
Introduction
Role-Based Access Control (RBAC) is one of the most important security features in any cloud native platform. It determines who can do what inside the Kubernetes Cluster, helping teams give the right access to the right people, keep systems safer, and make permissions easy to manage.
Learn how to apply Role-Based Access Control (RBAC) to manage database workloads safely and effectively on Kubernetes. Using Percona Everest as an example, this post demonstrates how to implement roles for developers, DBAs, and operators — with step-by-step policies and best practices.
In the Kubernetes ecosystem, RBAC is usually discussed in the context of pods, nodes, or cluster-level resources, and when it comes to stateful workloads, especially databases, RBAC becomes even more critical. Databases carry sensitive data, backups, and credentials, so you want developers, DBAs, and operators to have the right level of access, no more, no less.In this post, I’ll use a database management platform running on Kubernetes as a case study to walk through RBAC concepts. Specifically, I’ll use Percona Everest, an open-source platform for running and managing databases on Kubernetes. Everest provides a UI, CLI, and API to create and manage PostgreSQL, MongoDB, and MySQL clusters. I will show examples using Everest’s RBAC, but the principles apply to any Kubernetes database platform.

Note: Kubernetes already includes RBAC to manage access to cluster resources like pods and nodes. Platform like Percona Everest build on top of this their own RBAC layer for database-specific actions (clusters, backups, restores), and this post focuses on that layer.
Why RBAC is important for managing databases
When databases run in Kubernetes, RBAC keeps access safe and simple. It helps by:
- Only authorised users can make changes like creating clusters or deleting backups.
- Letting developers view logs without accidentally dropping a database.
- Defining permissions once and applying them consistently across all workloads.
How RBAC works in Kubernetes-based platforms
Most platforms follow a simple workflow:
- The user makes a request (for example, create a PostgreSQL cluster).
- The platform checks the request against an RBAC policy file (commonly stored in a ConfigMap or database).
- If the role allows the action, it proceeds.
Otherwise, the request is blocked with an authorisation error.
These checks happen every time someone tries to do a protected action, not only at login. This way, if RBAC rules change, the updates apply right away.
Here’s a conceptual diagram you can imagine:

Enabling RBAC
Before policies can take effect, RBAC usually needs to be enabled at the platform level. Most database platforms that run on Kubernetes provide a simple way to do this.
For example, in Percona Everest, you can enable RBAC with:

Once RBAC is enabled, the platform begins enforcing the rules from the policy file.
Why Everest implements its own RBAC layer?
Here, we’ll answer a question that many of you might have: why add another RBAC layer?
While Kubernetes already provides a native RBAC system to control access to cluster resources, many platforms built on top of Kubernetes introduce an additional RBAC layer at the application level. This extra layer governs what users can do through the platform’s interface, API, or the CLI, such as creating, backing up, or deleting database clusters, without granting direct access to the Kubernetes cluster itself.
This approach keeps things safer, and users get only the permissions they really need. It is a common pattern across Cloud-Native Projects such as Percona Everest and ArgoCD, which all use an extra RBAC layer to manage user actions at the application level while Kubernetes RBAC continues to secure the cluster and its resources.
Inside RBAC policy (Everest Example)
In Percona Everest, RBAC rules are stored in a ConfigMap (everest-rbac) inside the system namespace. Policies are defined in simple CSV format:

- p → a policy rule (what a role can do with a resource).
- g → grouping rule (assigns a user to a role).
In this example, the role role:readonly can read database clusters across all namespaces, and the user Alice is assigned to that role.
A typical RBAC policy has four parts:

- Role → e.g., role:readonly, role:dbadmin.
- Resource type → e.g., namespaces, database-clusters, backups.
- Action → read, create, update, delete (or * for all).
- Scope → one namespace, all namespaces, or a specific object.
Example:

This means the dbadmin role can delete backup storage across all namespaces.
Common RBAC roles in practice
Different teams need different access levels. Here are simple examples of RBAC in a Kubernetes database environment:
Example 1: Namespace admin
Here is what a policy looks like for a namespace called namespace-a

When we put it all together, this role can:
- Create and manage database clusters
- Handle backups and restores
- Manage credentials and storage
- Set up monitoring
…but only in namespace-a.Now let’s assign this role to a user called Alice:

This means Alice can fully manage everything in her namespace, without affecting other namespaces.
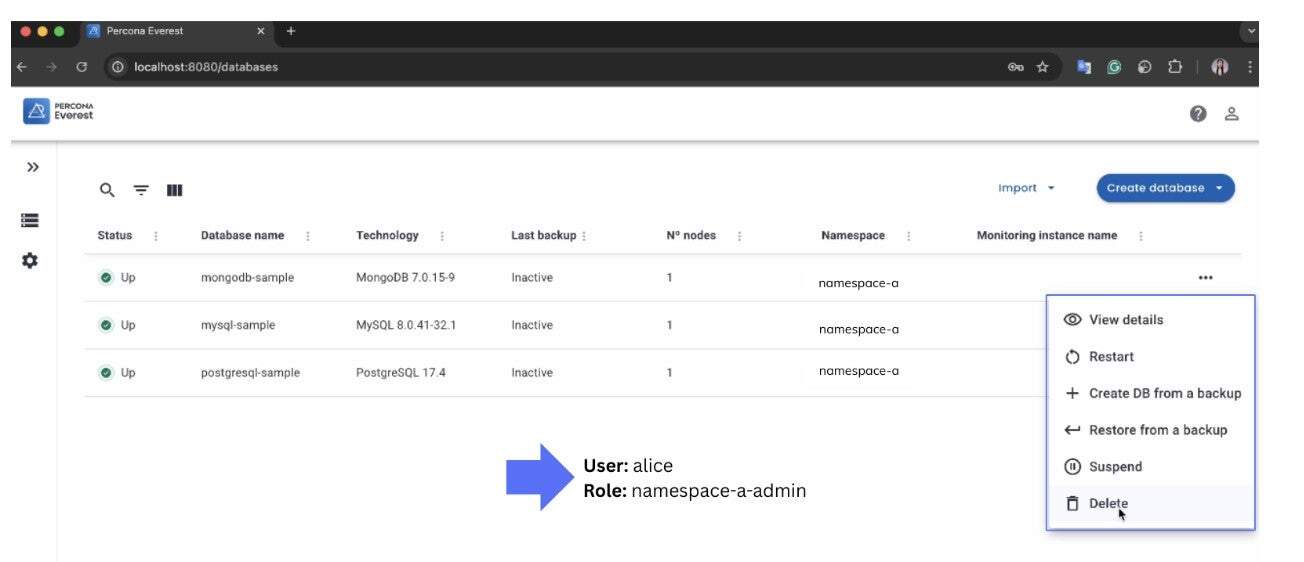
This Everest UI screenshot shows Alice with the namespace-a-admin role. She can create, restore, and delete a database in namespace-a, but she cannot touch resources in other namespaces.
Example 2: Read-only user
Not every team member needs full control. Sometimes, people just need to see what is happening without the risk of making changes. This is where a read-only role comes in.
A read-only user can:
- View clusters, backups, and monitoring settings.
- Browse through resources without risk.
- Never see edit or delete buttons in the UI.
This role is especially useful for:
- Auditors who need visibility for compliance.
- Developers who only need to check logs or cluster status.
- Team members who need insights without making changes.

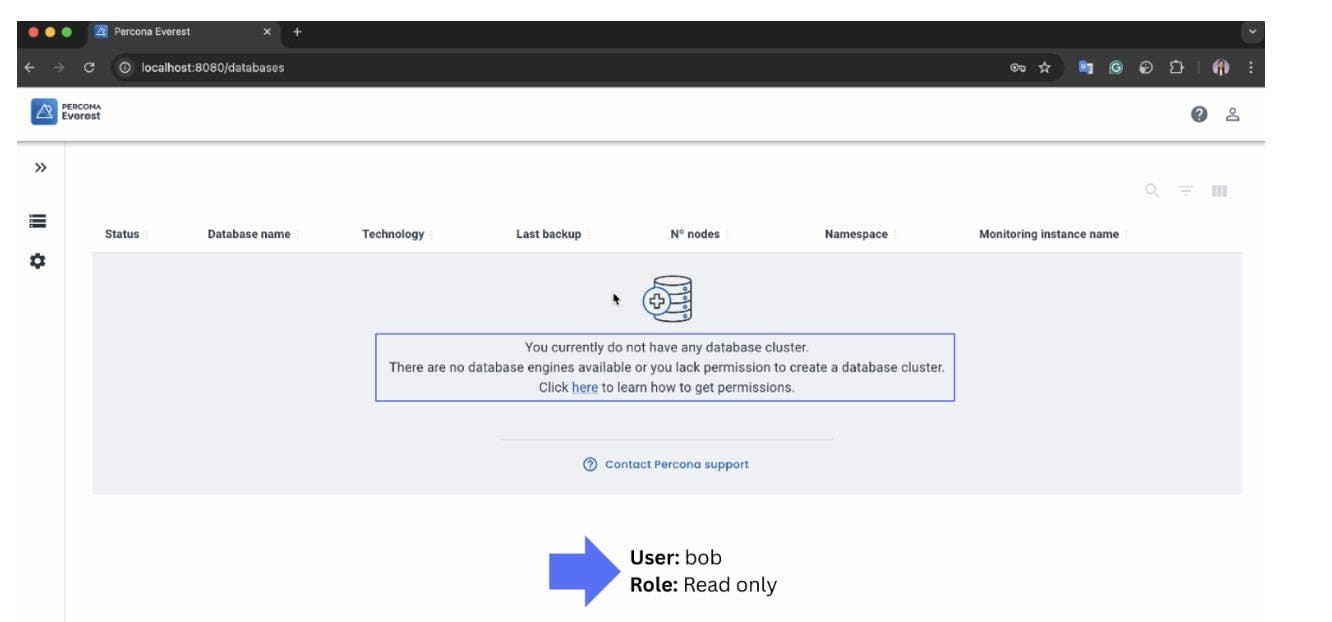
Now, let’s assign this role to a user called Bob:

When Bob logs in, he can browse all clusters, backups, and monitoring settings across all namespaces, but:
- The edit and delete buttons will not appear for him.
- He also won’t see sensitive database credentials.
This way, Bob has the visibility he needs without the risk of breaking something.
Example 3: Database admin with restrictions
Our last example is about database administrators(DBA); sometimes we will need to have strong control, but not too much. In this role, the DBA can:
- Full control of clusters and credentials.
- Only view (read-only) access to backup storage and monitoring.
This ensures DBAs can manage databases safely, without accidentally altering infrastructure. This is how the policy works:

Now let’s assign this role to a user called Carol:

When Carol logs in, she can:
- Create or delete database clusters
- Manage backups, restores
- View credentials
…but if she tries to edit backup storage or monitoring settings, those options are disabled.
Validating and testing policies
Before applying RBAC rules, it is important to check that they actually work as expected. Consider these two key steps:
- Make sure the syntax is correct → resource names and actions must exist and be valid.
- Test what the user can do → ask questions like “Can this user create a cluster? Can they delete a backup?”
In our example platform, Percona Everest, you can validate RBAC policies before applying them, with a simple command:

Valid policy example:

Invalid policy example:

When we validate policies first, we are avoiding surprises like typos, missing resources, or roles that don’t exist.
We can test permissions to confirm users have the right access. For example, if Alice only has read-only access, she should not be able to create a database cluster.
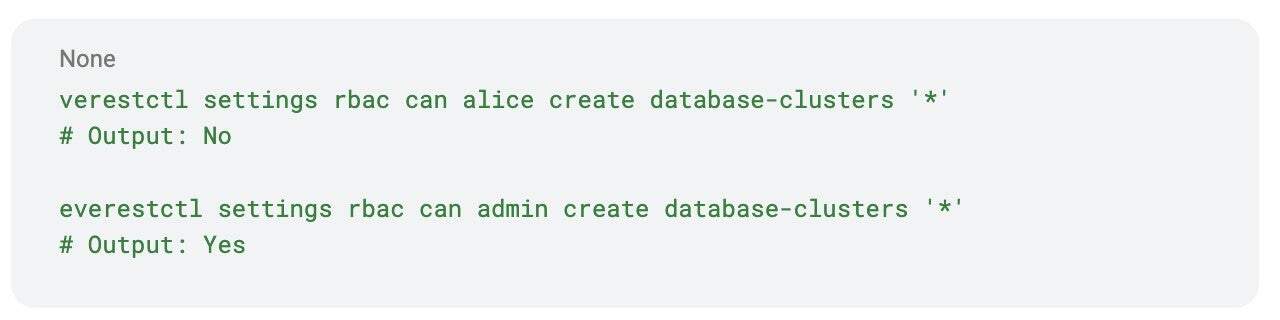
In this case:
- Alice, with read-only access, cannot create clusters.
- The admin user can create clusters as expected.
Best practices for RBAC in stateful workloads
- Give users only what they need, then expand if required.
- Some actions depend on others: e.g., granting create usually also requires read.
- Use namespace-level roles so mistakes are limited to one team’s namespace.
- Use validation tools to catch typos or missing resources. Example Pod Validation
- Test roles by simulating actions as the user to confirm that the policies work as expected.
Conclusion
RBAC is more than a common Kubernetes feature; it is also a shared responsibility model for cloud-native teams. We think carefully about roles and scopes to build platforms that are safer for production workloads, easier to operate at scale, and more resilient against mistakes or malicious activity.Kubernetes already includes RBAC; the key is applying it effectively to databases and other stateful workloads. If you want to dive deeper, explore CNCF resources on Kubernetes RBAC or share your practices in the CNCF End User Community to learn from others. Sharing them helps shape better security and access patterns across the cloud native ecosystem.