specs identified and remediated ahead of Big Billion Days 2024
Challenge
Reliability at Flipkart extends far beyond keeping individual applications online. The company serves hundreds of millions of customers through a large-scale digital commerce platform powered by hundreds of tightly coupled services. During major shopping events such as Big Billion Days, traffic surges place extraordinary pressure on both infrastructure and application layers.
Historically, teams relied on runbooks and operational procedures to prepare for failures. While these documents described how incidents should be handled, many of the underlying failure scenarios had never been exercised in realistic conditions. As the platform continued to grow, the Central Reliability Engineering team recognized that documentation alone could not provide confidence in operational readiness.
The team needed a way to continuously validate resilience across a diverse environment spanning Kubernetes workloads, virtual machines, networking infrastructure, service mesh components, and shared database platforms. Any solution would need to support many internal teams while maintaining strong isolation boundaries and minimizing operational overhead.
Most importantly, the team wanted to ensure that readiness for major sales events was based on demonstrated resilience rather than assumptions.
As Flipkart’s cloud native footprint expanded, the organization needed a resilience strategy that could scale alongside Kubernetes-based platforms, shared infrastructure services, and increasingly distributed application architectures. The team sought a solution that aligned with existing cloud native operational practices while enabling platform and application teams to safely validate resilience across a diverse technology landscape.
