

Community post by Gabriel L. Manor, Director of DevRel at Permit.io
Domain-specific declarative languages have been a huge part of software development since its early days. Created to tackle the complexities and specialized requirements that general-purpose programming languages struggled to manage efficiently, they are now an integral part of every developer’s toolkit.
In the field of IAM, authorization is becoming increasingly challenging in recent years – apps are getting more complex, as are user requirements. The result? a huge surge in domain-specific declarative languages focused on authorization. From older languages such as Open Policy Agent’s Rego getting a facelift with their upcoming V1 to new languages like OpenFGA and, more recently, AWS’ Cedar being created, significant steps forward are being made in the authorization field to tackle this ever-growing complexity.
In this blog, we’ll talk about why these domain-specific declarative languages are so important and how you can use them to your advantage to build better, more secure applications. We’ll start by talking about where domain-specific declarative languages came from and which problems they were created to solve –
From Assembly to Domain-Specific Declarative Languages
Chaos
Since the early days of solving problems with software, developers have tried to increase productivity and automation. In the early days, we used machine language—manually writing binary or assembly code. But that was inefficient, so we created languages like C for personal computers and servers to bring order to the chaos.
Complexity
As programs grew more large and complex, writing them with C had many limitations and was counterproductive. This led to the development of object-oriented programming design patterns and languages like C++ to manage complexity more effectively. However, the abstraction introduced by higher-level languages such as Java and Python, while making development easier, often resulted in issues with performance. To address these issues, particularly with concurrent processing, the Go language was developed, offering more efficient performance.
Velocity
At this point, a new issue emerged – velocity. If we want to deliver software to a browser, for example, we need to deliver it extremely fast so a user can access it the minute we deliver it. This requires taking languages and turning them into frameworks. If you think about a language like JavaScript – there are no JavaScript developers; there are Node.js developers; there are React developers – we use these languages because they are framework-oriented, increasing software velocity.
Confidence
Velocity is great, but it comes with a big issue – it tends to break things. At this point, the thing we lack most is a sense of confidence in our software. Take user interfaces – we want them to look and perform in a way we can fully anticipate and rely upon. That’s where domain-specific declarative languages come in. HTML, for example, while not a programming language per se, creates domain-specific confidence that ensures we deliver a UI that (hopefully) looks exactly like what the user experiences.
When we look at the beginning and end of this journey, the difference is immediately evident. Domain-specific declarative languages are used everywhere to give us high confidence, enable us to do things with high velocity, handle complex use cases, and bring order into chaos. But how does this affect authorization?

Fine-grained decisions
Lately, there’s a new problem in the software development world: the problem of decisions. Decisions are one of the most basic aspects of software development, with simple ‘if’ statements at the very foundation of any programming language out there. But in the vast majority of cases, that’s not enough.

Many modern applications require extremely fine-grained decisions, especially regarding security matters in authorization (handling what a user or service can or cannot do in your application). The challenges posed by fine-grained authorization make us go through the exact same journey as the one we did with programming languages, tackling the same issues—chaos, Complexity, Velocity, and Confidence.
How Authorization changed, and What Can We Do About It?
Chaos – Application Architecture
Working as a developer back in 2010, you could easily imagine having one server, one programming language, one database, and one application. Today, even the most basic apps start tons of services from the get-go, yet we still don’t want users to access data that they’re not supposed to. This means all of these services need to have one concrete source of truth for their decision-making, and these decisions have to be streamlined across the entire stack.

The Solution – Structure
The solution to this problem comes in the form of structure. Just like C solved the problem of using machine code. First, we need to understand where these complex decisions should be made –
- The most basic layer is the code itself. Developers today have a lot of effect on how code is delivered and what production looks like. So the first decision that needs to be made is “Who Can Deliver What”? Or, more basically put, “What can the developer do?”
- Then there are the services. Here there are the questions of “Which service can talk to other services?”, “How are they deployed in the CI/CD and speak with each other”?
- Above that is the application database. Here, we need to make the decision of “Who can read what from the database?”
- On top of that, there’s the application backend, where we need to decide “What actions can application users perform?”
- On top of everything else, we have the frontend, where we need to ask ourselves “What can our application users see?”

