
Member post originally published on Elastisys’s blog by Lars Larsson
This article is all about demystifying container platforms and showing what value they bring on several levels: business, organization, and tech. There is a summary at the end, but if you can’t wait: it’s all about realizing that platform operations, with the right tools, can be seen as a commodity, and is therefore possible to centralize internally or outsource. Both lead to significant increases in return of investment (ROI) and the reduction of operational expenses. If platform administration is also outsourced, it also leads to a substantially lower total cost of ownership (TCO).
Why do we have software containers?
It would be tempting to ask this question straight away. Why do we have containers? But let’s back it up just one step!
Why do we have software?
Every single software company exists to serve the needs of its customers, where the exact purpose is, of course, individual to each company. You meet those needs in many different ways, and most, if not all, are assisted by software. But it is important to note that software is not really the end, but rather just the means of providing value to your customers or end users.
What customers care about is the functionality and features they get from your applications. Secure handling of their data is one such feature – but it’s not the only one . Developing the right application is therefore very important. But for applications to have any value, they need to somehow get into the hands of your customers. Let’s therefore look at how software deployment is done!
Software Deployment Before Containers
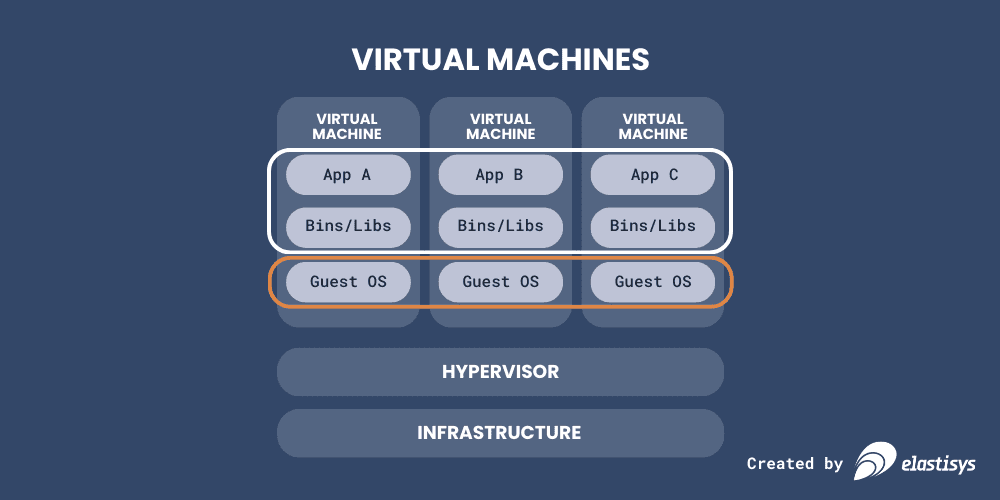
Right now, most companies that are not using containers are basically using either physical or virtual machines (VMs for short) to deliver the back end of their applications to customers.
VMs are a way to share underlying hardware (“infrastructure” in the image), which is great for cost-efficiency: most servers are not used to the max all the time, so putting multiple on a single physical machine helps get better utilization overall. But you will note that it is only in the top part (marked with a white border) of the image that the applications and their associated third-party binaries and libraries are. These are what software developers across all companies work with to make sure the applications meet customer demands.
The applications are what drive business value. This is what customers care about. Therefore, ideally, all engineering time should be spent on developing applications as well. Everything else is, essentially, overhead.
But the bottom part within the virtual machine, the “guest operating system” (marked with orange), is not really driving business value. It’s much more a means to an end; it just “has to be there.” And in fact, keeping it secure and up-to-date is more of a chore than something developers enjoy. Not doing it puts data at risk. Doing it takes valuable time, and because it can cause disruption to the application on top, developers will often want to put off updates for as long as they can. So then the data is at risk. That’s a problem!
There is also a second big problem with this picture. One which is less obvious: the applications, libraries, and guest operating systems are all “moving parts.” You have to do some considerable work to ensure that they are all on the same versions, and that they are harmonized in configuration as well. Some software companies solve this with automated deployment tools, but many others handle this as a task that requires manual work. This, of course, comes at the risk of human error. Also a problem!
