

Member post originally published on Medium by DatenLord

Background
In distributed system application scenarios, it is inevitable to add or delete nodes or replace nodes, the simplest solution is to temporarily shut down the cluster, then directly modify the configuration file to add new nodes, and then restart the cluster after the completion of the process. This indeed can achieve our purpose, but its problems are also very obvious. During the period of change, the cluster is not available, which is unacceptable to the system that requires high availability. The manual process can cause other errors, for example it might reduce the stability of the system. Therefore, how to change cluster members efficiently and securely has become a key issue in the development of distributed systems. For Xline, it is not only necessary to handle the regular change process, but also to integrate it with the Curp protocol to ensure that the introduction of cluster membership changes does not lead to errors in the front-end protocol.
Problems and Solutions for Dynamic Membership Changes
Since Xline uses Raft as a backend protocol, adding the ability to dynamically change members to Xline requires solving the problems encountered by the Raft protocol itself. A key premise for the successful operation of the Raft protocol is that there can only be one leader at any given time. Without imposing any restrictions, directly adding nodes to the cluster may potentially destroy this premise, as shown in the following figure:
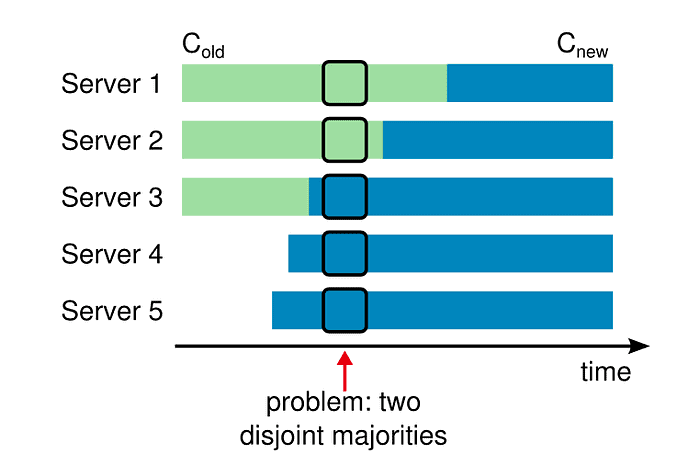
Due to network delays and other reasons, it is impossible to guarantee that each node switches from C_old to C_new at the same time, the possible outcome is shown in the below figure.
Assuming that at this time, Server 1 and Server 5 start to be elected at the same time, Server 1 obtains the votes of Server 2, which meets the quorum in C_old and becomes the Leader. Server 5 receives votes from Server 3 and Server 4, which satisfies the quorum requirement in C_new and becomes the Leader, and then there are two Leaders at the same time, which creates consistency problems.
In order to solve this problem, the authors of Raft provided two solutions.
- Joint Consensus
- Single-step membership change
Joint Consensus
Joint Consensus is essentially adding an intermediate state to the membership change process.
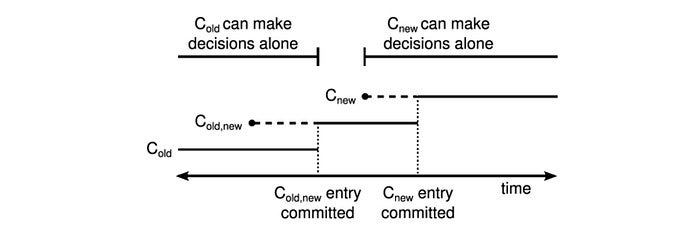
When the Leader receives a membership change request, it creates a C_(old, new) configuration and synchronizes it with the Follower via AppendEntries. The node that receives C_(old, new) will use both configurations to make a decision, i.e., the election and other operations require the agreement of both C_old and C_new to be successful. After C_(old, new)commits, the Leader creates the C_new configuration and synchronizes it with the Follower.
In this scenario, there are several possibilities for the intermediate state of cluster member changes:
- C_(old, new) is created and then committed, there may be two configurations of C_old, C_(old, new) in the cluster at this stage, any node that wants to be the Leader at this stage needs the C_old configuration to agree to it, so there will not be two Leaders.
- After C_old, new is submitted and before C_new is created, there may be two configurations of C_old, C_(old, new) at the same time in this phase, but only nodes using C_(old, new) can become the Leader because most of the nodes in the cluster have already been configured with C_old at this phase and the remaining nodes that have not yet switched are not enough to elect a new Leader.
- C_new is created and then committed. In this phase, there may be three configurations of C_old, C_(old, new), C_new at the same time, in which the C_old configuration is not able to elect the Leader, for the reasons mentioned above .C_(old, new) and C_new need C_new ‘s consent to elect the Leader, and there will not be two Leaders in this case.
- After C_new commits, C_new makes the decision independently, and there will not be two leaders.
