








Platform engineering is a discipline that aims to increase the productivity of software engineering teams by designing, building, and maintaining internal platforms that abstract underlying infrastructure complexity and provide self-service capabilities. Kubernetes-based platforms are often complex multi-Open Source Software (OSS) integrations; thus, platform engineering is not a “declare once and forget it” process. It requires continuous dependency maintenance and strategies for inevitable breaking changes.
In this blog post, we’ll go over the integration of fourteen OSS projects to maintain the platform that is built on top of a Kubernetes cluster. We explore the following challenges:
- Catching up with software upstream changes
- Controlling the supply chain
- Keeping up with Kubernetes upgrades
- Maintaining Helm chart upgrades
- Maintaining Applications with persistent data
- The necessity of runtime validation
Catching Up With Software Upstream Changes
For this article, we have analyzed the last three years of releases for the following OSS projects: argo-cd, knative-serving, istio, harbor, keycloak, cloudnative-pg, gitea, ingress-nginx, grafana, sealed-secrets, kyverno, prometheus, external-dns, and cert-manager.
Based on our experience and analysis, you can expect between 2-5 major upgrades, 43-52 minor upgrades, and 276-327 software patches every year. That’s nearly an update a day!
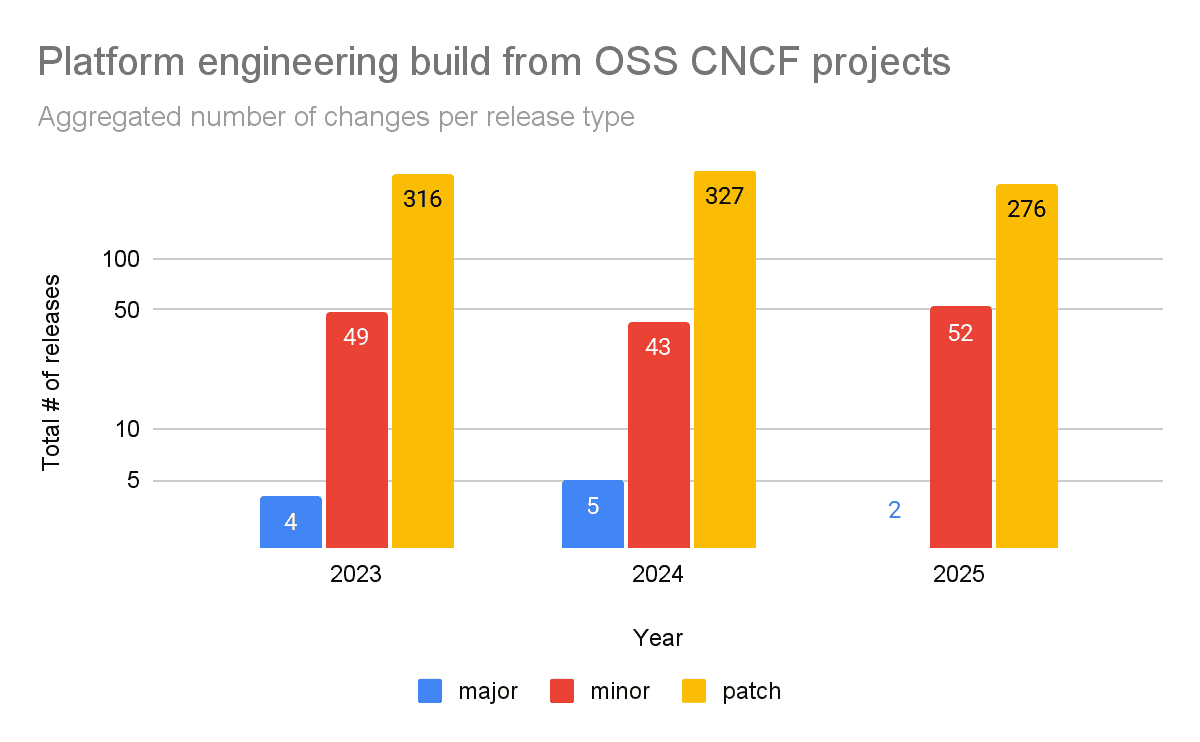
A significant challenge arises from the responsibility of maintaining a robust security posture. Every day, a number of security vulnerabilities are discovered. They are addressed in upstream projects that your platform needs to apply as security patches. This significantly contributes to the number of patches from the diagram above. Such changes must be monitored and quickly adopted into your platform.
In line with this, a project or its chart maintainers may opt to stop maintaining previous versions and only provide an upgrade path towards the latest major release, which effectively marks an older major version as end-of-life. Even if you only intend to adopt a security upgrade, you are practically forced to follow the maintained version.