Software deployment with containers
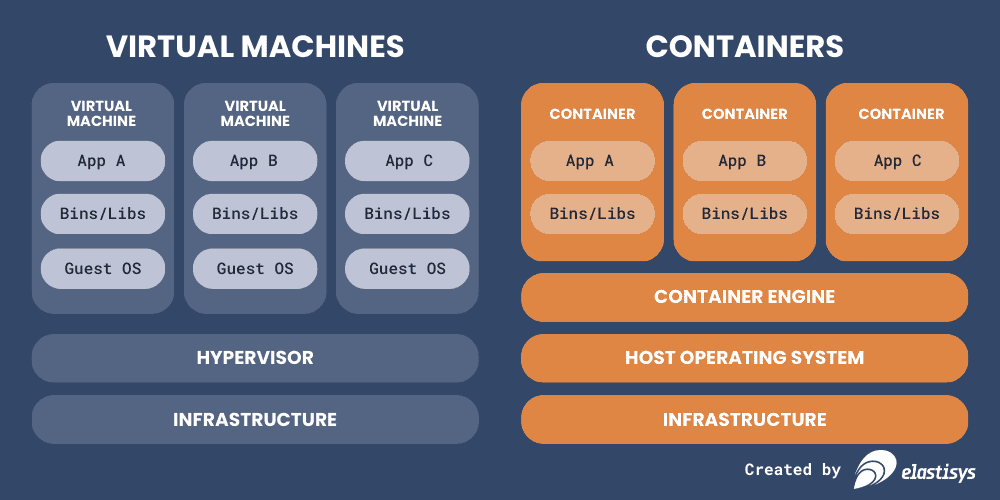
Containers, on the other hand, are more lightweight than virtual machines. Containers differ from VMs in two important ways.
First, they are a single, immutable package of applications and all the supporting code (binaries and libraries). The parts that you actually care about, as an organization that wants to deliver a software service of value to your customers.
Second, they do not require a full operating system each, but instead, run on a shared one. Of course, they are still isolated from each other, so they don’t interact with each other in other ways than they are supposed to, such as via the network. This makes even more efficient use of the shared hardware underneath because there is just one operating system running, not a hypervisor hosting as many full operating systems as there are applications.
These differences on the technical side lead not just to benefits on the technology side. They also lead to benefits in terms of both the business and organizationally.
What makes software containers better than VMs?

Because they work with a single shared operating system, rather than every VM having to bring their own, your resource usage is vastly improved. And because containers are much more lightweight than VMs, you can pack more of them onto a single host (virtual or physical), which improves utilization. The business value of this is that you have to go buy new servers less often. This lowers your expenses (OPEX if cloud, CAPEX if physical machines), making it more cost-effective than VMs while still having the major benefits of them.
Organizationally, containers lend themselves to a clearer division of responsibility and labor: developers can focus on developing applications, free from system administration duties as in the VM deployment model. Instead, a platform team can take over the responsibility to ensure that the single-host operating system is secure and provides a safe deployment for the applications.
Platform teams can either be internal or external to the organization. An internal team is a good idea if managing servers is core to the business, and therefore brings tangible value to the customers. They can also be external by using a fully managed service. This is perfect if one values the cost savings that come from focusing engineering time on the applications instead.
With a clearer division of responsibility, where application developers focus on their applications and system administrators focus on the container hosting machines, your security posture in the organization improves overall. Developers seldom have the time, required up-to-date knowledge, or incentives to prioritize security and system administration. And neither should they – their work is difficult enough! By letting developers develop and administrators administer, you get reduced complexity overall, and the inherent risk of assigning tasks outside of people’s core skill sets is mitigated.
This is especially, or perhaps only, true if you employ security-focused system administrators and if you want to have an internal platform team. If you go for a fully managed service, you should of course choose a provider that is hyper-specialized in security and compliance with any relevant regulations, so they support your application developers. (Elastisys happens to be just that.)
The container format is simple and highly standardized, meaning that any Linux server can run any Linux container out there. Once the packaged container “image” is downloaded to a host, it starts just as fast as any other program on the host. There is no “boot-up” phase since, at that point, it’s just a standard program on the machine.
Because applications are packaged with every single software dependency they have, a container image will run exactly the same on my laptop as it does in testing and in production. So when you’ve tested that a particular container behaves as you expect, it is that exact same container image that will be deployed in production later on.
