
During ContainerDays in Hamburg, Kelsey Hightower posed a simple but powerful question: “Why are we still talking about containers?” His point resonated with me deeply — even in the AI era, the cloud-native community is still refining the fundamentals of container orchestration, scalability, and efficiency. In this post, I’ll explore how open source projects like KEDA and Karpenter can help you balance performance, reliability, and cost in Kubernetes autoscaling.
Kubernetes autoscaling comes with trade-offs
When we talk about Kubernetes autoscaling, it’s not just about adding replicas or nodes when demand grows and removing them when it shrinks. You have to balance performance, reliability, and cost — three forces that constantly pull against each other.
The way I like to think about these three pillars is as a triangle, like in the following figure.
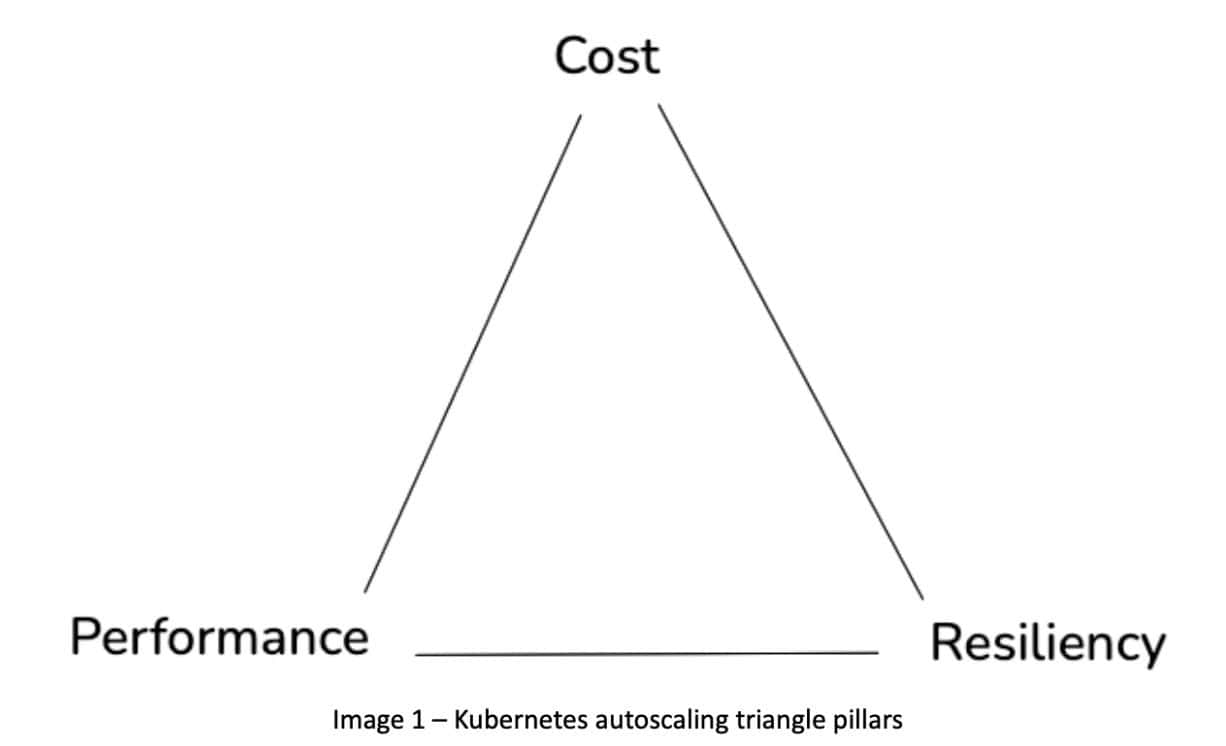
These three pillars create natural tension. Before your application’s performance degrades, you need to add resources — which increases cost. To save on cost, you scale down resources — which can impact reliability. So how do we find the right balance? Let’s explore tools and recommendations for each pillar.
Performance
Before you start scaling, you need to understand what truly impacts the performance of your application — what matters to your users and stakeholders. Most of the time, they don’t care about CPU or memory usage directly. These may be indicators, but they don’t always tell the full story.
Teams that succeed with autoscaling often track metrics such as requests per second, latency, queue depth, time-to-first-token, tokens per second, or even event-driven metrics from external sources like cloud providers. There’s no single “golden” metric for every workload. Often, a combination works best.
