


At STCLab, we operate high-traffic SaaS platforms that require real-time traffic control and bot mitigation. . Handling millions of concurrent connections and identifying malicious bots in real-time requires exceptional infrastructure stability. To achieve this, we rely on Istio.
While Istio offers a vast ecosystem of features, this post focuses on just a select few capabilities that have proven most critical in our production environment. Whether you are currently evaluating Istio for adoption or looking for practical use cases, we hope these selected insights serve as a helpful guide.
Why Istio?
Istio operates as a control plane managing Envoy proxies deployed alongside your containers. Every Istio configuration (VirtualService, DestinationRule, AuthorizationPolicy) translates into Envoy’s native config.
This matters for two reasons: Istio’s abstractions handle most use cases elegantly, and when they’re not enough, EnvoyFilter gives direct access to Envoy’s capabilities. We use both throughout our infrastructure.
Preserving real client IPs with Proxy Protocol
For our bot mitigation platform, accurate client IPs are everything. Without them, bot detection accuracy drops significantly.
The challenge: when traffic passes through AWS NLB, the original client IP gets lost. We solved this with Proxy Protocol via EnvoyFilter:
Note: For a deeper technical dive into source IP preservation and network topology configuration, we highly recommend referencing the Istio official blog post: Configuring Gateway Network Topology.
We also prioritize X-Envoy-External-Address over X-Forwarded-For for security-critical operations. Unlike XFF, this header is set by Envoy itself and cannot be forged by external clients.
IP based access control
Internal APIs like Swagger docs need protection. We use AuthorizationPolicy to restrict access to office IPs:
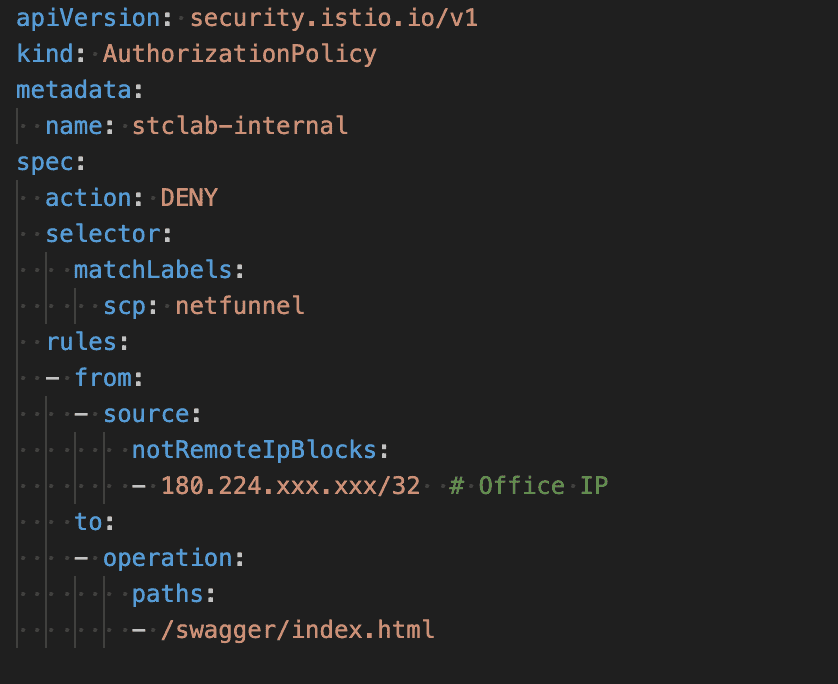
The DENY action with notRemoteIpBlocks creates a whitelist only explicitly allowed IPs can access. Simple and effective.
Query parameter-based routing
Our internal traffic management platform manages queue states in-memory. Each tenant’s requests must hit the same backend instance to maintain consistency.