Traditional servers are managed in a mutational way: you have servers whose exact configuration and set of software evolve over time. With containers, you don’t need to ensure that, for instance, the .NET runtime is upgraded on each server so that a new version of the application can run there. But a container is packaged with all its dependencies, and there is therefore never any step where you need to ensure that X gets installed before Y; all dependencies are already baked in and ready to go. This means you have no “in-between steps” when you upgrade; you always go directly from the old version to a new, known-good version. No states in between. This greatly reduces the risk of human error and of manual work overall.
What does it take to run production-grade software?
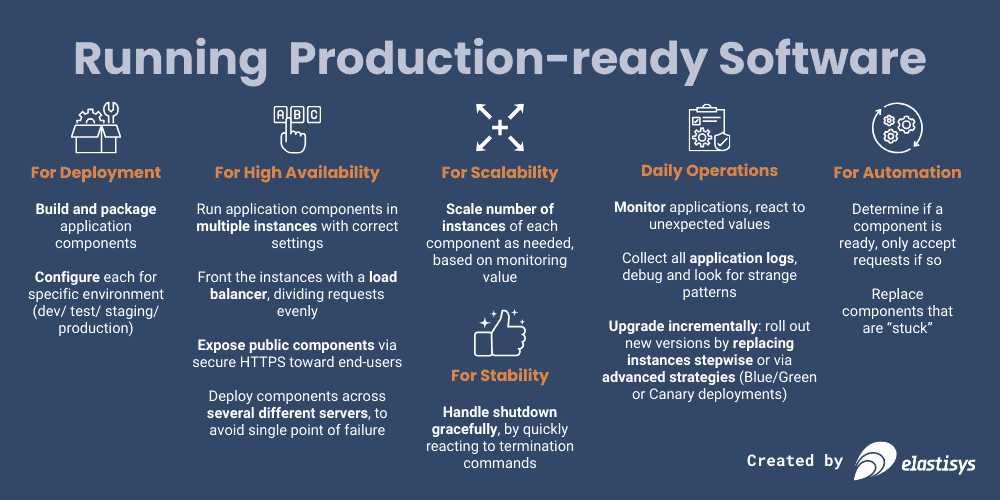
First, software needs to be built and packaged. And yes, this is an article about container platforms, but note that what I’m talking about here is just generic requirements for running software in production in general.
Each software development lifecycle phase requires a different configuration. The built and packaged software, however, should remain the same. This way, you improve your quality assurance processes, because the built code that has undergone all testing is also the one to eventually be deployed to production. These changes account for, e.g., that a development deployment probably has different log levels, a throwaway database, and fewer requirements on redundancy than a staging or production environment.
To achieve high availability, you need to run application components on multiple instances. And of course, to make good use of them, you need to expose these instances, either internally within your system or externally to end-users. This is done via some kind of load balancer that divides requests evenly and only to instances that can handle requests at this time. If you expose components externally, that needs to be done in a secure way. And to get really high availability, you also need to make sure you’re actually using different servers, so one machine having problems will not take down all your instances.
For scalability, you have to dynamically adjust the number of running instances, up or down, based on some monitored value.
For stability, you have to have advance notice of when an instance will be terminated, and then you have to also react to that when it happens. This is the time when an application will make sure to write all the data it is currently processing down to disk or to a database, for instance, so no data will be lost just because an instance is terminated.
For automation, you have to have a way to determine if component instances are ready and a way to only send requests to such instances. Alternatively, you also need to be able to figure out if they are stuck somehow, and all that can help is to restart them.
Once deployed, operations take over. Once a component is in production, it also has to be monitored; its logs have to be collected, and you need to be able to react to any strange values in either the monitoring data or in the logs. And since no software lives forever, you have to have some upgrade strategy: incremental replacement of instances or via some more advanced strategy, like Blue/Green or Canary deployments.
Note: did I even once mention containers here? No! This was all about the best practices of running software in production. On a very high level, I agree, but here’s the thing. With thousands upon thousands of companies out there, there are almost as many different bespoke solutions to achieving these goals. Does it have to be that way? Does solving the same general problem, deployment and operating software in production, actually bring value? No, it doesn’t really add value, and no, it doesn’t have to be that way.
The overall message I’m getting to is that it is your software that is unique; how to run it is not.
Software is unique; how to run it is not
I’m sure you agree that running software in production sounds like a problem that we have been facing for a long time. The problem of running software in production has been basically the same, even if our attempted solutions have been different. What sets the latest iteration of solutions apart from earlier ones is that we are now getting to the point where we get more opinionated solutions, and by being opinionated, they can support us more.
