

Member post originally published on the Middleware blog by Keval Bhogayata, covering Automating Stateful Apps with Kubernetes Operators.
If you’ve ever had issues with scaling databases or automating upgrades in Kubernetes, Operators can help by saving you time and effort. Handling complex Kubernetes applications like databases, message queues, and distributed systems can be really difficult. Kubernetes handles simple workloads well, while big apps suffer with failover, scaling, backups, and automated updates. These activities often demand operational expertise.
If you’re new to container orchestration, you may want to start by understanding the difference between Kubernetes vs Docker
This is where you need Kubernetes Operators, which we’ll cover in this article. You’ll learn what these Operators are, how they work, and why you need them.
Let’s get to it.
What are Kubernetes Operators?
Operators are extra tools that help you manage complex or stateful applications in Kubernetes. It is a combination of Controllers and Custom Resource Definitions (CRDs).
Controllers are the rules for deploying, setting up, scaling, healing, and updating resources. CRDs let you add a new object type to Kubernetes. CRDs also allow you to describe the type of object you want to manage, after which you proceed to create a Custom Resource (CR), which is an instance of the object type you have made.
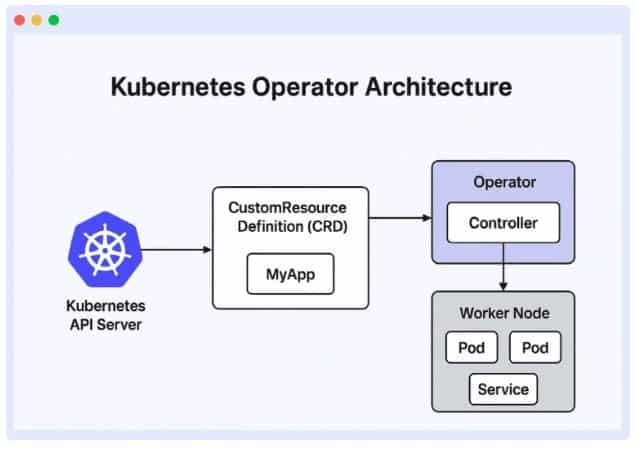
The primary purpose of operators is to simplify the management of complex Kubernetes applications, enabling tasks such as upgrades, failover management, backups, and scalability to be performed automatically.
Difference between traditional Kubernetes Controllers and Operators
Here’s a breakdown of the difference between the Kubernetes Controller and Operators:

How Kubernetes Operators work
Assuming you have your app ready, a basic Kubernetes setup, and a working deployment. Without Operators, you’ll have to install and manage the app yourself manually. But with Operators, you can run these processes automatically. Here’s how it works:
1. Set up a Custom Resource
A Custom Resource (CR) is an object you make to control a particular aspect of your application. You need to declare a CRD before you can create a CR. CRD tells Kubernetes about the new type of object you are making.
Here’s an example of a CRD that defines a CR called “MyAPP”:

This CRD defines a custom resource called “MyApp.” It has two major fields under spec: size and version.
Once the CRD is applied to the cluster, you can go ahead to create instances of “MyApp,” which represent your app configuration:

This CR declares that you want 3 replicas of example-app (an instance of MyApp) running with version 1.0.0. The Operator will then watch this resource and make sure your app matches what you declared.
2. Deploy the Operator into the Kubernetes cluster
After defining your CR, the next thing is to deploy the Operator itself. This will monitor CR changes and ensure the cluster status matches your declaration.
You usually use a set of Kubernetes configuration files (YAML files) to notify the cluster to run the Operator as a Pod. This includes setting up permissions so the Operator can watch and manage resources.
Example:

3. Continuous monitoring of CR by the Operator.
After deployment, the Operator will constantly monitor changes in the CRs it manages. This monitoring can be done using Kubernetes API. It watches for events such as creation, updates, or deletions of these CRs.
The Operator looks out for real-time changes to ensure it can react as soon as something happens. With Kubernetes client, you can set up a watch on your CR like this:

This code monitors the “MyApp” CRs in the specified namespace. The Operator will get an event with details when you add, change, or delete a CR. This lets it react fast and keep the app’s state in line with the specified setup.
4. Reconciliation loop: Operator compares desired vs actual state
The reconciliation loop is the main idea behind Operators. It makes sure that the actual state of your app matches the desired state you defined in the Custom Resource by re-running the whole process if it fails.
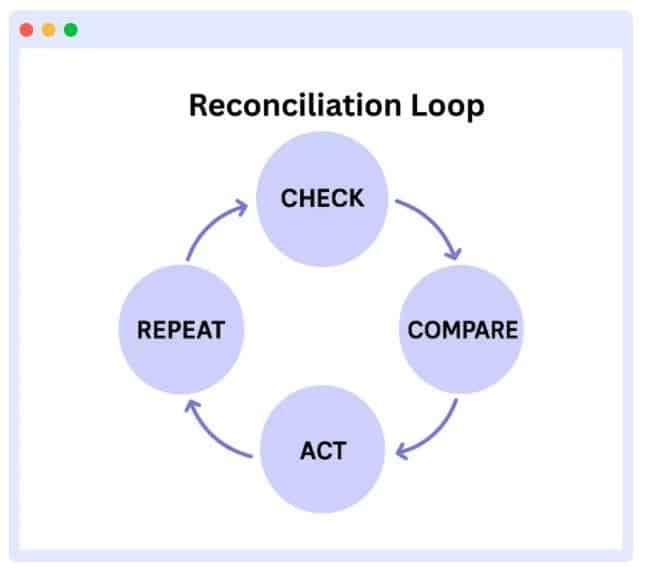
Here’s how it works:
- The Operator reads the desired state of your CR.
- Then it checks the actual state of the cluster.
- If they don’t match, it acts to fix it.
- It repeats this process continuously.
This reconciliation logic can be triggered by the watch events we set up earlier.
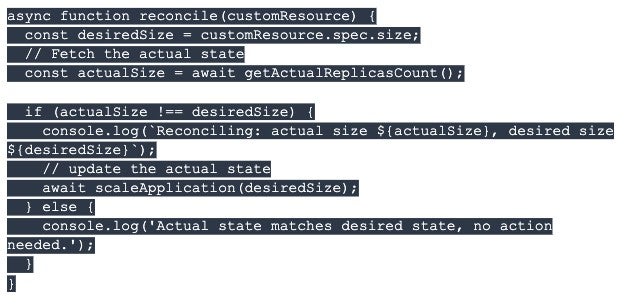
The reconciliation function guarantees your application works as expected.
5. Error handling
One way or the other, you’ll still encounter problems when working with Operators. When issues come up, the Operator won’t just stop. They keep trying until they get the correct result.
For example, learn about diagnosing and fixing Exit Code 137 in Kubernetes, a common error when pods are OOMKilled.
Here’s the idea:
- The operator tries to make the actual state equal to the desired state
- It logs an error if it fails
- The reconciliation loop runs again after a while
- The Operator tries again until it works.
Use cases of Kubernetes Operators
Operators are mostly helpful when working with complex or stateful apps. Here are some practical scenarios where Operators provide great value and how Middleware helps teams get more visibility out of them:
Handling stateful apps
Stateful workloads, such as databases, can be challenging to manage because data recovery is crucial. Operators help to manage these workloads even when a container or pod stops. It automatically does backups, restores, scaling, and upgrades. A good example is the Postgres and MySQL Operators.
Postgres Operator allows you to automate backups, failover, and scaling of PostgreSQL clusters. The Operator will automatically configure replicas or restore from snapshots, instead of SREs doing it manually.
Messaging systems
Messaging platforms like Kafka require careful tuning and scaling, particularly under high traffic loads. The Strimzi Kafka Operator simplifies this by provisioning brokers, handling configuration, and managing users. This removes the stress of manually scaling and restarting on the DevOps teams.
Monitoring and logging stacks
Tools for monitoring and logging, such as Prometheus or ELK, must always be available and scalable to collect data effectively. Prometheus Operators automate upgrades, scaling, and configuration management. This makes sure that the monitoring pipeline is stable without human intervention.
Automating infrastructure
Operators are not limited to apps; they can also automate repetitive infrastructure tasks, such as provisioning storage, configuring network policies, or managing certificates. This helps ensure consistency and security while reducing the risk of errors associated with manual processes.
Again, Middleware displays these invisible tasks, which allows SREs to audit changes, track automation workflows, and set up alerts when infrastructure doesn’t match the expected state.
Why do we need Operators?
Kubernetes controllers are mostly applicable when it comes to managing simple apps. But when dealing with complex or stateful apps, they have limitations. These native controllers cannot automate application-specific operations and workflows, making it difficult to manage tasks like database provisioning, upgrades, and failover reliably.
Without Operators, manual database recovery can lead to hours of downtime. Kubernetes Operators automate these tasks, and Middleware real-time alerts ensure you catch issues early.
Challenges without Operators
Without Operators, you will face these challenges:
- Manual database setup and recovery: You have to create and fix databases yourself, which takes time and can cause mistakes.
- Hard upgrades: Updating apps will require many steps and careful timing to avoid breaking things.
- No app-specific knowledge: Built-in controllers are unaware of your app’s unique rules, so they can’t fully automate it.
Explore common Kubernetes challenges and solutions that teams face without automation.
Kubernetes Operators benefits
These are some of the benefits of using Operators:
- Automating app lifecycle: Operators automate critical operations, such as installation, backup, upgrade, and failover, tailored to the application’s specific needs.
- Enforcing consistency at scale: Operators ensure that the desired state is consistently maintained across multiple instances or clusters, simplifying large-scale management.
- Reducing human error: Operators minimize manual interventions and reduce human error by applying expert operational knowledge.
- Automate app lifecycle: Operators can reduce failover downtime by recovering stateful apps automatically. This will improve availability and reliability.
Operators automate management, but visibility is key. Discover the top Kubernetes monitoring tools that help you track app performance, spot issues early, and maintain cluster stability effortlessly.
Conclusion
Operators are a powerful addition to Kubernetes because they make it easier to handle stateful and complex tasks, which seem to be difficult for built-in controllers. While Operators make work easier inside Kubernetes, teams still need a way to monitor and make sure their app is working as expected.
Observability through metrics, logs, and traces becomes the bridge between automation and assurance. By integrating robust monitoring and alerting with your Operators, teams can quickly detect anomalies, validate desired states, and ensure that self-healing mechanisms are actually working as intended. In the end, Operators simplify the how of running applications, but observability provides confidence in the why and when, turning Kubernetes into a truly resilient platform.