

Community post by Rob Williamson
Microservice autoscaling and event-driven decoupling are both paths to help you deliver on the same purpose – maximum performance AND efficiency for applications. Unfortunately, these two goals can also be at loggerheads and require an understanding of the architectureal differences to deliver on them. However, when done right, you can get the dynamic performance without breaking asynchronous messaging queues. This blog will delve into Kubernetes Event Driven Autoscaling and how it is triggered by and served data from event brokers using Solace as an example.
The problem – how to automatically scale when you aren’t aware
With Event Driven Architecture (EDA) a critical principle is the decoupling of producers and consumers. Taken from a purely from old-school messaging concept, the event broker acts as the intermediary that queues up events for the consumer(s) to use. The modern event broker takes things much further by supporting many different messaging patterns (pub/sub, streaming, fan-out, etc.) many different message capabilities (guaranteed, dead-message, intelligent routing, etc.) and different levels of observability (broker metrics, event telemetry, etc.). All this serves to complicate autoscaling.
Autoscale that! Enterprise-wide deployment of event driven architectures liberate data asynchronously and when used effectively consumer autoscaling works well with the routing of real time data and events
Lets look at two pictures that illustrate the challenge and benefits of scaling when you are decoupled. In the first you have a simple exclusive queue that binds one consumer to one producer and doesn’t have stateful events. What we mean by this is that one event may be related to or depend on another and the sequence of delivery and consumption mattter. It introduces the need for things like queues and cache. It is easy to trigger scaling of an active consumer.
However, if your events are stateful (simply put that processing needs to be kept track of and in order) then you can’t use this queue type to autoscale and your only options are a larger spool on the broker or a faster processer on the consumer. If the consumer simply cannot keep up (horizontally or vertically) then messages are lost – but with a well implemented broker the memory will handle a very large spool.

This second picture shows how the queue can trigger scaling of consumers but then the stateful datasets need to be bound to the right consumers.
With autoscaling the benefit is that microservice instances can be added in response to demand so you don’t need to over-provision or under-serve. This means that the application has to expose metrics so that the clusters know when to scale based on load. However, it is not aware of the systemwide load unless both ends of the applications are sending metrics. The problem here is that using an application-based scaling trigger can effectively couple the applications and the architect loses significant benefits of EDA and decoupling.
This is where Kubernetes (K8) Event Driven Autoscaling (KEDA) comes into play. KEDA is an open source project under the Cloud Native Computing Fountation that lets you drive the scaling of any K8 container based on the number of events that need to be processed. They maintain a directory of autoscalers – which in the case of KEDA is the event broker that has a queue depth as an external trigger source. It is important to note that the “event” in KEDA is not, strictly speaking what “event” means in event-driven architecture. In the latter it is often thought of as a “message” in pub/sub.
Okay – so the problem is solved right? Unfortunately, not yet. For many applications (1) the order of events is critical and (2) the processing of related events is critical. For example, you shouldn’t trigger an abandoned shopping cart process after items have been removed from it because it is probably not the best use of expensive advertising dollars. You can’t also run the consumer application that uses credit card data from one queue and (someone else’s) home address from another queue.
There are similar examples for things like inventory management, machine operations, transaction processing and more. What they share in common is that they are operational processes that require message order, guarantee, and resilience while being built in a pub/sub pattern that dynamic routes events across different applications (and locations). Notably, different development teams are building different applications from the same events to benefit from true enterprise-wide architecture built around EDA. So your scale changes based on the use of the event being published to the event mesh.
So you have choices here that includes maintaining a non-beneficial log or a data store with meta data for state – choices that cost money in egress and storage and increases cost, complexity and latency of the applications. The other alternative is scaling the consumer and the queues in lock step – which we have already identified as not being decoupled; and requires maintenance and awareness at both ends of the pub/sub chain.
So within the event broker you need to be able to trigger scaling of consumers in response to load (typically queue size) and you need to ensure that the consumers are getting like-events in the same order.
Okay – so if you have read this far then you have hopefully understood that consumer autoscaling and EDA require the use of the right tools and the right configuration. Lets look at how we set one up.
Example – Configuring and Event Broker to Trigger KEDA
For this example we are using a Solace PubSub+ Event Broker. In the below diagram it is being configured as the external trigger source for our K8 cluster.