Single-step node change
In addition to Joint Consensus, there is another way to do cluster membership changes safely, and that is with single-step node changes. This method only adds or subtracts one node at a time, in this case, the majority of the old and new configurations must have overlapping nodes, and the overlapping nodes can only vote for one node, which ensures that there will not be two Leaders at the same time. Complex change behaviors need to be converted into multiple single-step node changes to complete.
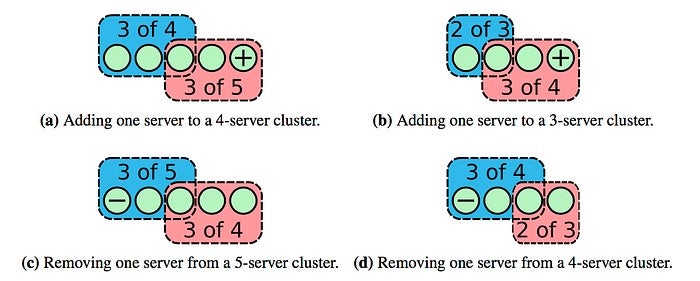
This scheme has no intermediate state, only one step operation can complete the change. The logic is more concise than Joint Consensus, there are not so many complex intermediate state, the realization will be a little simpler, of course, its function is not as powerful as Joint Consensus.
Xline’s current approach is a single-step membership change, and we will add support for Joint Consensus in the future.
Curp Protocol Integration
The main process of Membership change can be accomplished through the back-end Raft, but this process may disrupt the flow of the Curp protocol on the front-end. During normal processing, the Curp client broadcasts a Propose request to all nodes in the cluster, and determines whether this propose is committed in curp based on whether the number of successful proposes is greater than the number of superquorums of the current cluster members, and whether the members are determined at the time of creation of the client, but with the introduction of membership change. Before membership change, all members were determined when the client was created, but after membership change was introduced, there needs to be a mechanism to ensure that when the client is using the old configuration, it can also detect the new configuration used by the server and retry the current request with the new configuration, or else it may cause the Curp protocol to fail to work properly.
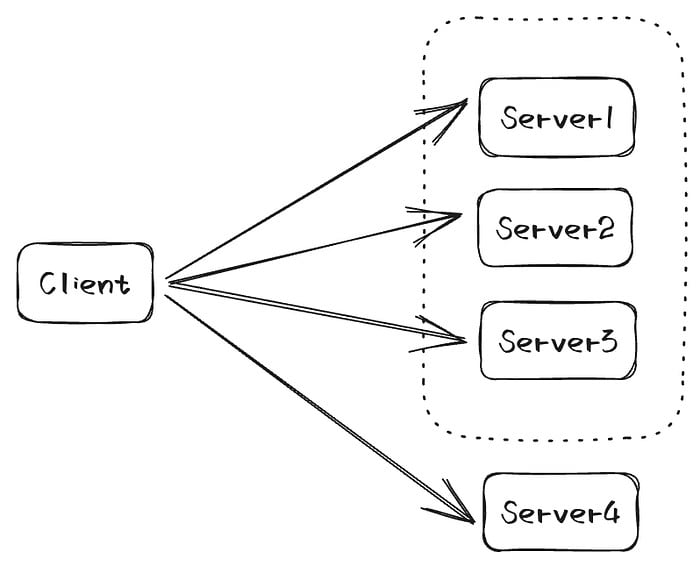
As shown in the figure, suppose the Client broadcasts a Propose to a three-node cluster, then the Client receives three (3 node’s superquorum) successful responses and considers this Propose to have been committed in Curp. During this Propose process, the cluster membership changes and Server4 joins the cluster. However, the superquorum of node 4 is 4, which means that the request that was just committed by curp in the 3-node cluster no longer meets the commit condition of Curp after the membership change, which may result in the loss of the request that has been returned to the Client.
To solve this problem, we introduced a new field cluster_version for requests sent by external clients, which represents the version of the configuration currently in use by the cluster and is modified every time a membership change is performed. So that the Server can use this field to determine whether the client sending the request is using the correct configuration, and directly reject the request using the wrong configuration. After the Client detects the inconsistency of the cluster_version, it will take the initiative to pull the current configuration from the Server and initiate a new round of requests with the new configuration. In the above example, when Propose and membership change happen at the same time, one of the nodes in Server1, 2, and 3 must be using the new configuration, so that node will reject Propose with another cluster_version.After the Client detects the new cluster_version, it will re-pull the current member configuration from the cluster and retries the entire request with the new configuration.
Source Code Interpretation
Leader Initiates Membership Change
The first step in initiating a membership change is to send a ProposeConfChangeRequest to the Leader, which contains information about the nodes to be changed in this proposal and some other auxiliary fields.
