
The Volcano community is proud to announce the launch of Kthena, a new sub-project designed for global developers and MLOps engineers.
Kthena is a cloud native, high-performance system for Large Language Model (LLM) inference routing, orchestration, and scheduling, tailored specifically for Kubernetes. Engineered to address the complexity of serving LLMs at production scale, Kthena delivers granular control and enhanced flexibility. Through features like topology-aware scheduling, KV Cache-aware routing, and Prefill-Decode (PD) disaggregation, it significantly improves GPU/NPU utilization and throughput while minimizing latency.
As a sub-project of Volcano, Kthena extends Volcano’s capabilities beyond AI training, creating a unified, end-to-end solution for the entire AI lifecycle.
The “Last Mile” Challenge of LLM Serving
While LLMs are reshaping industries, deploying them efficiently on Kubernetes remains a complex systems engineering challenge. Developers face four critical hurdles:
- Low Resource Utilization: The dynamic memory footprint of LLM inference—especially the KV Cache—creates massive pressure on GPU/NPU resources. Traditional Round-Robin load balancers fail to perceive these characteristics, leading to a mix of idle resources and queued requests that drives up costs.
- The Latency vs. Throughput Trade-off: Inference consists of two distinct phases: Prefill (compute-intensive) and Decode (memory-bound). Coupled scheduling limits optimization. While PD Disaggregation is the industry standard solution, efficient routing and scheduling for it remain difficult.
- Complex Multi-Model Management: Enterprises often serve multiple models, versions, and LoRA adapters simultaneously. Implementing fair scheduling, priority management, and dynamic routing is difficult, leading some to resort to rigid 1:1 mappings between AI Gateways and models.
- Lack of Native K8s Integration: Many existing solutions are either fragmented from the Kubernetes ecosystem or too complex for standard platform operations.
Kthena: The Intelligent Brain for Cloud Native Inference
Kthena was built to conquer these challenges. Rather than replacing existing inference engines (like vLLM or SGLang), Kthena acts as an intelligent orchestration layer on top of them, deeply integrated into Kubernetes.
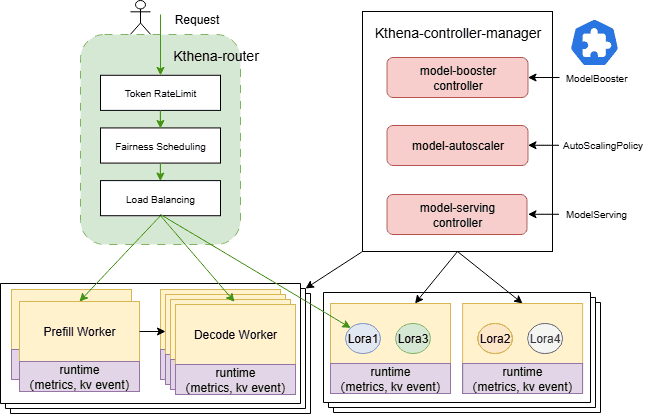
Kthena consists of two core components:
- Kthena Router: A high-performance, multi-model router that acts as the entry point for all inference requests. It intelligently distributes traffic to backend ModelServers based on ModelRoute rules.
- Kthena Controller Manager: The control plane responsible for workload orchestration and lifecycle management. It reconciles Custom Resource Definitions (CRDs) like ModelBooster, ModelServing, and AutoScalingPolicy to convert declarative intent into runtime resources.
- It orchestrates ServingGroups and roles (Prefill/Decode).
- It handles topology-aware affinity, Gang scheduling, rolling updates, and failure recovery.
- It drives elastic scaling based on defined policies.