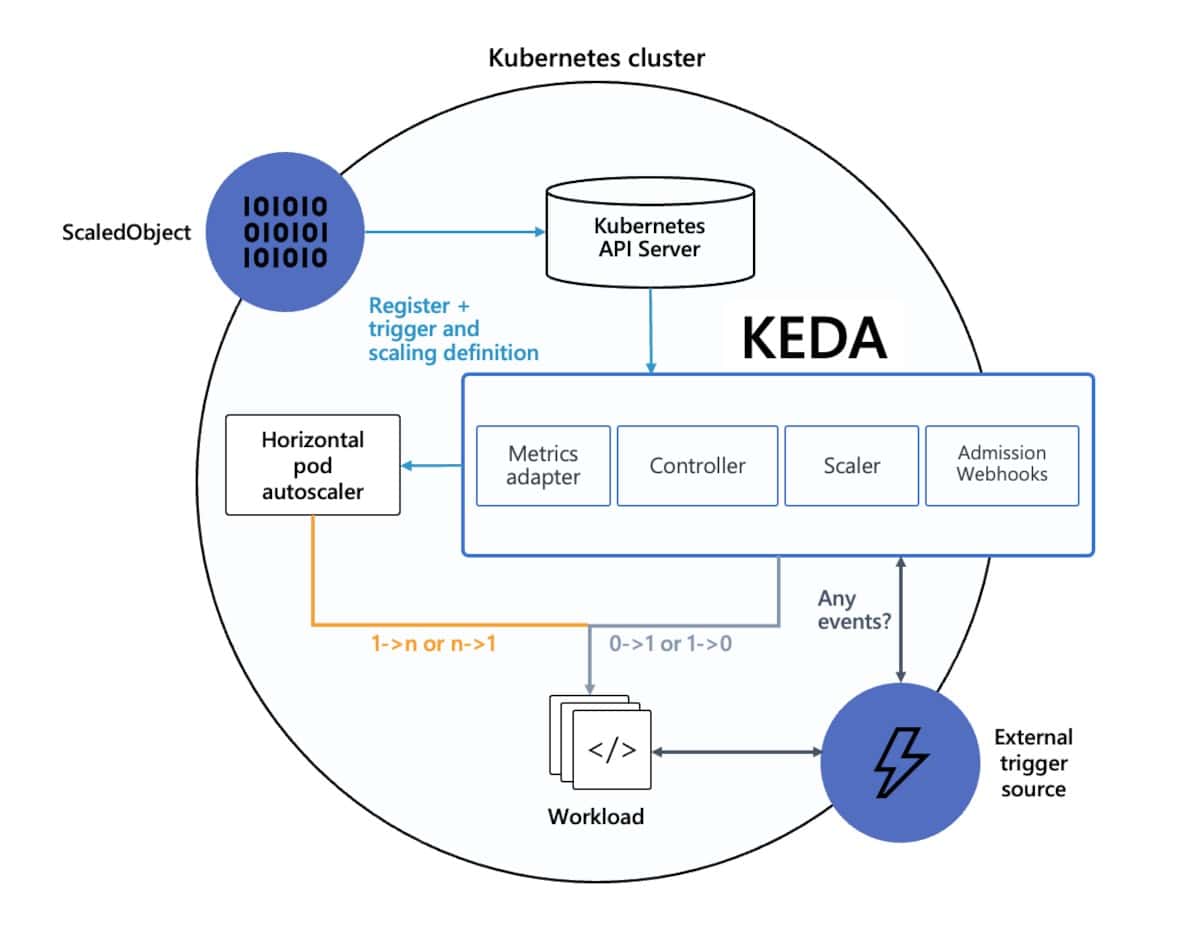
Source: KEDA Documentation (https://learn.microsoft.com/en-us/azure/aks/keda-about
We’re going to assume that you have already gone through the set-up of KEDA and you are connecting the scaler to your cluster. For this the queue is being used to trigger the new microservices but at least one of the message count, message spool usage, or message received rate must be used. And if all three are used then the scaling will trigger based on at least one of the parameters being met. All of these can grow in response to slow consumers, or not enough consumers when compared to the publishing applications.
Triggers
Message count – Simply the number of total messages in the queue where you set the interval based on how bursty the queue is and how quickly it needs to run down.
Spool usage – The total amount of the memory used in the queue buffer. This can be an elastic number for your organizations so you would choose it based on your typical use scenario.
Receive Rate – You would target somewhere less than the maximum capacity/number of messages a consumer can handle as the trigger. The broker in this instance keeps an average rate, calculated every minute.
For best results we would be setting both the message count and the receive rate as targets – they are clearly related, but the goal is to match the inflows and outflows for an optimized system. The problem with only choosing one of the metrics is the constant spinning up and down of consumers as the system tries to achieve a steady state where, in real world scenarios, none may exist.