That’s where KEDA shines. Even if you currently scale on CPU or memory, KEDA supports those metrics — but also opens the door to custom triggers and composite scaling rules for more complex workloads.
When you know which metrics actually affect performance, you can design smarter scaling policies and thresholds. The goal is to ensure that you don’t shrink resources at the expense of user experience.
A practical way to find the right scaling configuration is to test your workloads:
- Use load-testing tools like k6 to send synthetic traffic.
- Experiment with VPA, krr, or Goldilocks to understand resource efficiency.
- Identify the breaking points for one-pod, multi-pod, or observed live scenarios.
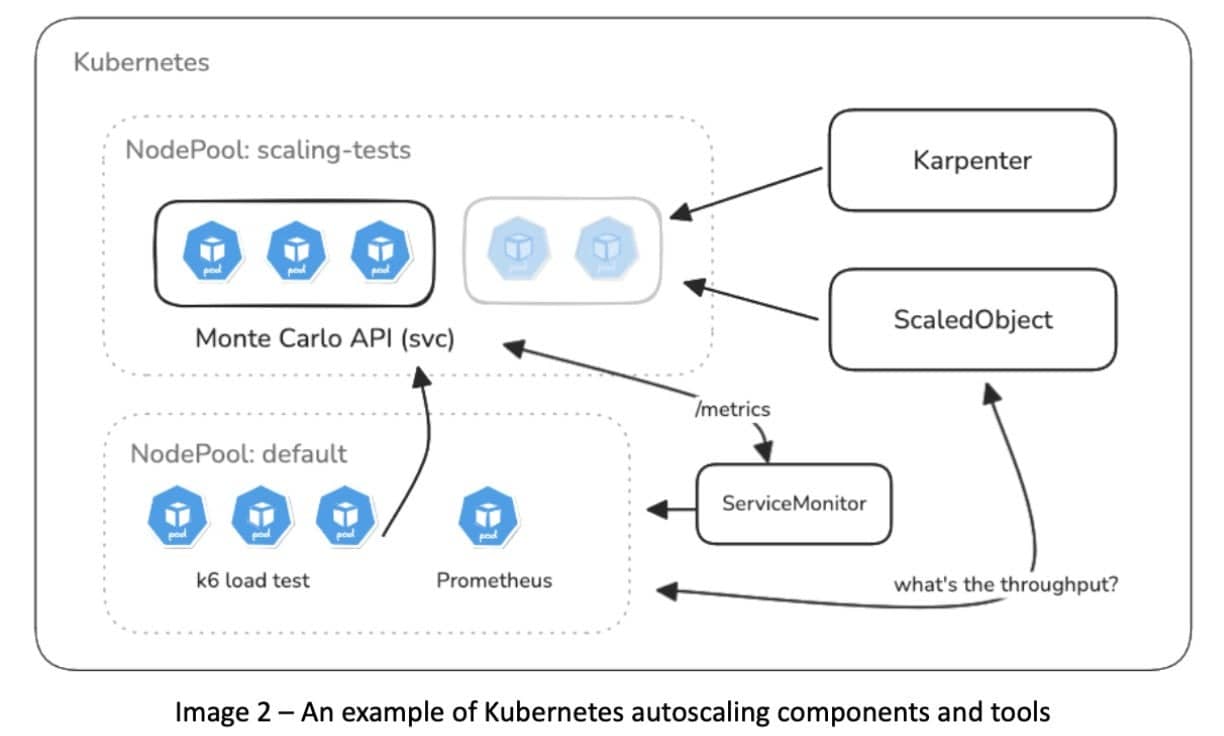
Even if this sounds like a lot, starting with this method helps you better understand your scaling patterns — and you can automate later. A good example of automation is in-place pod resize via VPA, which allows more dynamic tuning.
Cost
One of the biggest motivators for autoscaling is efficiency — using only the resources you need, when you need them.
KEDA helps right-size workloads by scaling pods intelligently, while Karpenter complements it by provisioning just-in-time nodes in a cost-optimized way.
Here’s how they work together:
- When demand grows, KEDA adds more pods to handle the increased load.
As pods become unschedulable due to lack of capacity, Karpenter provisions new nodes to meet that demand.