As a community, we have standardized on how to package software. In fact, we don’t even care about which programming languages are used for the software, the container image format is the same. So it doesn’t matter if some team loves Python, another NodeJS, and yet a third .NET – it all gets packaged the same, and it runs the same. We’ve standardized on how to get logs from the containerized software, and we have standard ways of monitoring the containerized software, too, because it’s up to the “container runtime” to show how much memory, etc. the software uses.
And with so much opinionated standardization, it should come as no surprise that we can ensure that software runs nicely across multiple servers as well. We’ve reached that point now.
The art of deploying and operating software is rapidly becoming a commodity, thanks to standardized and opinionated tools.
Sometimes you will hear about software being “cloud native”, which is a fancy way of saying that it’s been developed specifically for the cloud. It knows how to thrive in such an environment, and it does so by leaning on the automation features that our opinionated container platforms provide us with.
Container Platform in 2023 = Kubernetes
Kubernetes is the industry standard for container platforms. It was created and open-sourced by Google in 2015 and has since become widely adopted across the globe.
If you’re a fan of numbers and statistics, you will enjoy that in 2021, 96% of respondents had a Kubernetes adoption strategy when the CNCF asked. And in 2022, half of all companies using containers used Kubernetes, according to DataDog. It’s taking the industry by storm, and there’s no stop in sight. Garner predicts that in 2027, 90% of global organizations will use Kubernetes.
Why is Kubernetes taking the world by storm? Because it is very convenient!
How is Kubernetes convenient to use?
The way you express to Kubernetes what it should do is declarative: you give it a description of what you want, and it makes sure you get it. You don’t have to specify how this should happen (that would have been imperative, like most programming languages). So, obviously not using human language, you can tell it to do the following:
“Run v1.0.1 of MyApp,
autoscale between 3 and 10 instances to keep CPU usage at a 60% target,
spread instances across different underlying servers,
connect them to my production database using these secret credentials,
attach 50GB network storage to each instance, letting the storage move along if the instance has to move to another server, when I upgrade, do it one at a time, ensuring that my custom readiness tests pass before advancing to the next instance, and run this helper command so the application shuts down cleanly when an instance should stop…
…and make sure to do all this even if underlying servers crash.”
But, this being 2023, of course you can just paste that into ChatGPT and get the corresponding Kubernetes-”code” out. It actually worked pretty well when I tried it, see this ChatGPT history for yourself!
Read more about Kubernetes and container platform security:
Read the following related articles of ours to learn more about the secure deployment of containers in production:
- How to NOT run containers as root
- How to security harden Kubernetes platforms
- How to security harden Kubernetes against unknown unknowns
- How to Operate secure Kubernetes platforms
Summary and closing thoughts
Software is unique; how to run it is not. You don’t need to reinvent the wheel, because there is a perfectly fine one out there, and you can find people who know how to use it. This is true thanks to industry-wide standardization, unlike a home-grown system.
Greatly increased innovation speed and reduced system administration. It is true that systems still have to be administered, of course. Those of you who are great at administering servers and releasing software are still very much needed. But instead of having to solve every problem yourself, you’re getting new supporting tools that have been improved upon by a massive global community over the past almost a decade.
Production-grade automation, scalability, and fault tolerance – because so much is automated, you have near-instant and always-on automatic handling of failures. This means much less difficult firefighting overtime for employees.
Because Kubernetes is controlled using these declarative operations that we just saw an example of, and it’s all expressed in code, you have the benefits you as developers are used to. You can easily see who changed what and when. You can run static analysis and policy-as-code tools to avoid mistakes, even if you run one-off commands.
And you also get unified software deployment and operations across departments within your organization, which makes skill and knowledge transfer much easier, and it also becomes easier to establish and improve upon a baseline. A much smaller team can work on defining your organization’s baseline and deployment pipelines, leading to a more efficient organization and lower operational expenses for the business.
Imagine how much better it would be to have everyone on the same page when it comes to how software is deployed and operated. How much cost this would save, and how much easier it would be to solve the problems that matter most to your customers, if bespoke system administration was a problem of the past!
The best way to make sure that system administration is a completely solved problem is to have someone else do it. This is also the most cost-effective way, because it is definitely not the system administration work that actually drives value for your customers. It’s what benefits they get from your applications.
So shouldn’t that be where your time, effort, and money are spent?