Solution
After conducting a proof of concept with Chaos Monkey, Chaos Mesh, and LitmusChaos, Flipkart selected LitmusChaos as the foundation for its chaos engineering platform. The decision was driven by LitmusChaos’s Kubernetes-native architecture, extensibility model, resilience probes, and strong alignment with CNCF technologies already used across Flipkart’s cloud native environment. As a CNCF-hosted project, LitmusChaos provided an open source foundation that could be customized to meet Flipkart’s operational requirements while benefiting from community-driven innovation and ecosystem integration.
The implementation began with a centralized LitmusChaos control plane operated by the Central Reliability Engineering team. Rather than requiring each team to deploy and manage its own chaos platform, Flipkart created a hybrid multi-tenant model that combines centralized operations with tenant-level isolation. Individual teams receive dedicated subscribers scoped only to the namespaces they own, allowing them to safely execute experiments without introducing additional infrastructure management responsibilities.
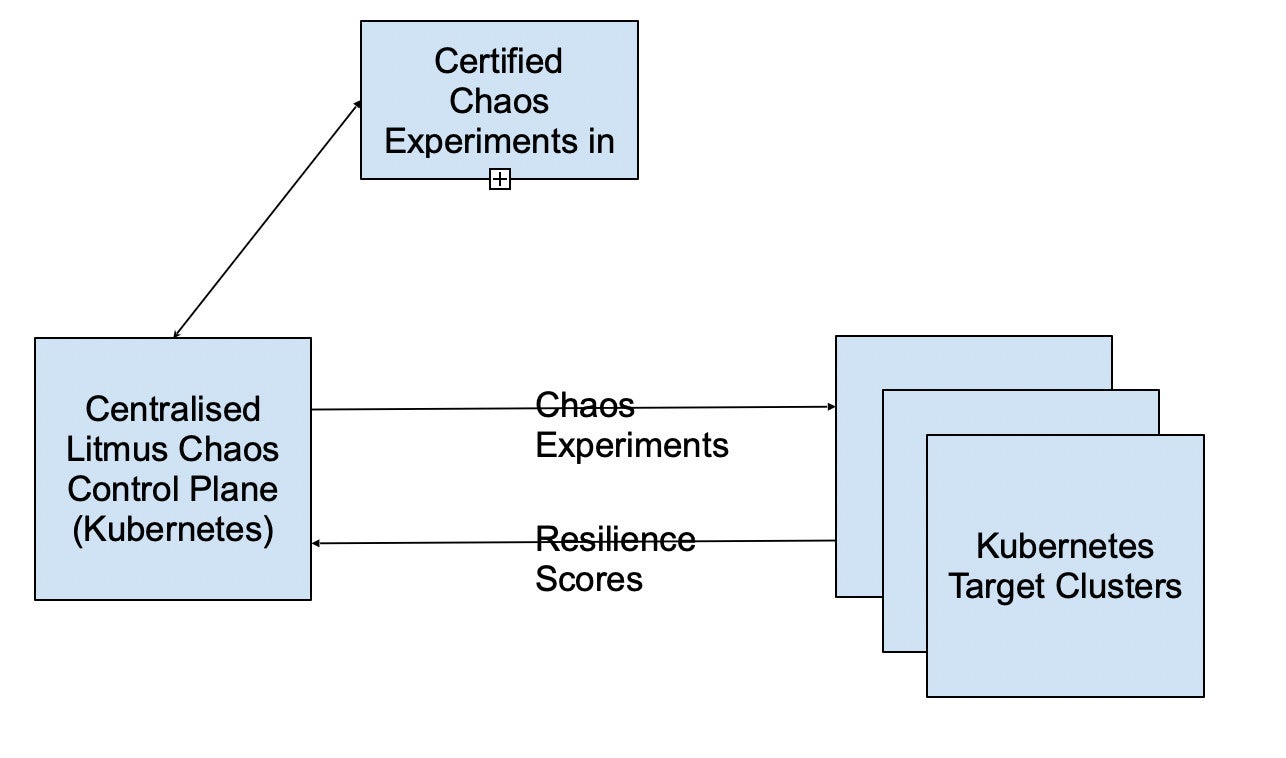
Figure 1. Flipkart’s centralized chaos engineering platform built on LitmusChaos.
This architecture enabled broad adoption while preserving governance and isolation, creating a practical middle ground between cluster-wide and namespace-wide deployment models.
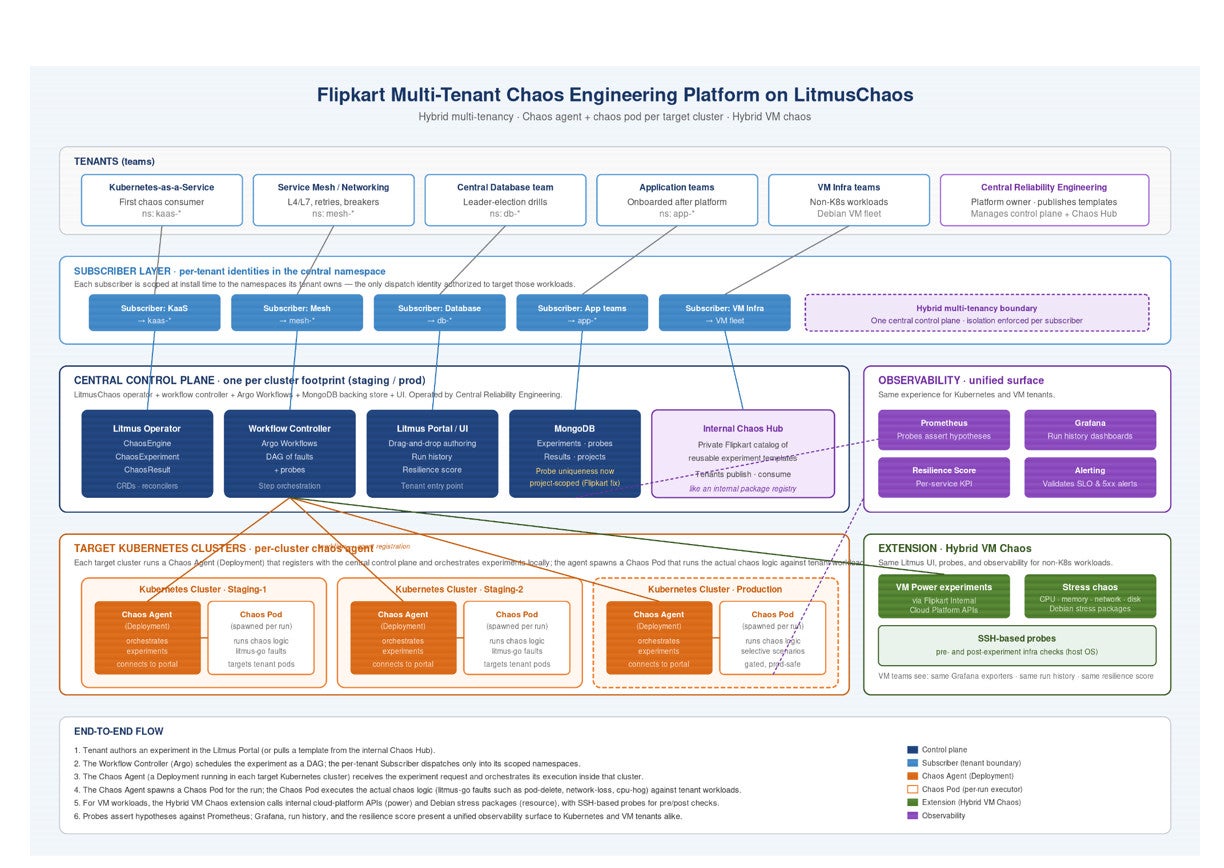
Figure 2. Centralized LitmusChaos control plane with tenant-scoped subscribers enabling safe multi-team adoption.