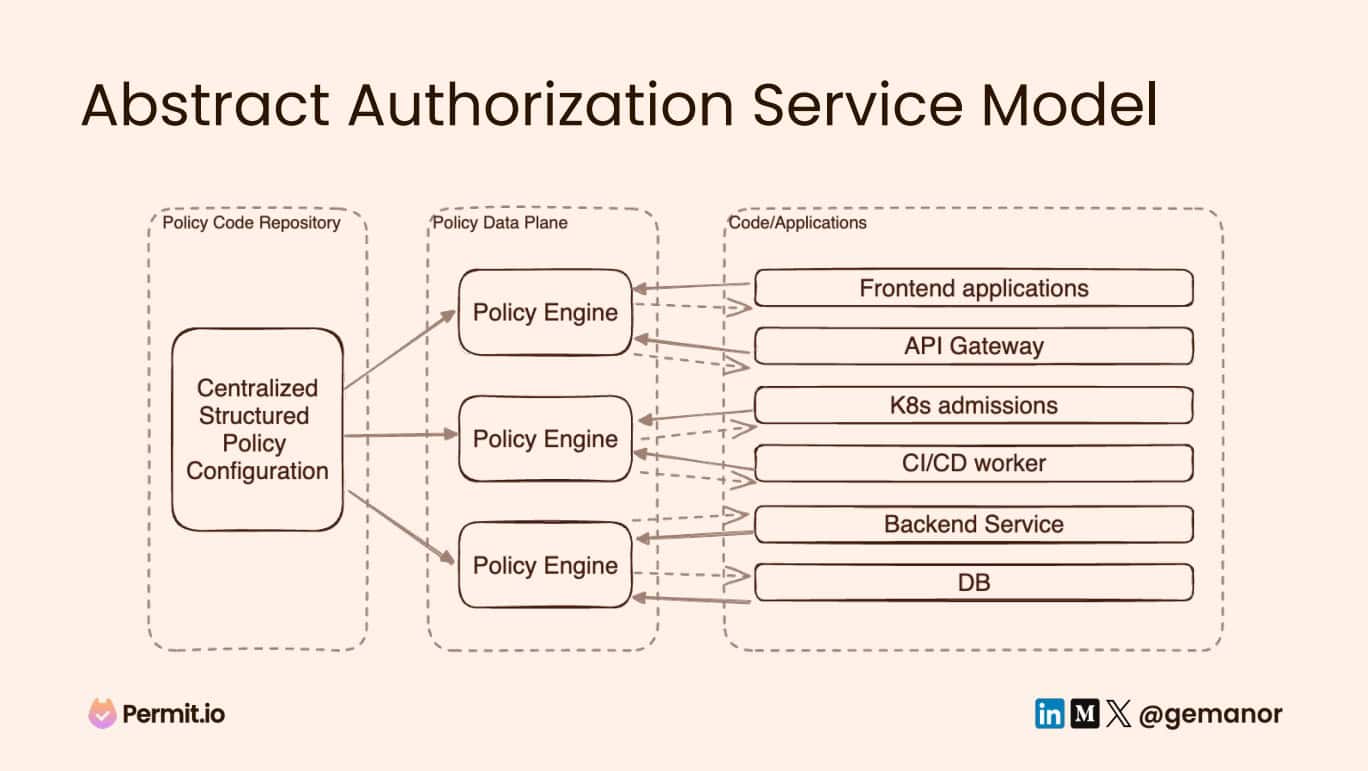
With a clear structure of where authorization decisions should be made, it’s easier for us to design a solution that can actually handle them. Here is an abstract architecture of how this should be done:
- Centralized Policy Configuration: consolidating all our configuration in one place will help us streamline it and ensure that we’re following all the standards we’re trying to establish.
- Policy Engines: having a piece of software that knows how to take the policies we configured and knows how to make the right decisions is a must. This plane needs to be decentralized for several reasons: First, it has to react super fast, and second, we want every part of our stack to be able to communicate with this plane directly and enforce permissions based on these decisions.
Complexity – Data Points and Decision Fatigue
In LAMP or older architectures, we used to have one SQL database. Today, even the simplest app uses multiple data sources, which are only growing more complex by the minute. All of this data still needs to adhere to the same level of security when in comes to making decisions. That means the way of making these decisions is also growing increasingly complex.