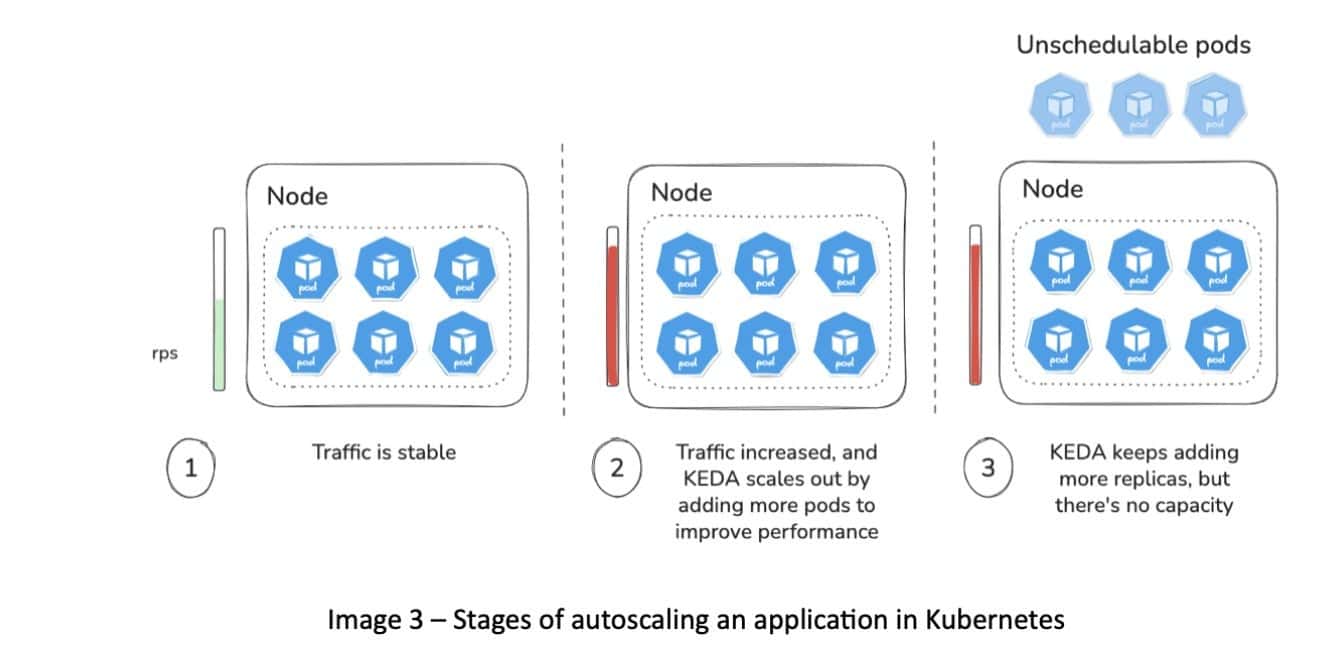
Karpenter ensures that only the necessary capacity is launched — no more, no less.
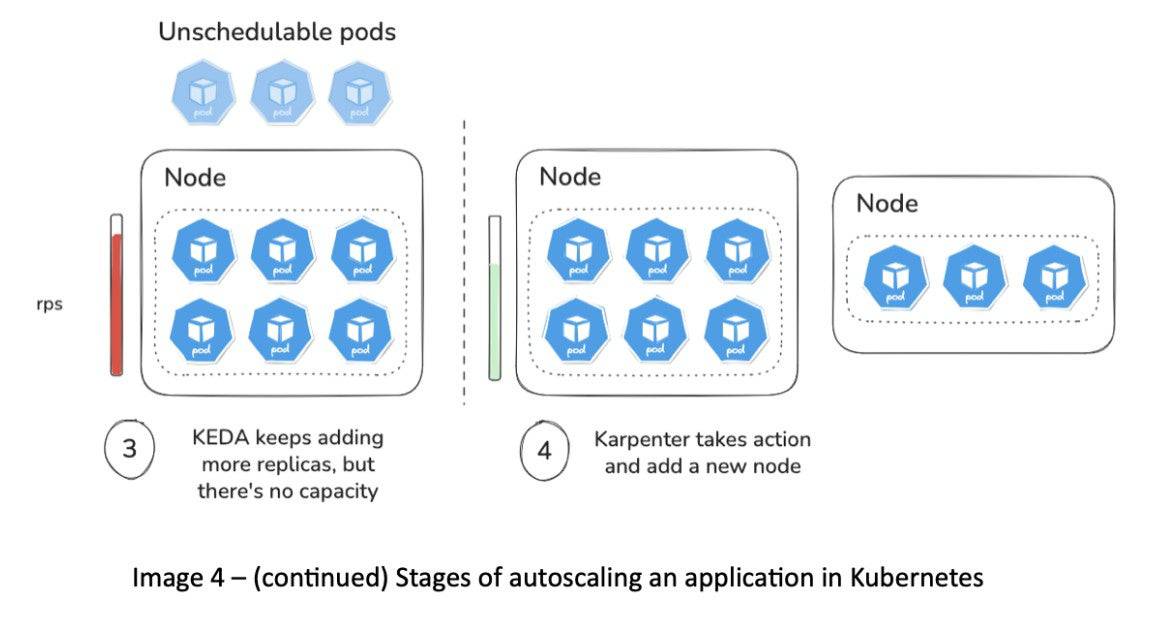
When demand decreases, KEDA scales pods down, and Karpenter can consolidate or remove underutilized nodes. It may simulate node evictions to determine whether workloads can be packed onto fewer, cheaper nodes, freeing up capacity.
If you’d like to see this in action, check out the demo I recorded showing KEDA and Karpenter working together — or the session I co-presented with Jan Wozniak (KEDA maintainer) at KCD Czech & Slovak. Both highlight how intelligent scaling can lead to significant cost reductions and improved cluster efficiency.
Reliability
The third pillar — reliability — is where things often get tricky. Autoscaling adds and removes Pods and Nodes dynamically, which can impact stability if your applications aren’t built to handle graceful terminations or sudden changes.
Before tackling reliability, clearly define your SLAs and SLOs. You don’t want to over-engineer or over-spend if your service-level expectations don’t require it. For instance, if your SLA is 500 ms latency at 3,500 requests per second, design accordingly — understand your error budget and use it to guide trade-offs.
Here are some practical ways to maintain reliability while scaling dynamically:
- Spread pods across multiple zones.
Use pod topology spread constraints with whenUnsatisfiable: ScheduleAnyway to ensure high availability without over-provisioning. Be aware this can slightly increase cost as new nodes may be launched for even distribution. - Use Pod Disruption Budgets (PDBs) and NodePool Disruption Budgets (NDBs) (if using Karpenter).
These help manage voluntary disruptions like node consolidations or upgrades. But remember — for involuntary events like spot terminations, these budgets don’t apply. Always test your application’s tolerance to unexpected terminations. - Handle terminations gracefully.