Core Features and Advantages
1. Production-Grade Inference Orchestration (ModelServing)
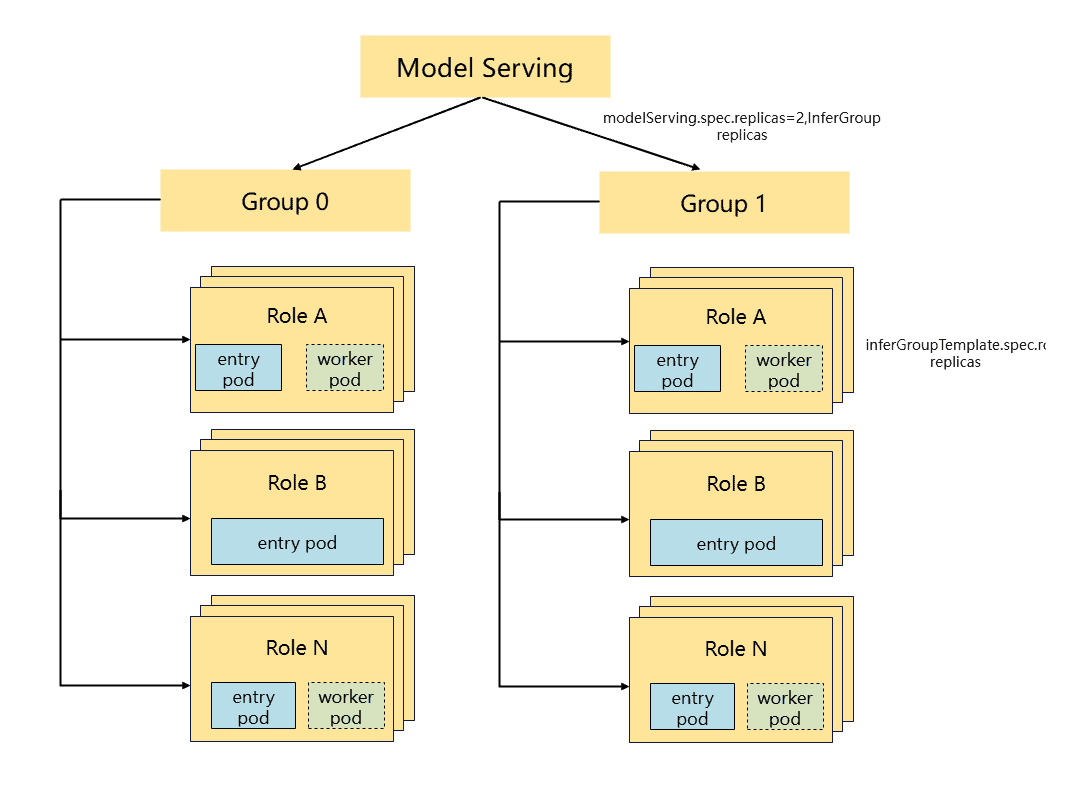
- Unified API: A single API supports diverse patterns, from standalone deployments to complex PD Disaggregation and Expert Parallelism (EP).
- Simplified Management: For example, a massive PD deployment is managed as a single ModelServing resource containing multiple ServingGroups.
- Native PD Disaggregation: Kthena optimizes hardware usage by routing compute-intensive Prefill tasks to high-compute nodes and memory-bound Decode tasks to High Bandwidth Memory (HBM) nodes. It supports independent scaling to dynamically adjust the Prefill/Decode ratio.
- Topology Awareness & Gang Scheduling: Gang scheduling guarantees that pods in a ServingGroup are scheduled as an atomic unit, preventing deadlocks. Topology awareness minimizes data transmission latency by placing related pods closer together in the network fabric.
2. Out-of-the-Box Deployment (ModelBooster)
- Templates: Provides built-in templates for mainstream models (including PD separation), automatically generating necessary routing and lifecycle resources.
- Flexibility: Covers general scenarios while allowing granular control via ModelServing for complex needs.
3. Intelligent, Model-Aware Routing
- Multi-Model Routing: OpenAI API compatible. Routes traffic based on headers or body content.
- Pluggable Algorithms: Includes Least Request, Least Latency, KV Cache Awareness, Prefix Cache Awareness, LoRA Affinity, and Fairness Scheduling.
- LoRA Hot-Swapping: Detects loaded LoRA adapters for non-disruptive hot-swapping and routing.
- Traffic Governance: Supports canary releases, token-level rate limiting, and failover.
- All-in-One Architecture: Eliminates the need for a separate Envoy Gateway by natively handling routing logic.
4. Cost-Driven Autoscaling
- Homogeneous Scaling: Scales precisely based on business metrics (CPU/GPU/Memory/Custom).
- Heterogeneous Optimization: Optimizes resource allocation across different accelerators based on a “Cost-Performance” ratio.
5. Broad Hardware & Engine Support
- Inference Engines: Supports vLLM, SGLang, Triton/TGI, and more via a unified API abstraction.
- Heterogeneous Compute: Enables co-location of GPU and NPU resources to balance cost and Service Level Objectives (SLOs).
6. Built-in Flow Control & Fairness
- Fairness Scheduling: Prioritizes traffic based on usage history to prevent “starvation” of low-priority users.
- Flow Control: Granular limits based on user, model, and token length.
Performance Benchmarks
In scenarios with long system prompts (e.g., 4096 tokens), Kthena’s “KV Cache Awareness + Least Request” strategy delivers significant gains compared to a random baseline:
- Throughput: Increased by ~2.73x
- TTFT (Time To First Token): Reduced by ~73.5%
- End-to-End Latency: Reduced by >60%
| Plugin Configuration | Throughput (req/s) | TTFT (s) | E2E Latency (s) |
| Least Request + KVCacheAware | 32.22 | 9.22 | 0.57 |
| Least Request + Prefix Cache | 23.87 | 12.47 | 0.83 |
| Random | 11.81 | 25.23 | 2.15 |
Note: While gaps narrow with short prompts, KV Cache awareness offers decisive advantages for multi-turn conversations and template-heavy workloads.