We implemented explicit routing via query parameters:
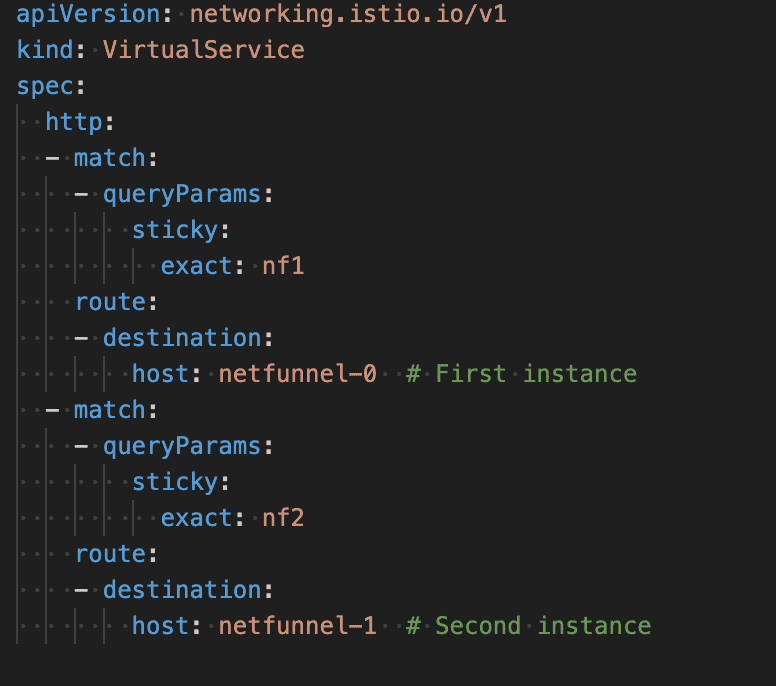
Why this approach over automatic hashing:
This was coordinated with our application team. Clients specify their target instance via the sticky parameter, giving them:
- Deterministic routing: Clients know exactly which instance handles their requests
- Debug isolation: Route problematic tenants to specific instances for investigation
- Graceful migration: Move tenants between instances during maintenance
Alternative: Consistent Hash
For services without strict consistency requirements, we use Consistent Hash:
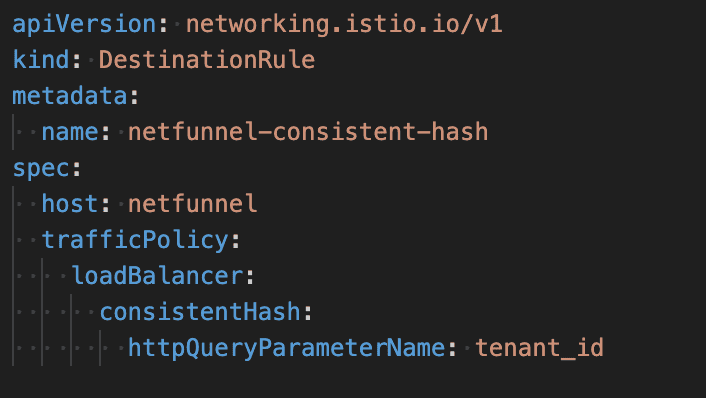
This automatically routes requests with the same tenant_id to the same backend. We use explicit routing for our virtual waiting room platform’s core queue service and Consistent Hash for auxiliary services.
Automatic failure isolation with Outlier Detection
A single unhealthy pod can degrade the entire service. We use Outlier Detection to automatically eject failing instances:

How it works:
- Eject pod after 5 consecutive 5xx responses
- Ejected pods stay out for 30 seconds minimum
- Never eject more than 50% of pods (availability protection)
Real world impact: During a recent deployment issue where one pod entered a crash loop, Outlier Detection removed it from rotation within 50 seconds. Traffic shifted to healthy pods with zero manual intervention.
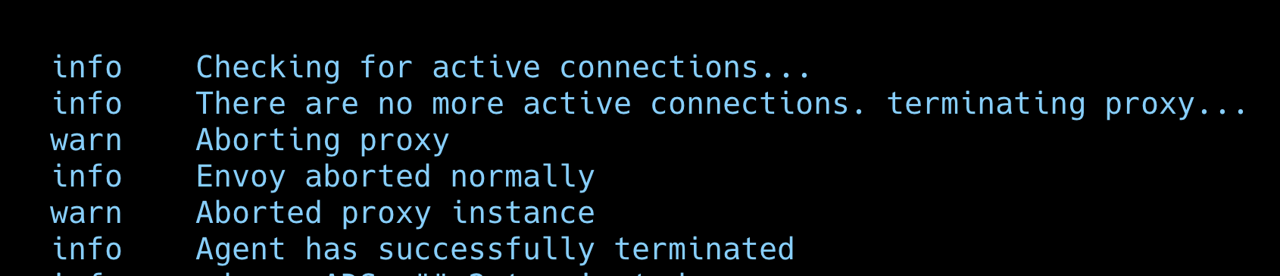
Graceful shutdown for long-lived connections
Our gateway handles connections lasting more than 10 minutes. Abruptly terminating them during deployments causes test failures.