Configure terminationGracePeriodSeconds (default: 30s; consider extending to 90s), add a preStop hook for cleanup tasks, and implement a readinessProbe so traffic isn’t routed to terminating pods. If possible, handle the SIGTERM signal directly in your application code. - Monitor node health proactively.
Tools like Node Problem Detector can surface issues early, and Karpenter’s Node Auto Repair can automatically replace unhealthy nodes.
When done right, these strategies let you scale efficiently without compromising reliability.
It’s all about trade-offs
There’s no silver bullet for autoscaling. Every optimization introduces trade-offs between cost, performance, and reliability.
You might start optimizing for cost, then realize performance suffers. Or you focus on performance, and costs balloon. The key is to treat autoscaling as an ongoing process — a continuous journey of measurement, experimentation, and refinement.
Keep watching how KEDA and Karpenter evolve — both projects are rapidly improving with new features that make scaling smarter and simpler. And remember: most of the principles here also apply to AI and ML workloads, which bring new scaling challenges worth exploring in the future.
Meet with me at the AWS Booth #210
Author bio
Christian Melendez is Principal Specialist Solutions Architect and EMEA Lead for Compute at AWS, with a strong background in Kubernetes platform engineering and author of the Kubernetes Autoscaling book. Christian has been working with Kubernetes since 2017, helping large enterprises—including telecommunications, airline, and ride-hailing companies—optimize their workloads. He is the creator of the Karpenter Blueprints project and an active contributor to autoscaling solutions in the cloud-native space. Christian frequently delivers talks and workshops on Karpenter and Kubernetes optimization strategies.