When the Server receives the request, it first checks to see if the cluster_versionof the request matches the current cluster_version of the cluster, and rejects any request that doesn’t match, before proceeding to the Server’s processing logic:
/// Handle `propose_conf_change` request
pub(super) fn handle_propose_conf_change(
&self,
propose_id: ProposeId,
conf_changes: Vec<ConfChange>,
) -> Result<(), CurpError> {
// ...
self.check_new_config(&conf_changes)?;
let entry = log_w.push(st_r.term, propose_id, conf_changes.clone())?;
debug!("{} gets new log[{}]", self.id(), entry.index);
let (addrs, name, is_learner) = self.apply_conf_change(conf_changes);
self.ctx
.last_conf_change_idx
.store(entry.index, Ordering::Release);
let _ig = log_w.fallback_contexts.insert(
entry.index,
FallbackContext::new(Arc::clone(&entry), addrs, name, is_learner),
);
// ...
}The Leader node checks the validity of this conf change with the check_new_config method during processing, rejecting in advance changes that cannot be processed, such as inserting a node that already exists or removing a node that does not exist. Once the check passes, it goes through the same process as a regular request, synchronizing to all Follower by consensus. In addition to this part of the same process, the conf change requires some special handling, applying the new configuration as soon as it is inserted into the log and recording the context used to roll back the configuration. This is the same way as mentioned in the Raft paper, after the node owns the log, it doesn’t need to wait for it to commit, it will take effect immediately. In Raft, the logs that are not committed can be overwritten, so it is necessary to record the context, and if the logs are overwritten, it is possible to rollback the change by using this context.
Follower handling of member changes
For a Follower node, the main logic for member changes occurs in handle_append_entries, which is used to process logs sent by the Leader, including conf change.
pub(super) fn handle_append_entries(
&self,
term: u64,
leader_id: ServerId,
prev_log_index: LogIndex,
prev_log_term: u64,
entries: Vec<LogEntry<C>>,
leader_commit: LogIndex,
) -> Result<u64, (u64, LogIndex)> {
// ...
// append log entries
let mut log_w = self.log.write();
let (cc_entries, fallback_indexes) = log_w
.try_append_entries(entries, prev_log_index, prev_log_term)
.map_err(|_ig| (term, log_w.commit_index + 1))?;
// fallback overwritten conf change entries
for idx in fallback_indexes.iter().sorted().rev() {
let info = log_w.fallback_contexts.remove(idx).unwrap_or_else(|| {
unreachable!("fall_back_infos should contain the entry need to fallback")
});
let EntryData::ConfChange(ref conf_change) = info.origin_entry.entry_data else {
unreachable!("the entry in the fallback_info should be conf change entry");
};
let changes = conf_change.clone();
self.fallback_conf_change(changes, info.addrs, info.name, info.is_learner);
}
// apply conf change entries
for e in cc_entries {
let EntryData::ConfChange(ref cc) = e.entry_data else {
unreachable!("cc_entry should be conf change entry");
};
let (addrs, name, is_learner) = self.apply_conf_change(cc.clone());
let _ig = log_w.fallback_contexts.insert(
e.index,
FallbackContext::new(Arc::clone(&e), addrs, name, is_learner),
);
}
// ...
}The handling of regular logs will not be repeated here. When the Follower tries to append the logs from the Leader, it will determine what new conf change logs are available on the current node, and what conf changes that have not been committed will be overwritten. Then, using the pre-recorded context, it rolls back the overwritten changes in reverse order and applies the new changes. When applying a new change, the context of the new change should be recorded here as well.
Commit of member changelog
async fn worker_as<C: Command, CE: CommandExecutor<C>, RC: RoleChange>(
entry: Arc<LogEntry<C>>,
prepare: Option<C::PR>,
ce: &CE,
curp: &RawCurp<C, RC>,
) -> bool {
// ...
let success = match entry.entry_data {
EntryData::ConfChange(ref conf_change) => {
// ...
let shutdown_self =
change.change_type() == ConfChangeType::Remove && change.node_id == id;
// ...
if shutdown_self {
curp.shutdown_trigger().self_shutdown();
}
true
}
_ => // ...
};
ce.trigger(entry.inflight_id(), entry.index);
success
}In the after sync phase after a conf change is committed, besides some general operations, we need to determine if the committed conf change removes the current node, and if it does, we need to shutdown the current node here. Generally, only the leader node will execute here and commit the logs of the removed node, and after it shutdowns itself, the remaining nodes will elect a leader with the latest logs.