Community & Industry Support
Kthena has already attracted widespread attention and support from industry leaders since its inception.
“Open source is the lifeblood of technical innovation and the primary driver of industry standardization. As the initiator of Volcano, Huawei Cloud is proud to launch Kthena alongside our community partners.
This release marks not only a significant milestone in Volcano’s technical evolution but also underscores Huawei Cloud’s enduring commitment to Cloud Native AI. By deeply integrating with infrastructure like Huawei Cloud CCE and CCI, Kthena unlocks the full potential of diverse computing power—including Ascend—delivering superior cost-efficiency to our customers.
Through Kthena, we look forward to collaborating with global developers to build an open, thriving ecosystem that lays a robust foundation for the intelligent transformation of industries worldwide.”
—— Xiaobo Qi, Director of General Computing Services, Huawei Cloud
“Kthena further solidifies Volcano’s leadership in intelligent workload scheduling. By leveraging Volcano’s unified scheduling and resource pooling capabilities, our platform addresses diverse compute requirements—spanning general-purpose computing, AI training, and inference—within a single, unified framework.
This enables dynamic resource allocation across different scenarios, effectively eliminating resource silos. Looking ahead, we are excited to combine Kthena with Volcano’s elastic scaling and Volcano Global’s cross-cluster scheduling to drive resource utilization to new heights.”
—— Lei Yang, PaaS R&D Director, China Telecom AI
“Since its inception, Volcano has evolved in lockstep with the community to address diverse AI scenarios, establishing a comprehensive ecosystem for AI batch processing.
The launch of Kthena marks a major milestone, extending Volcano’s capabilities into the critical realm of Large Model inference. It crystallizes years of Volcano’s best practices in scheduling, elasticity, and multi-architecture support into a powerful engine for unified orchestration and intelligent routing.
By leveraging the existing Kubernetes and Volcano ecosystems, teams can achieve smarter scheduling decisions and higher compute efficiency at a lower cost. For DaoCloud, Kthena not only solves tangible inference challenges but also embodies the future of Cloud Native AI—an open, intelligent ecosystem worthy of our long-term investment and deep engagement.”
—— Paco Xu, Open Source Team Lead at DaoCloud, Member of Kubernetes Steering Committee
“Deploying and managing self-hosted LLM inference services at production scale is a complex systems engineering challenge. It encompasses the entire lifecycle—deployment, operations, elasticity, and recovery—alongside critical requirements like GPU stability, scheduling efficiency, and AI observability. Kthena is engineered specifically to address these complexities.
During Kthena’s planning phase, the Xiaohongshu Cloud Native team engaged deeply with contributors to co-design various intelligent traffic scheduling strategies. Moving forward, we will continue our collaboration on the AI Gateway front. By leveraging Xiaohongshu’s production insights, we aim to provide the community with production-ready capabilities, including granular traffic scheduling, model API management, and MCP protocol support.”
—— Kong Gu (Huachang Chen), Cloud Native Business Gateway Lead, Xiaohongshu
“After an in-depth evaluation of Kthena, China Unicom Cloud is impressed by its forward-looking design. We are particularly excited about its joint scheduling capabilities with Volcano.
Features like topology awareness and Gang Scheduling directly address the critical efficiency and reliability challenges inherent in large-scale distributed inference, offering a promising solution to complex scheduling bottlenecks.
We believe Kthena’s superior low latency, high throughput, and intelligent routing will provide the open-source community with a truly production-ready solution, empowering developers to build and manage cloud native AI applications with greater efficiency.”
—— Zhaoxu Lu, Team Lead, Intelligent Computing Center, China Unicom Cloud
“Openness and collaboration fuel innovation. Within the CNCF ecosystem, we are dedicated to driving infrastructure towards an ‘AI Native’ future.
By launching the Kthena sub-project, the Volcano community applies its proven expertise in batch computing—like topology awareness and Gang scheduling—to online LLM inference. Kthena introduces essential cloud native scheduling primitives, enabling complex LLM workloads to run efficiently as first-class citizens in Kubernetes.
We invite developers worldwide to join us in refining this critical infrastructure and accelerating the AI Native era.”
—— Kevin Wang, Volcano Maintainer, CNCF TOC Vice Chair
Start Exploring Kthena Today
This is just the beginning. We plan to support more efficient scheduling algorithms and broader best practices for large model deployment.
- GitHub Repository: https://github.com/volcano-sh/kthena
- Official Website: https://kthena.volcano.sh/
- Community: Join our Slack
Join us to unlock the full potential of Cloud Native LLMs!