Member post by Fredric Newberg, CTO and Co-Founder of Embrace
If you have a business-critical mobile app, you might be surprised to learn that your observability solution is dropping a large percentage of your mobile app observability data. That’s because data from mobile devices is frequently delayed from when it’s collected client-side to when it’s ingested server-side. But why exactly is that, and how does it affect observability into your mobile experiences?
The reality of collecting data from mobile devices
When collecting data from mobile devices, you have to accept that – unlike with backend observability – you don’t control the whole system. The devices you are collecting data from are out in the wild in people’s hands. As such, they are a heterogeneous source of data with widely varying usage patterns and network connectivity.
The assumption in backend and web monitoring – that the user has a connection to the observability service – does not hold for mobile, yet many observability tools have this explicit expectation of near constant connectivity. However, in mobile apps, people’s connectivity varies wildly.
This brings us to one of the harsh realities of mobile observability, that data is frequently delayed. Data collected on mobile devices can take hours, or even days, to get sent to backend systems.
To put this in perspective, most DevOps teams would consider a server being offline for a single day, and not delivering observability data, to be something very much out of the norm. With some mobile apps, that is the norm rather than the exception.
What contributes to data delays in mobile apps?
One key way that mobile apps vary in their data delay profiles is their usage patterns. Consider health and wellness apps that are used in remote areas for navigating trails. Or internal productivity apps for use in warehouses, agricultural areas, or oil rigs. Wherever connectivity is strained, you’ll tend to see larger data delays.
However, a key benefit of mobile apps is that they can be used anywhere. So even location-agnostic apps like shopping and mobile games can still have heavy usage under poor connectivity. People play mobile games when they’re taking the metro or riding the bus. Or they place mobile food orders when they’re driving to a nearby fast food restaurant.
As a further example, in our customer base – which includes mobile apps across every industry and category – we only see a small percentage of apps that do not have any instances of data that is delayed by at least a day.
Beyond usage patterns, the iOS and Android ecosystems also impact the delay of data. When apps crash on iOS, the crash will not be reported until the app is relaunched. On Android the situation is a little better in that the majority of crashes that happen in Java or Kotlin code can be reported with limited delay if there is an internet connection, but crashes that occur in native code will not be reported until the next app launch. Thus the end users’ behavior, especially on iOS, impacts when you will actually receive the data that indicates that you have a stability problem in your app.
Why do these data delays matter?
Let’s start out with the obvious – you want to have a complete picture of what your mobile app is doing. If your backend system discards any data that arrives 3 hours after it was collected on a device, you will have a large visibility gap. In the graph below, you can see how much visibility you would lose from discarding delayed data.
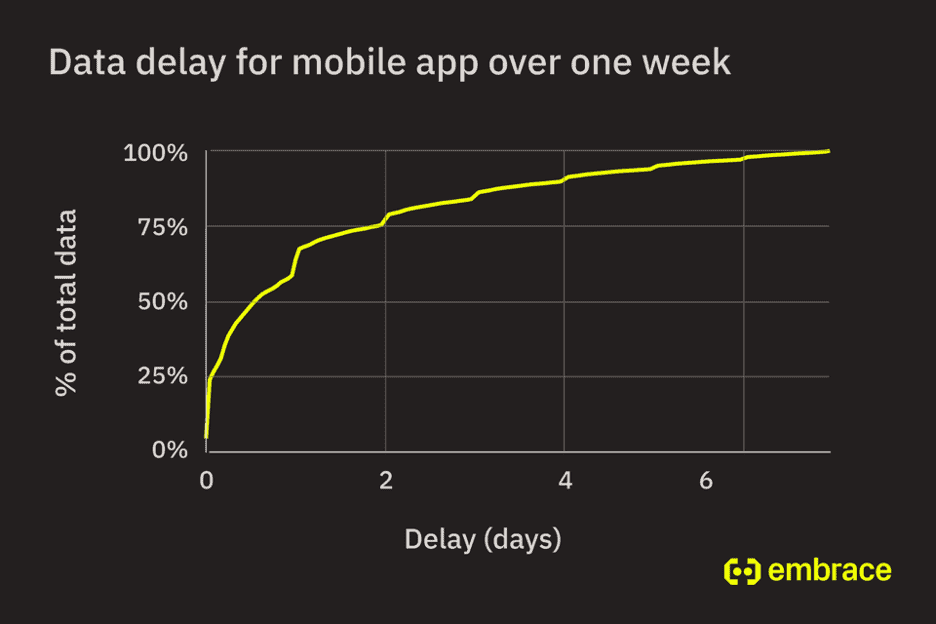
This data is pulled from a customer that has above average data delays. Note how 25% of data does not arrive for at least 2 days after it’s collected on the mobile device, and 100% of data does not arrive for approximately 1 week.