triggers:
- type: solace-event-queue
metadata:
solaceSempBaseURL: http://solace_broker:8080
messageVpn: message-vpn
queueName: queue_name
messageCountTarget: '100'
messageSpoolUsageTarget: '100' ### Megabytes (MB)
messageReceiveRateTarget: '50' ### Messages/second over last 1 minute interval
activationMessageCountTarget: '10'
activationMessageSpoolUsageTarget: '5' ### Megabytes (MB)
activationMessageReceiveRateTarget: '1' ### Messages/second over last 1 minute interval
username: semp-user
password: semp-pwd
usernameFromEnv: ENV_VAR_USER
passwordFromEnv: ENV_VAR_PWD
https://keda.sh/docs/2.13/scalers/solace-pub-sub
Polling Interval and consumer count
Configuring this is straightforward and in the example below we have chosen a poling interval of 20 seconds and a maximum number of consumers to 10.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: solace-scaled-object
namespace: solace
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: solace-consumer
pollingInterval: 20
cooldownPeriod: 60
minReplicaCount: 0
maxReplicaCount: 10Event Order
Now that you have configured an event broker queue to trigger autoscalilng how do you ensure order? This is where the queue type comes into play. In an event broker you have two basic types. An exclusive queue and a non-exclusive queue. Their definitions are (hopefully) self-explanatory and they have traditionally been used for when state matters and you use a single consumer or when scale matters but state does not and you use many consumers.
In order to maintain state across changing consumers you use a type of non-exclusive queue called, “Partitioned Queue”. Each partition is effectively, an exclusive queue that can have no more than one bound consumer, allowing order to be maintained. With this enabled the application developer would define a key value and that key is hashed in order to generate a key that maintains the partitions. Logically the key value chosen would reflect the need to scale the number of partitions. For example, if you imagine an account # stored in the event to be something that scales logically for your application then you may set your hash off that account number.
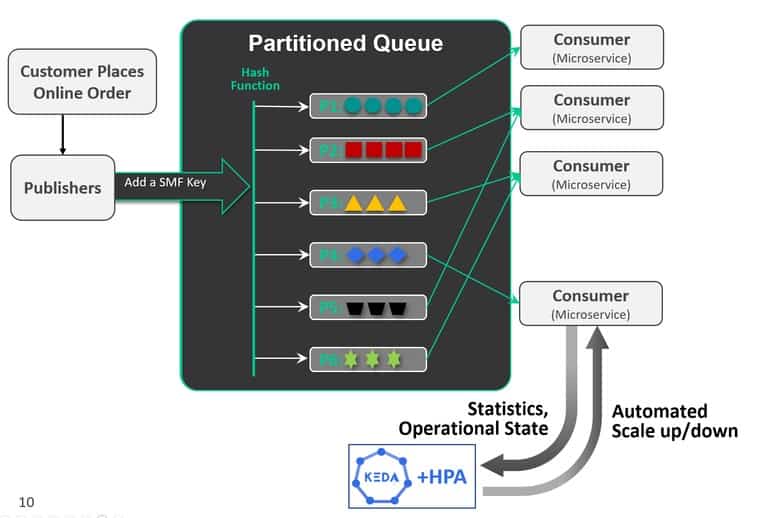
So – what is then happening in the back end? Well, for each new consumer the event broker is rebalancing the queues across different partitions – one for each consumer. This maintains state so that like-events are consumed in the correct order and by the same consumer. As they are brought on and off there is a rebalance delay to allow queues to be fully consumed. This combination of settings are configured in the event broker so it is responsive to what you are configuring in KEDA.
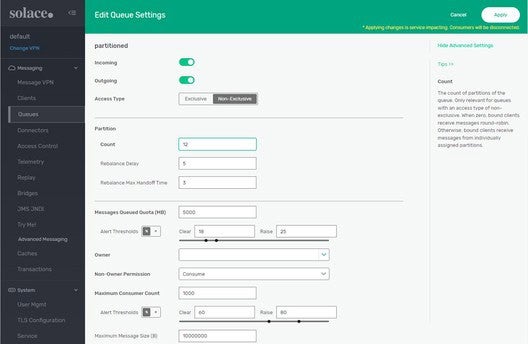
The Event Broker and KEDA Dance Together
Like the tango, it takes two to design and deploy autoscaled environments, but it isn’t all that difficult once you get the hang of it. In this preceeding example, we have configured the autoscaler to respond to our applications typical event queue profile and we have configured the event broker to create queue in response to how KEDA will behave. The result is all the benefits of both, including:
Capacity allocation where you need it and when you need it = higher performance at lower cost.
Application-targeted partitioning
Maintenance of event context
Maintenance of event order
Intelligent rebalancing
Out of the box integration (no custom code to maintain)
Solace event brokers are one implementation of KEDA autoscaling on brokers and an event mesh. To learn more about event driven architecture and to see some of the other activities that Solace engages in to support the open source communities like OpenTelemetry, Kubernetes, and more, please consult our latest resources in this area.
About Rob
Rob has over 20 years of experience with product management and marketing in the technology industry. His public activities include writing, presenting and blogging on subjects as varied as enterprise architecture, software development tools, cyber-security and DNS. An avid product marketer who takes the time to speak to IT professionals with the information and details they need for their jobs.