The critical rule: terminationGracePeriodSeconds must exceed terminationDrainDuration.
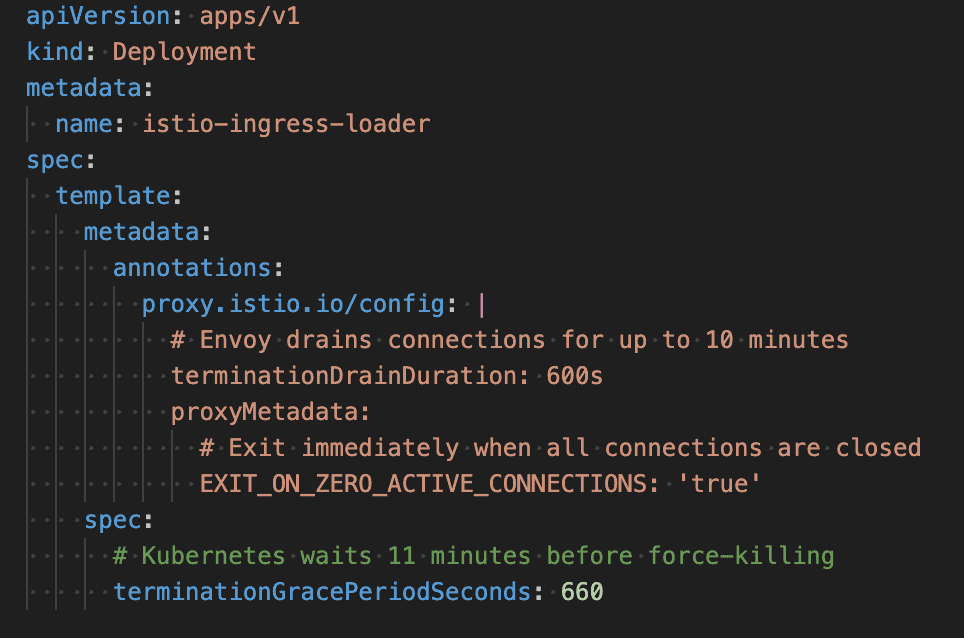
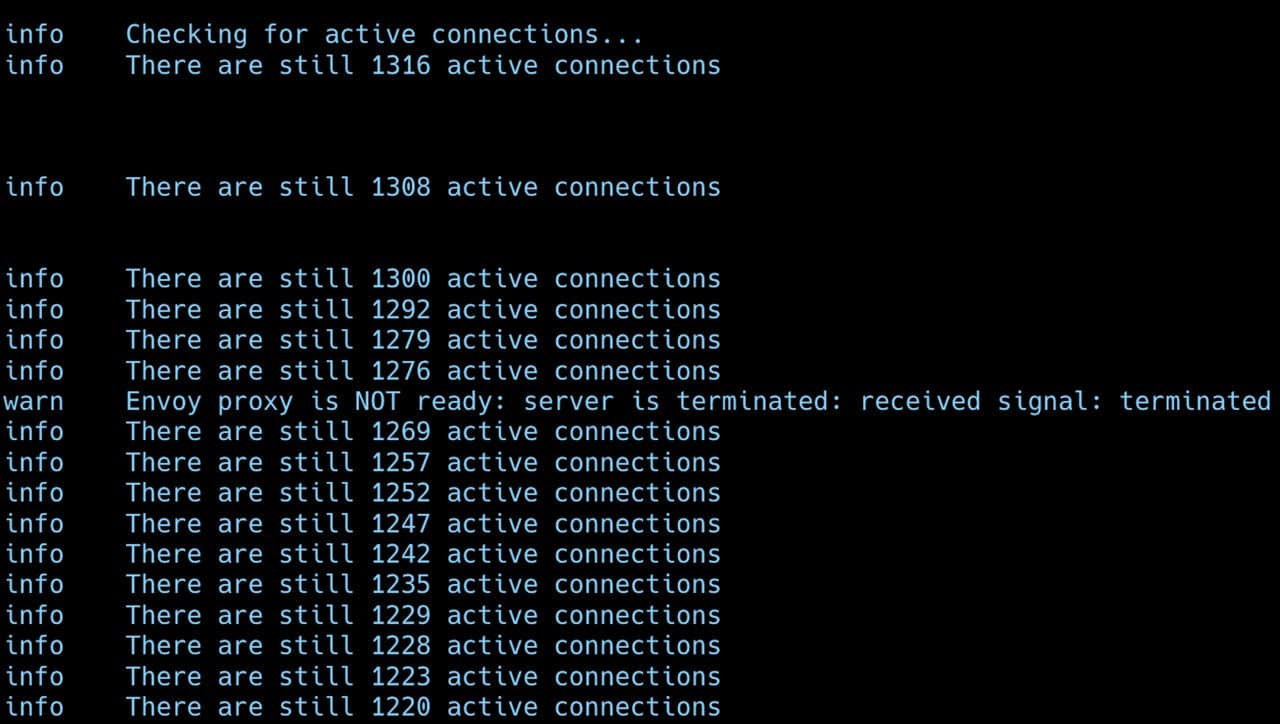
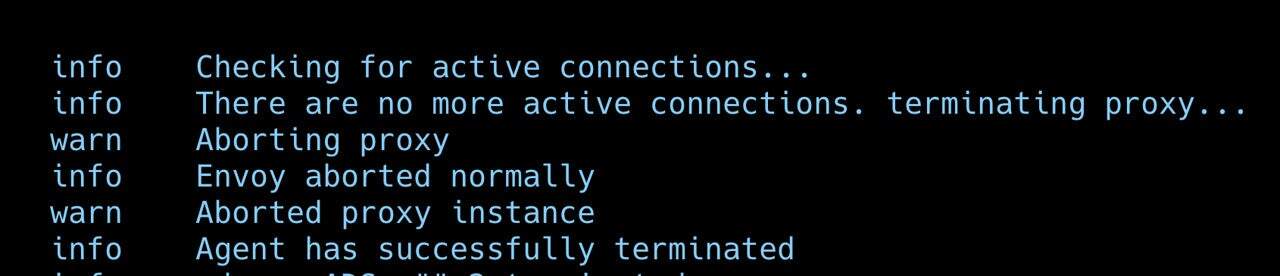
The shutdown sequence:
- Pod receives termination signal
- Envoy stops accepting new connections, fails health checks
- Existing connections continue for up to terminationDrainDuration (600s)
- With EXIT_ON_ZERO_ACTIVE_CONNECTIONS, pod exits early if connections drain quickly
- Kubernetes sends SIGKILL after terminationGracePeriodSeconds (660s)
Results:
- Zero connection drops during deployments
- Load tests complete successfully during rolling updates
Key takeaways from production
Here are a few operational tips to keep in mind as you scale with Istio:
- Start simple: Don’t enable every feature on day one. Add complexity (like mTLS or tracing) only when the business case justifies the technical cost.
- Watch metric cardinality: Envoy generates massive telemetry data that can crash Prometheus. Tune configurations to collect only the metrics that matter.
- Handle EnvoyFilter with care: It unlocks powerful capabilities but is fragile during upgrades. Rigorous documentation and compatibility testing are non negotiable.
Conclusion
Istio has a learning curve, but for our high traffic platforms, the control it provides is worth the investment. The features we’ve shared Proxy Protocol for client IPs, AuthorizationPolicy for access control, flexible routing strategies, Outlier Detection for resilience, and graceful shutdown coordination have become essential parts of our infrastructure.
If you’re running services where traffic management, security, and reliability matter, Istio is worth exploring.