
Building flexible GPU clouds with HAMi at DaoCloud
Challenge
DaoCloud operates two major cloud native platforms for AI workloads. D.run Compute Cloud is a public GPU cloud serving individual developers and small teams, while DaoCloud Enterprise (DCE) is a private Kubernetes platform for enterprise customers running both training and inference.
As GPU demand grew rapidly across both platforms, several challenges emerged:
1. Whole-card allocation led to idle capacity
- Many inference and lightweight workloads used only a fraction of GPU resources. However, GPUs were typically allocated as full cards, leaving significant portions of compute and memory underutilized and limiting how DaoCloud could package GPU SKUs.
2. Managing heterogeneous hardware was difficult
- DaoCloud needed to support mainstream NVIDIA GPUs while also integrating domestic accelerators from multiple vendors. Proprietary vGPU solutions increased licensing costs and made it harder to treat domestic GPUs as first-class citizens.
3. Enterprises required stronger multi-tenant governance
- On DCE, enterprise customers wanted shared GPU pools with department-level quotas, queue-based resource allocation, and clear isolation across teams.
4. Cloud native alignment was essential
- DaoCloud’s core strategy revolves around Kubernetes and open-source technologies. Any GPU sharing solution had to stay fully cloud native, vendor-agnostic, and compatible with existing CNCF tooling.

Projects used


By the numbers
10+
data centers across Mainland China and Hong Kong
> 80%
average GPU utilization after vGPU adoption
20 – 30%
reduction in GPU-related operating costs
Solution
DaoCloud adopted HAMi, a CNCF Sandbox project, for heterogeneous AI computing virtualization, as the unified GPU layer across both D.run and DCE. HAMi provides device virtualization, vGPU partitioning, and scheduling for heterogeneous accelerators in Kubernetes clusters.
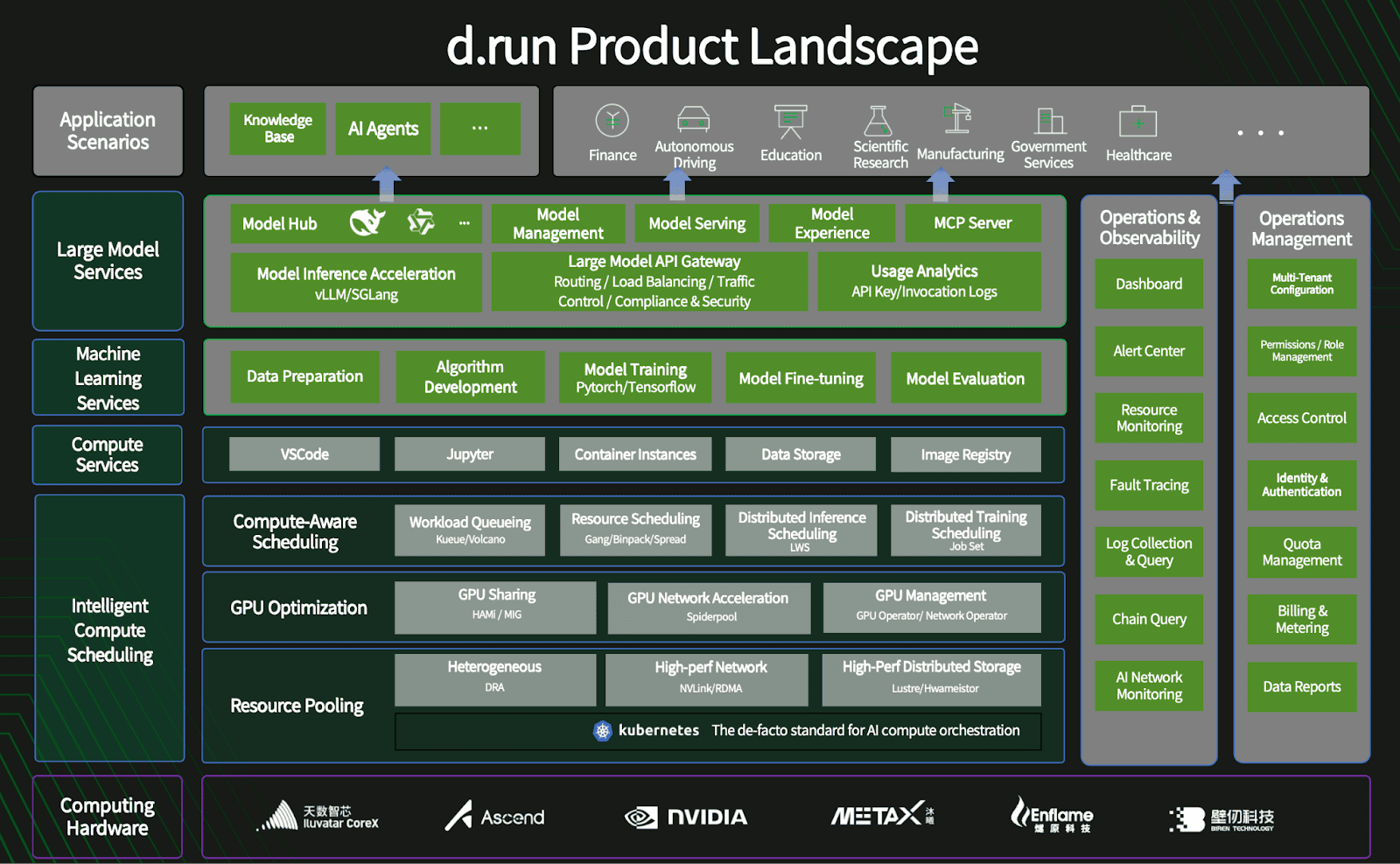
Deployment footprint
HAMi is deployed across both D.run and DCE in production environments that include a mix of DaoCloud-operated GPUs and GPUs owned by enterprise customers.