As adoption increased, the team encountered a challenge with the default experiment execution model. In busy staging environments, helper pods occasionally failed to schedule, creating noise in experiment results and reducing confidence in the chaos platform itself.
To address this, Flipkart developed a DaemonSet-based injection architecture. Instead of launching helper pods on demand, the platform maintains a long-lived injector on every node using a DaemonSet built around the litmus-go image. Experiment workflows communicate with the node-local injector, which executes chaos operations through parallel shell sessions.
By eliminating scheduling bottlenecks, the new model ensures that experiment outcomes reflect the behavior of the system under test rather than limitations within the chaos infrastructure.
‘Before the DaemonSet model, more than 10% of experiment runs in staging were failing due to helper-pod scheduling failures. After the switch, the experiment failure rate dropped to a near zero.
The team also found that many real-world failure scenarios required more context than traditional fault injection mechanisms could provide. A common example involved validating leader-election behavior in distributed database systems, where the active leader must first be identified before a failure can be introduced.
To support these workflows, Flipkart developed Script Runner, a new fault type built on top of LitmusChaos. Script Runner executes a user-defined script inside a user-defined container and allows its output to be consumed by subsequent stages of the workflow. This enables dynamic target selection and context sharing across multiple experiment steps, allowing teams to model realistic operational scenarios as complete workflows rather than isolated faults.
Script Runner Figure 3.1
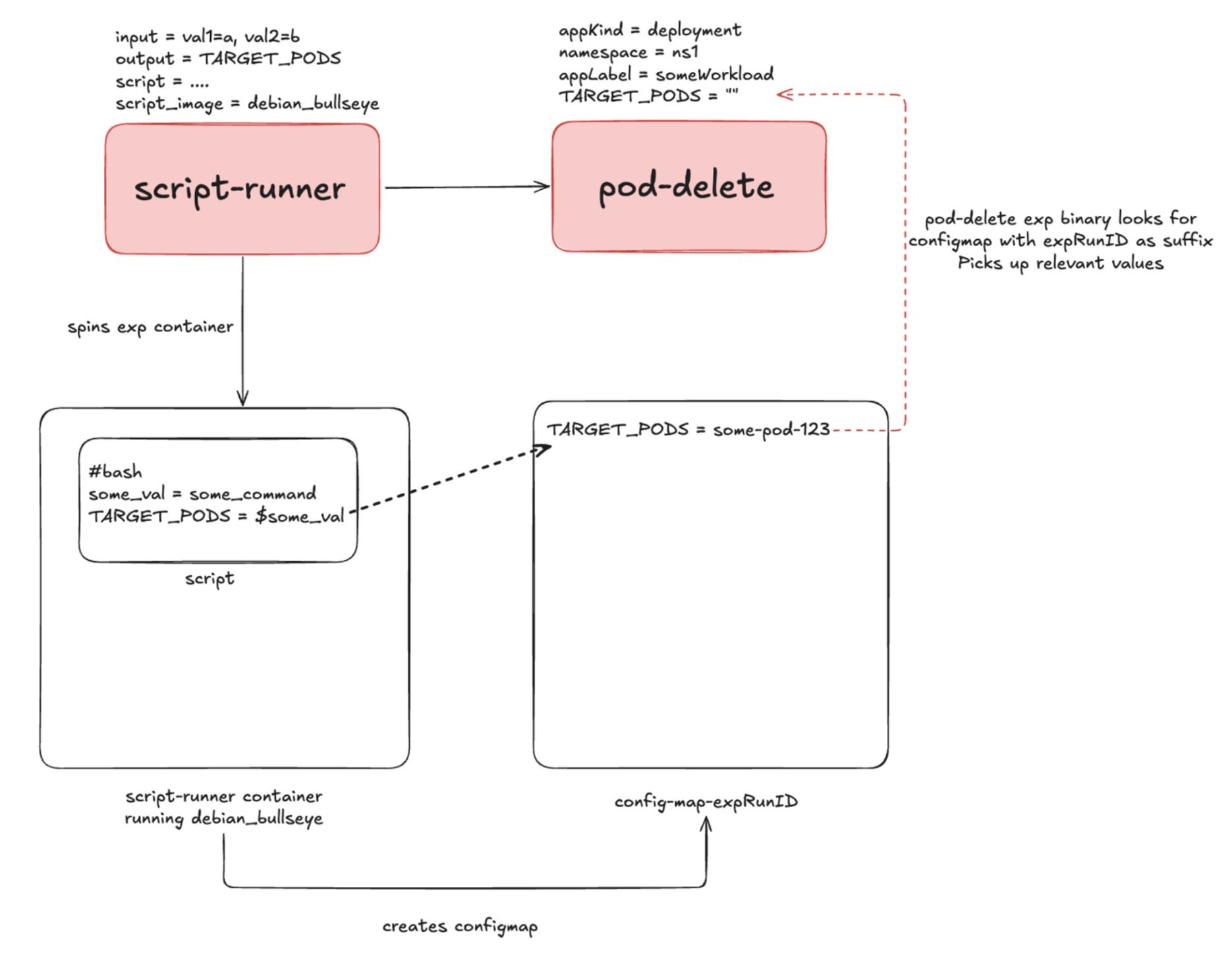
Script Runner, Figure 3.2
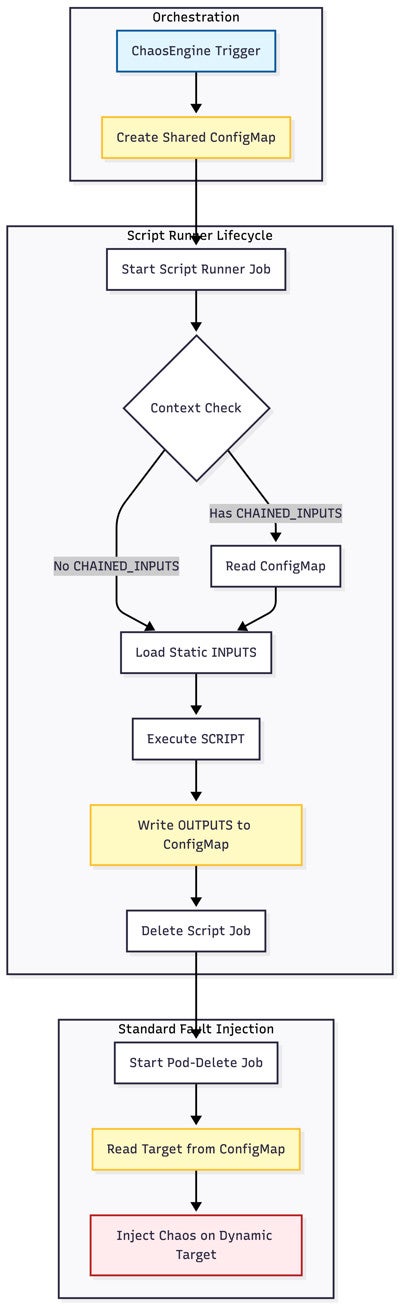
While Kubernetes forms a significant portion of Flipkart’s infrastructure, the company also operates a substantial VM footprint. Rather than introducing a separate chaos engineering toolchain, the team extended LitmusChaos to support VM environments through integrations with internal cloud platform APIs and host-level stress tooling.