New Node joins the cluster
In order to distinguish between a node that creates a new cluster to run on, and a newly started node that needs to join an existing cluster, a new parameter InitialClusterState needs to be passed in at startup. This is an enumerated type with only two members. InitialClusterState::New indicates that the node started this time is one of the members of the newly started cluster; InitialClusterState::Existing indicates that the node started this time is a new node to be added to an existing cluster.
let cluster_info = match *cluster_config.initial_cluster_state() {
InitialClusterState::New => init_cluster_info,
InitialClusterState::Existing => get_cluster_info_from_remote(
&init_cluster_info,
server_addr_str,
&name,
Duration::from_secs(3),
)
.await
.ok_or_else(|| anyhow!("Failed to get cluster info from remote"))?,
_ => unreachable!("xline only supports two initial cluster states: new, existing"),
};The essential difference between these two approaches is that when a new cluster is created, the initial cluster members of each node are the same, and a globally unified node ID can be computed directly from this initial information to ensure that each node has a unique ID, whereas when joining an existing cluster, the new node cannot compute the node ID on its own, and needs to retrieve the information about the existing cluster through the get_cluster_info_from_remote method to directly inherit the ID and other information that the existing cluster is using to ensure the correspondence between the ID and the node within the cluster. This ensures the correspondence between IDs and nodes in the cluster, and avoids duplicate IDs or a node with multiple IDs.
To ensure compatibility with the etcd interface, a new node does not have a name before it starts running. etcdctl determines whether the corresponding node has started based on whether the name is empty. After a new node is up and running and joins the cluster, it sends a Publish Rpc to the Leader to publish its name in the cluster.
Node remove
Suppose we don’t shut down a node after removing it, then it will elect a timeout and send Vote requests to the rest of the nodes, wasting network and CPU resources of the other nodes. To solve this problem, there are two ways we can think of.
1. Shut down the node immediately after it applies the new configuration that will remove itself. Obviously, this solution must be infeasible. Because in the application of the new configuration, this log has not been committed, there is still the possibility of being backed up, if you close itself here, then if the configuration change occurs back, the node that was removed will have been closed and can not be directly replied to, which is not the result we want to see.
2. Shut down the node immediately after the node commit removes its own logs. Because it has already been committed, this method does not have the above problem, but if you implement it accordingly, you will find that the removed node sometimes still cannot be closed automatically. Because the removed node may not commit the new configuration at all. Suppose we want to remove a Follower node, and the Leader adds this removal record to its own log, and then immediately starts to use the new log, at this point, the Leader will not send any request to the Follower, and the Follower will naturally not be able to commit the record. Naturally, the follower cannot commit this log and shut down itself. This problem does not exist for the Leader, which will temporarily manage the cluster without itself until the log is committed.
If the most direct methods don’t work, how should the removed node shut itself down? Assuming we don’t add the shutdown logic here, what happens is that the Leader synchronizes the conf change log to the cluster, and all members of the new cluster will process and commit this log normally. The removed node will leave the cluster without knowing about it and will not receive a heartbeat from the Leader. This node then times out and starts an election, which is where we finally decide to make the change.
pub(super) fn handle_pre_vote(
&self,
term: u64,
candidate_id: ServerId,
last_log_index: LogIndex,
last_log_term: u64,
) -> Result<(u64, Vec<PoolEntry<C>>), Option<u64>> {
// ...
let contains_candidate = self.cluster().contains(candidate_id);
let remove_candidate_is_not_committed =
log_r
.fallback_contexts
.iter()
.any(|(_, ctx)| match ctx.origin_entry.entry_data {
EntryData::ConfChange(ref cc) => cc.iter().any(|c| {
matches!(c.change_type(), ConfChangeType::Remove)
&& c.node_id == candidate_id
}),
_ => false,
});
// extra check to shutdown removed node
if !contains_candidate && !remove_candidate_is_not_committed {
return Err(None);
}
// ...
}We have added additional checking logic in the ProVote phase, the node that receives the pre-vote will check whether the candidate has been Removed. Assuming that the candidate is not in the current node’s configuration, and that the possible fallback operation will not allow this node to rejoin the cluster, it means that this is a candidate that has been Removed. The node that handles the request will send a special VoteResponseto Follower with a shutdown_candidate field. Candidate receives the response and determines if shutdown_candidate istrue, and if it is, it starts shutting itself down, and if it is not, it continues the election process.
Summary
In this post, we dive into how cluster membership changes are performed in distributed systems, briefly introducing the two main solutions: Joint Consensus and Single-Step Membership Change. Joint Consensus introduces an intermediate state to ensure that there are no two leaders during a change. Single-step cluster change sacrifices some functionality and simplifies the implementation logic by changing nodes one by one. In addition, we have analyzed the source code of Xline’s current single-step membership change scheme, showing how both Leader and Follower handle changes, and what new logic needs to be handled after the introduction of cluster change.
Currently, Xline only uses a single-step cluster change to handle cluster membership changes, providing a basic change capability. In the future, we will try to support Joint Consensus to enhance the functionality of Xline.
That’s it for Xline’s Membership change. If you’re interested in more implementation details, please refer to our open source repository at https://github.com/xline-kv/Xline or learn more at the Xline website: https://xline. cloud.