Why would you ever discard delayed data?
So if this is typical behavior for mobile applications, it begs the question – why would you ever discard delayed data? Well, as mentioned above, this is not the typical behavior for backend observability. If your system was designed to handle data from backend applications, supporting delayed data is probably not a concern that you had. And while it may not be that challenging to modify, or costly to operate, a system capable of handling delayed data when the data volumes are moderate, once you get to larger data volumes, you’ll start to experience serious challenges.
At Embrace, we have only ever been focused on mobile observability, so we have built our system from day one with the expectation that we will be getting a substantial amount of data that is delayed. We have chosen building blocks that allowed us to efficiently store delayed data and used data schema that accommodated the delayed data to be stored and queried such that the larger time windows that have to be considered did not lead to excessive penalties in query performance.
If mobile is a growing priority within your organization, you should already be planning for how you’ll address issues with delayed data at scale.
What can you do today about delayed data issues?
A simple solution is to just use the time that the data is reported to the observability service as the time of the event. However, this tends to lead to more confusion than it helps. Let’s consider how this would impact tracking down crashes in a new app version that you just released.
Your team sees a spike in crashes, so you launch an investigation to track down the root cause and then release a new version. The crash rate goes down, and all is good.
But what happens when users on the previous version that crashed – who were too frustrated to relaunch your app – have finally decided to give it another go. They launch the app again, which sends a crash report from the device. If your observability tool marks those crashes as having just occurred, you might think the issue is still ongoing, even though you released a fix for it.
So why not do the right thing and map the data to the time that the events occurred? You will have to pay the price for doing so at either ingestion or query time, or sometimes even both. Most of the commonly-used databases that support scale at a cost-effective price point have tradeoffs that make ingesting delayed data non-trivial. If you take the simpler approach to ingestion though, you will end up paying the price at query time, where you may be querying an order of magnitude more data, depending on how much delay you have decided to support, than you would under normal circumstances for non-delayed data.
Closing thoughts
Given the value generated by mobile apps and how critical they are to many businesses today, operating based on a subset of observability data is not a sound strategy. Mobile applications cannot be monitored effectively by traditional observability solutions for a variety of reasons, with the delayed nature of mobile data being a critical one.
You’re not alone in realizing the challenge in getting the full picture of mobile observability data. The good news is, there are solutions today, from mobile-first approaches to configuring existing backend systems to account for the sharp corners of mobile data capture. As mobile’s growth accelerates, we’re also seeing open source communities and governing groups rethink what mobile telemetry standards should be. It’s exciting to see what mobile observability will look like in the near future.
Author bio
Fredric Newberg
Fredric Newberg is CTO and Co-Founder of Embrace, the solution to help engineers manage the complexity of mobile to build better, bolder experiences. Companies like Wildlife, TakeTwo, GOAT, Yahoo! Fantasy Sports, and The New York Times use Embrace to identify any user-impacting issues with detailed technical context to resolve them instantly.
Fredric has great experience in building backend systems to handle the high data volumes that mobile game analytics platforms require. He was a founding engineer at Kontagent (now Upsight), a large-scale mobile analytics platform for top game developers. He designed and built backend systems that handled 1500 applications, 250M monthly active users, and 150B events each month for customers around the globe. He then was a founding engineer at Rave, one of the top social graph toolkits for mobile game developers. Rave handled Pokemon Go’s launch in 2016.
Reach out, let’s continue the conversation:
https://www.linkedin.com/in/fredricnewberg/