The more data we have, the more decisions we need to make, and the more data needs to be included in that decision-making process. At some point, it gets too complex, and we can’t keep supporting more and more granularity.

The Solution – Design Patterns
This issue can be addressed by utilizing proper design patterns.
The first thing we need to do is define the components we will require to make a decision. Here’s a very simple design pattern proposal that allows us to do just that:

- Policies are the code that configures the decisions
- Data, such as the application’s database, our identity provider, and the configuration of the Kubernetes cluster, contains whatever information we need to support proper decision-making.
- Context, such as dynamic data, date and time, and geo-location, ****allows us to better understand the situation in which decisions are being made.
Having this type of structure allows us to think more clearly about what we should focus on in every step of our decision-making process. Is it policy creation? Is it the data required to make the decision? Is there a unique context in which this decision needs to be made?
We can also think about the types of decisions we want to make –
- A decision could be binary – is something allowed or denied?
- A more complex decision involves filtering data and making a decision based on relevant data.
With all this information, we should be able to quite easily create a ‘check function’ that will allow us to make decisions while considering every relevant element. This function will define a user (or principal – like a service), an action (what they want to do in the app), the resource they want to perform it on, and the context in which this action should be allowed (As some decisions require more granular context than just who is performing what action on what resource):
check({user}, {action}, {resource}, {context});
If we create a server with these four arguments, we can streamline the design pattern in a way that allows for decision-making across the stack. If we want to do filtering, we can use what is called “Partial Evaluation” – Because software is built on source trees and abstract binary and non-binary trees, you can always convert a decision into a query language. This allows us to create an engine that knows not only how to get a decision based on a set of data but also converts it into a query language, which helps us only get the data we need.
check({ user }, { action }, { resource }, { context });
response = requests.post('<http://host.docker.internal:8180/v1/is_authorized>', json={
"principal": f"User::\\"{user}\\"",
"action": f"Action::\\"{method.lower()}\\"",
"resource": f"ResourceType::\\"{original_url.split('/')[1]}\\"",
"context": request.json
})
const response = await fetch(
"<http://host.docker.internal:8180/v1/is_authorized>",
{
method: "POST",
body: JSON.stringify({
principal: `User::\\"${user}\\"`,
action: `Action::\\"${method.toLowerCase()}\\"`,
resource: `ResourceType::\\"${originalUrl.split("/")[1]}\\"`,
context: body,
}),
}
);
Velocity – There’s Just MORE
We’re delivering more software. That means more endpoints and more production environments that just keep growing by the minute. This creates the need for a layer we can trust to always make the right decision when it comes to access.

The Solution – Frameworks
The easiest way to think of Frameworks in the context of authorization is by looking at policy models. There are a bunch of those out there, but let’s focus on the main four, see what they do, and briefly discuss their differences –
- Policy Based Access Control (PBAC) – Allows us to quickly define policy rules. If we have a designated language in which we can write authorization rules, it allows us to create authorization policies. The problem with PBAC is that it can’t consider much data. If our decisions require lots of data about what users can or cannot do or utilize data from something like our billing system, PBAC isn’t going to cut it.
- Role Based Access Contol (RBAC) – The most traditional choice, often even used by people as an alternative name for authorization, RBAC segments users based on pre-defined roles and defines what actions these roles are allowed to perform of certain resources. It’s very simple but lacks granularity.
- Relationship Based Access Control (ReBAC) – ReBAC leverages the relationships inside your application to derive roles based on them. So if, for example, I assign an
ownerrole to a folder, and in the DB, this folder is associated with the files and folders within it, I’ll be able to derive permissions to these files and folders based on myownerrole on the parent folder. If my software is distributed and decentralized, ReBAC allows me to reimagine my authorization as a graph, allowing for far more fine-grained policies. - Attribute-Based Access Control (ABAC) – ABAC is the most granular of all models and allows us to create authorization policies based on attributes. Attributes (Whether they are Subject Attributes, Resource Attributes, Action Attributes, or Environmental Attributes) allow us to create infinitely intricate and complex rules to manage our access policies.
For a more in-depth comparison of these, check out our blog on RBAC vs. ABAC vs. ReBAC
Most often, authorization models are more thinking tools than concrete guidelines, and most applications end up mixing between them. To illustrate that, we built a rather simple demo app that users all there.
Confidence – Not Just End-Users Anymore
Users of modern-day applications tend to basically want impossible features. On one hand, they want to own their data and manage its privacy, and you need to support that. That means supporting very fine-grained ownership, temporary data access functions, location-based access policies; you name it. On the other hand, app users are not really users in the classic sense anymore. Think DevOps, RevOps, and AppSec – they all want access to the code, and they affect the way that software should be delivered. Above all else, they affect how access decisions should be made.
And all of that complexity doesn’t include the newest player on the block – AI Agents and LLMs. These create a problem of unstructured decisions, as they want unstructured access to our data – how do we provide them with the right access