A significant amount of maintenance effort can be automated, particularly when it comes to identifying new application versions. Helm chart releases are organized in repositories and registries, whereas binary software releases are found on GitHub using their API. This makes essential download and upgrading tasks a good candidate for being delegated to scripts that open a pull request accordingly. Automation addresses the short-term end-of-life problem.
Controlling the Supply Chain
Recent years taught us that critical parts of the supply chain, such as container registries or Helm chart repositories, can be subject to rate limiting or disruptive changes like deprecation on short notice by either OSS communities or software vendors. Adopting those changes and ensuring platform instances are using the new platform version is often impossible in such a short time frame.
Maintaining a platform-dedicated container registry cache and a mono repository with Helm charts makes code-breaking changes transparent to users and buys platform engineers time to adapt. Similarly, this provides platform administrators the time to plan for an upgrade.
Keeping Up With Kubernetes Upgrades
While each Kubernetes minor version is maintained for 12 months, cloud platform providers often push for faster adoption, and expectations are set that users will keep up with the latest version. A new Kubernetes version may come with deprecated APIs that your Helm chart relies on, making upgrading your Helm chart an inevitability.
A Kubernetes conformance smoke test enables you to discover potential breaking changes. Render all manifests that the platform would deploy and statically test the entire output against the Kubernetes OpenAPI schema, including all added custom resource definitions (CRDs).
Maintaining Helm Chart Upgrades
With a platform as a product mindset, you own the full impact of what you deploy. Community Helm charts may reduce the number of manifests you need to define, but they do not remove the responsibility of understanding exactly what is being introduced into your Kubernetes cluster.
In practice, simply reviewing the Go template code is rarely sufficient to assess the effects of a new chart version on your platform, so other strategies need to be applied. Some of the Helm charts upgrades are delivered with modifications to immutable Kubernetes properties, such as Deployment’s label selector, complicating maintenance and upgrades further.
By implementing a custom platform operator capable of managing changes to immutable Kubernetes properties, you can ensure a smooth upgrade. Detect potentially disruptive changes before they affect production environments by analyzing rendered Helm chart manifests: current version vs new version. The diff can also be performed against a running cluster, performing a dry run before applying changes.
Maintaining Applications With Persistent Data
Many Helm charts are delivered with dependencies that simplify deployment by bundling essential components such as SQL databases and key-value stores. These maintain the state on their dependent apps, and frequently require persistent volumes to do so.
For example, Helm dependencies declare manifests to deploy a PostgreSQL database service, but do not come with any operator that is aware of database lifecycle management (upgrades, migrations, replication). This “batteries-included” approach simplifies the initial deployment, but is a technical debt for platform operations.
To address these challenges, you must review the included dependency charts to check if they maintain application-critical data. Avoid using SQL databases provided as Helm chart dependencies. Instead, deploy database services via database operators, such as CloudnativePG, that are aware of both Kubernetes storage limitations (e.g., volume attachments) and database lifecycle requirements, such as migration workflows on major upgrades.
The Necessity of Runtime Validation
A Helm chart upgrade that deploys without errors does not necessarily ensure the application still behaves as expected. This goes regardless of whether it relies on core manifests alone or additional custom resources. Code-breaking changes (whether in the chart or the application itself) often will not surface through simple manifest validation. Resources may appear healthy while silently diverging from their previous configuration, and even logs may fail to expose integration issues.
This makes robust quality assurance essential, particularly through automated integration tests where possible. Automated tests should operate on a running cluster to ensure that all services can contact their dependencies and that endpoints are exposed as expected.
Long-term cluster monitoring is essential as well. Issues like applications OOMKilled, CPU throttling, or running out of disk space often occur only after days or even weeks, depending on workload patterns. Detecting these problems early relies heavily on well-designed Prometheus rules. The Kube-Prometheus-Stack offers a solid foundation, but adding application-specific rules and alerting conditions can provide more insights.
Final Thoughts
Once you commit to delivering a platform, you become responsible for the lifecycle of components. The open source community that develops essential applications usually responds quickly to compatibility and security issues; however, these changes still need to be integrated into your platform. You need to prepare for the operational cost, upgrading parts, and replacing components that are no longer maintained. The upside of coordinating this effort in your platform is that it provides relief to development teams from having to perform all the same work simultaneously. A high degree of automation and development of dedicated platform management components and tools ensures long-term maintainability.
Additionally, feedback and upstream contributions are an integral part of using open source software that ensures other users in similar scenarios can benefit from the experience and that upstream projects remain healthy.