The result is a unified resilience platform where Kubernetes and VM users share the same experiment history, observability dashboards, resilience scores, and validation workflows. Teams can interact with a consistent experience regardless of where their workloads run.
To further accelerate adoption, Flipkart created an internal Chaos Hub that allows teams to publish and reuse experiment templates. The rollout began with central platform teams responsible for Kubernetes, networking, service mesh, and database infrastructure before gradually expanding to application teams across the organization.
Impact
The platform has become a critical component of Flipkart’s operational readiness process. Ahead of recent Big Billion Days events, teams used chaos drills to validate alerting behavior, verify failure detection mechanisms, and identify weaknesses in deployment configurations before they could contribute to customer-facing incidents.
Experiments confirmed that CPU saturation triggered expected alerts, network failures surfaced through observable increases in 5xx responses, and monitoring systems behaved as intended under stress. The DaemonSet-based injection model also eliminated experiment failures caused by helper-pod scheduling constraints, allowing teams to focus on genuine reliability issues.
For the Central Reliability Engineering team, one of the most significant outcomes has been the ability to operationalize chaos engineering at scale across platform teams that support hundreds of downstream developers.
“Implementing Litmus chaos at the kind of scale we operate at, and enabling the platform teams that directly impact hundreds of development teams—that’s been a very rewarding journey.”
— Aditya, Software Developer, Central Reliability Team
Beyond the technical benefits, the initiative has reshaped how engineering teams think about resilience. Chaos engineering is no longer viewed as a specialized exercise performed by a small group of experts. Instead, it has become a practical mechanism for validating operational readiness and improving incident response procedures.
As teams repeatedly exercised failure scenarios, the resulting experiments evolved into the foundation for incident runbooks. This created a broader cultural shift away from attempting to prevent every failure and toward building confidence through practice.
“We moved from prevention to practice; instead of just trying to prevent issues, we actively practice handling them. And for incident response, we’ve gone from panic to procedure.”
— Khushi Tiwari, Software Developer, Central Reliability Team
That shift has had a direct impact on how teams prepare for and respond to production incidents. Chaos experiments increasingly serve as the foundation for incident runbooks, ensuring that response procedures are validated before they are needed in a real outage.
The operational discipline built through repeated chaos drills has also delivered measurable incident-response improvements. Compared with the previous year’s Big Billion Days event, mean time to detect (MTTD) infrastructure failures improved by approximately 20%, while mean time to resolve (MTTR) decreased by roughly 25%. Teams arrived at incidents with validated playbooks and rehearsed procedures, enabling faster diagnosis and recovery rather than relying on improvised responses.
“The scenarios we test become the foundation for our incident runbooks, which makes the actual incident response much better.”
— Harshith, Site Reliability Engineer
In parallel with internal adoption, Flipkart contributed multiple improvements back to LitmusChaos, including enhancements to multi-tenant probe management, custom image registry support, experiment visibility, and user interface consistency. These contributions strengthened the project for the broader community while reducing the need for long-term internal maintenance.
Lessons learned
Flipkart’s journey demonstrated that large-scale chaos engineering adoption depends as much on organizational design as technical implementation. A centralized platform combined with tenant-level isolation proved more effective than either fully centralized or fully distributed operating models.
The team also learned that meaningful resilience testing requires workflows rather than isolated fault injections. Real-world scenarios often depend on dynamic target selection, context sharing, and multi-step validation, all of which became important design principles for the platform.
Perhaps most importantly, the organization discovered that resilience is not solely about preventing failures. Repeatedly rehearsing failure scenarios improved confidence, strengthened incident response practices, and helped teams focus on recovery as a core component of reliability engineering.