The Solution – Domain-Specific Declarative Code
The benefits of using Domain-Specific Declarative languages can help us overcome these challenges thanks to the benefits of having policy as code –
- They are readable. When you look at policy as code written in languages intended for authorization policies, you should immediately understand what is happening – who can do what, on what, and when.
- They improve performance. As all decisions are made in a single domain, nothing is in their way of being made and delivered with no latency.
Not only that – defining policies using code provides you with the ability to ensure policies are consistently enforced across different systems and environments, which can help prevent policy violations and reduce the risk of unauthorized access. It allows you to easily manage and update policies, as you do that with the same tools and processes used to manage and deploy software. This makes it easier to track changes to policies over time, roll back changes if necessary, and in general, enjoy the well-thought-through best practices of the code world (e.g., GitOps).
There are many policy languages out there, each more fit to handle different scenarios:

Open Policy Agent (OPA) – Rego
allow {
input.user.role == "viewer"
validate_department(input.user, input.document)
validate_classification(input.user.role, input.document.classification)
validate_dynamic_rules(input.user, input.document)
}
validate_department(user, document) {
user.department == document.department
}
validate_classification(user_role, doc_classification) {
role_permissions[user_role][_] == doc_classification
}
validate_dynamic_rules(user, document) {
dynamic_rules[_](user, document)
}
OPA started out as a multi-purpose policy engine, and that’s where its power comes from. It’s an extremely flexible language that can help you model any type of decision you want. The thing is, Rego can get quite complicated – it’s not the perfect example of a declarative language being simple and intuitive, but it does provide you with the ability to handle extremely complex decisions on any layer.
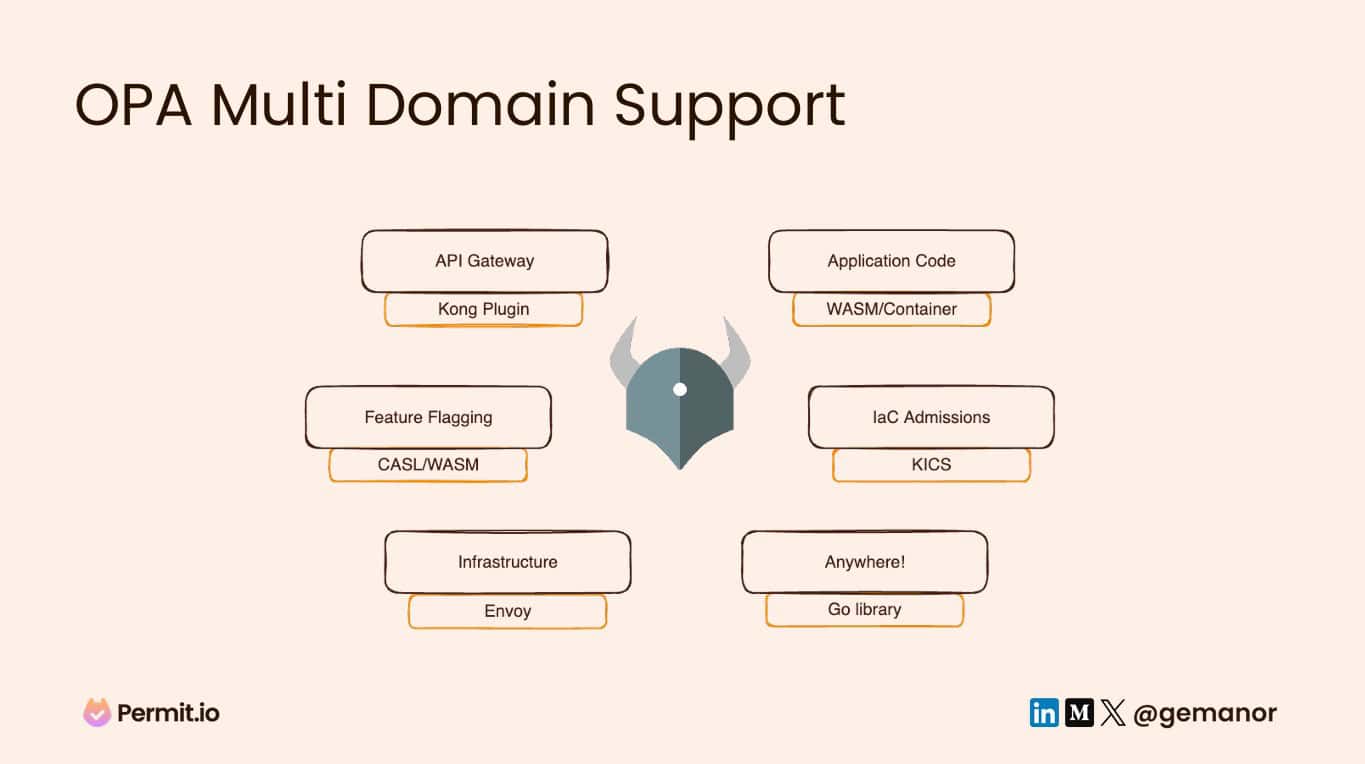
If you have the ability to learn this new language, and you want to have one agent with one policy language across the stack, Open Policy Agent is a great choice.
Read more about it here: RBAC with Open Policy Agent (OPA)
AWS’ Cedar
permit (
principal == PhotoApp::User::"stacey",
action == PhotoApp::Action::"viewPhoto",
resource
)
when { resource in PhotoApp::Account::"stacey" };