Across these combined fleets, the total GPU capacity where HAMi is actively used exceeds 10,000 cards, spanning more than 10 data centers in Mainland China and Hong Kong.
The ownership of these GPUs varies by region and tenant, but HAMi provides the unified virtualization and scheduling layer across all of them.
D.run compute cloud: vGPU SKUs for public GPU users
On D.run, DaoCloud integrated HAMi into each regional Kubernetes cluster to enable fine-grained GPU sharing and higher utilization.
vGPU slicing and controlled over-subscription
Physical GPUs are partitioned into multiple vGPU slices with defined compute and memory. Lightweight inference jobs can run on fractional GPUs, while controlled over-subscription boosts total cluster utilization.
SKU-based GPU marketplace
vGPU slices are exposed as standardized SKUs in a central marketplace. Users select GPU SKUs based on workload size rather than paying for a full card.
Multi-region deployment
HAMi powers 7 active D.run regions across Mainland China and Hong Kong, covering over 10 data centers.
In production, individual regions can scale to clusters with up to around 3,000 GPUs, depending on customer deployments and hardware availability.
Support for domestic accelerators
DaoCloud extended HAMi to support domestic GPU vendors, ensuring consistent management across NVIDIA and domestic cards under a unified abstraction layer.
DaoCloud Enterprise (DCE): a shared GPU pool for large enterprise customers
On DCE, DaoCloud built a centralized GPU resource pool using HAMi, unifying GPU capacity for multiple enterprise tenants.
Unified GPU resource pool
Enterprise users contribute and consume GPUs from a central pool that serves both training and inference workloads.
Quotas, RBAC, and vGPU integration
HAMi’s vGPU resources are integrated with DaoCloud’s existing quota and role-based access systems, allowing department- and queue-level GPU limits to be enforced at the vGPU level.
Simplified experience for AI engineers
Algorithm engineers request GPU resources through the platform without worrying about underlying hardware differences. HAMi handles vGPU mapping, ensuring a seamless developer experience.
Co-developing HAMi with the community
DaoCloud has been one of HAMi’s earliest and most active contributors. Its engineers:
- Continuously contributed real-world insights from D.run and DCE back to the open-source community.
- Collaborated upstream to improve GPU over-subscription mechanisms, node configuration management, and heterogeneous hardware handling.
- Helped maintain documentation and deployment guides to support production adoption by other cloud providers.
“With HAMi’s unified vGPU abstraction, D.run seamlessly manages both NVIDIA and domestic GPUs at scale. HAMi has not only improved our GPU utilization but also accelerated regional expansion and delivery.”
Captain, AI/LLM Infra Product Lead, DaoCloud
Impact
By integrating HAMi, DaoCloud consolidated previously fragmented GPU resources into a more unified, efficient, and scalable GPU layer across both public and private clouds.
On D.run, moving from full-card allocation to vGPU slicing has dramatically increased GPU utilization. Each region can now host far more concurrent inference services per GPU, allowing users to pay only for the resources they actually need.
On DCE, enterprises now view GPUs as part of a common pool governed by quotas and RBAC. This model simplifies GPU management, improves transparency, and accelerates onboarding for new teams and projects.
Across both platforms, HAMi’s open architecture helped DaoCloud reduce vendor dependency, supporting both NVIDIA and domestic accelerators under a unified control plane.
“HAMi is more than compatible with DaoCloud’s business, it’s something we’ve built together. As one of HAMi’s earliest contributors, we’ve witnessed its evolution from inception to maturity. HAMi now runs across both D.run and DCE, and our real-world improvements continuously flow back to the community.
HAMi and DaoCloud share the same open-source DNA, and we’ll continue contributing to HAMi to bring true vGPU technology to the world.”
Captain, AI/LLM Infra Product Lead, DaoCloud
Key outcomes
- Significant increase in GPU utilization, averaging over 80% per card after HAMi deployment.
- Reduced GPU-related operating costs by 20–30% through efficient slicing and over-subscription.
- Unified abstraction layer across NVIDIA and domestic GPUs, ensuring hardware diversity without operational complexity.
- Simpler governance with quota and role-based access integrated at the vGPU level.
- Accelerated regional expansion, as HAMi’s modular design shortened cluster deployment and delivery cycles.
- Stronger open-source collaboration, with DaoCloud actively co-developing HAMi and contributing improvements upstream.