Launched by AWS just one year ago, Cedar’s started as a language dedicated language for application-level authorization. Unlike AWS IAM, it’s a language that can be used in any application. Cedar uses the Dafny language to provide scientific proof of correctness and performance, yet it is still challenging to use it when dealing with unstructured data, and it lacks ReBAC support. It’s a great option to use for fast ABAC based decisions, with auditing, static analysis, and partial evaluation supported out of the box.
Read more about it here: RBAC With AWS’ Cedar
OpenFGA
Not a policy language per-se, but more of an authorization platform based on Google’s Zanzibar white paper, OpenFGA is a great choice when it comes to handling ReBAC. Backed and maintained by Auth0 and used by them for authorization, with a graph-based engine built-in, it is the perfect solution for large-scale authorization implementations. OpenFGA is less suitable when it comes to RBAC and ABAC.
You can learn more about how it compares with Cedar here: OpenFGA
A broader overview and comparison of all three languages can be found here: How Open Policy Agent compares to AWS Cedar and Google Zanzibar
OPAL – Run policy languages near your app with open source
OPAL (Open Policy Administration Layer) is an open-source administration layer for Policy Engines such as Open Policy Agent (OPA), and AWS’ Cedar Agent. OPAL automates the synchronization between the policy store and the real-time data needed for policy decisions, ensuring that policies are always evaluated with the most up-to-date information.
OPAL allows you to utilize these policy languages to their maximum benefit, bringing your authorization policies up to the speed needed by modern applications.
Please consider supporting our open-source work by giving OPAL a star on GitHub.
Conclusion
Domain-specific declarative languages are proving to be crucial tools in managing complex tasks in software development. They help us build systems that are high-performing, secure, and user-friendly. Whether it’s managing fine-grained access controls or adapting to the demands of AI agents, these languages are keeping us ahead of the curve.
Authorization is a critical component of any modern application, and we can see the tremendous benefit brought to this space with domain-specific declarative languages. Open Policy Agent (OPA), AWS’ Cedar, and OpenFGA allow us to tackle the challenges that come with the modern state of IAM, while OPAL (Open Policy Administration Layer) enhances their functionality by automating the synchronization between the policy store and the real-time data required for decision-making, ensuring that policies are consistently applied with the latest relevant data. This integration enables us to create secure, reliable, and dynamic authorization systems that can adapt to changing conditions and requirements.
Want to discuss policy languages with like-minded people? Our OPAL Slack community is the largest authorization community out there. Join now here → io.permit.io/slack