



Member post originally published on the Amplication blog by Levi Van Noort
Introduction:
Over the last decade, there have been notable shifts in the process of delivering source code. One of the more recent adaptations on the deployment aspect of this process has been the declarative and version controlled description of an application’s desired infrastructure state and configuration – commonly referred to as ‘GitOps’. This approach has gained popularity in the context of cloud-native applications and container orchestration platforms, such as Kubernetes, where managing complex, distributed systems can be challenging.
As this desired state is off declarative nature, it points to a specific/static version of that application. This offers significant benefits, particularly the fact that it is possible to audit changes before they are made, roll back to a previous state and maintain a reproducible setup. Without requiring a pipeline to make changes in the application’s state/configuration, how can we move to the more recent application version while avoiding manual version adjustment?
This is where Argo CD Image Updater comes in; it verifies if a more recent version of a container image is available, and subsequently triggers the necessary updates of the application’s Kubernetes resources or optionally these changes in the associated version control.
Overview:
Prior to diving into the technical implementation, let’s establish an overview of the GitOps process and highlight the role of Argo CD Image Updater within this process.
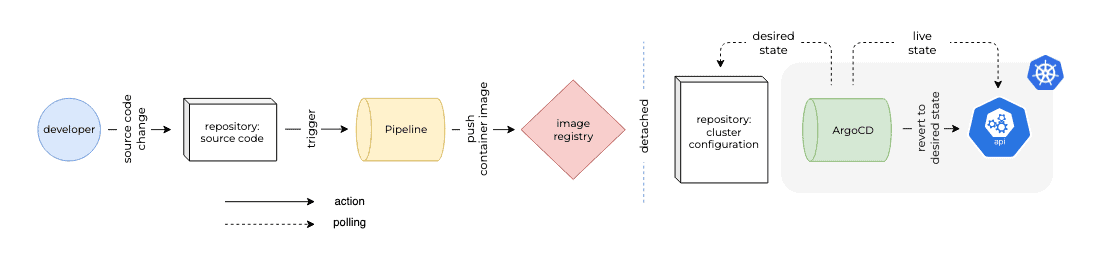
Default GitOps
The first part of process starts with a developer modifying the source code of the application and pushing the changes back to the version control system. Subsequently, this action initiates a workflow or pipeline that both constructs and assesses the application. The outcome is an artifact in the form of a container image, which is subsequently pushed to an image registry.
In a second – detached – part of the process, the cluster configuration repository is the single source of truth regarding the the desired state of the application configuration. Argo CD periodically monitors the Kubernetes cluster to see if the live state differs from the desired state. When there is a difference, depending on the synchronization strategy Argo CD tries to revert back to the desired state.
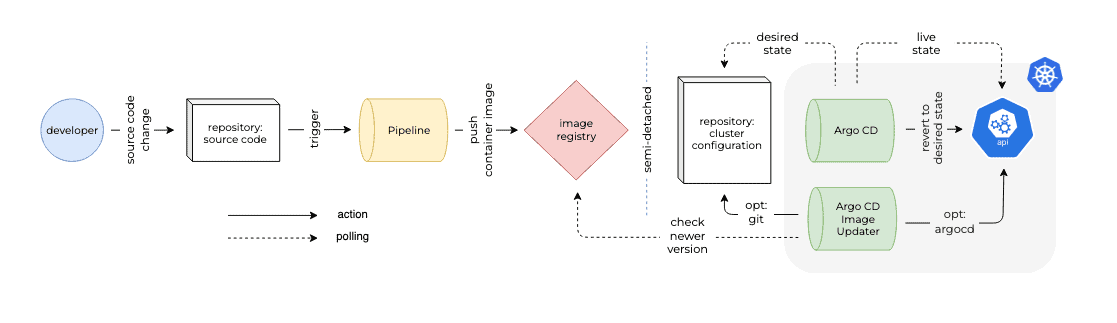
Extended GitOps
Compared to the default process, in this extended, variant another Argo CD component is added to the Kubernetes cluster. The Argo CD Image Updater component verifies if a more recent version of a container image exists within the image registry. If such version is identified, the component either directly or indirectly updates the running application. In the next section we’ll delve into the configuration options for the Argo CD Image Updater as well as the implementation of the component.
Configuration:
Before the technical implementation we’ll familiarize ourself with the configuration options Argo CD Image Updater provides. This configuration can be found in two concepts, the write back method and update strategy. Both have options tailored to specific situation, so it is good to understand what the options are and how that equates to the technical implementation.
For this configuration/demonstration the following repositories can be referenced
Write Back Method
At the moment of writing Argo CD Image Updater supports two methods of propagating the new versions of the images to Argo CD. These methods also referred to as write back methods are argocd & git.
argocd: This default write back method is pseudo-persistent – when deleting an application or synchronizing the configuration in version control, any changes made to an application by Argo CD Image Updater are lost – making it best suitable for imperatively created resources. This default method doesn’t require additional configuration.git: The other write back method is the persistent/declarative option, when the a more recent version of a container image is identified, Argo CD Image Updater stores the parameter override along the application’s resource manifests. It stores the override in a file named.argocd-source-<application-name>.yaml, reducing the risk of a merge conflict in the application’s resource manifests. To change the write back method the an annotation needs to be set on the Argo CDApplicationresource. In addition the branch the to commit back to can optionally be changed from the default value.spec.source.targetRevisionof the application. From an audit trail and a reproducible perspective, this is the desired option. It provides us with the option to have automatic continuous deployment, while keeping these aspects that GitOps is known for.argocd-image-updater.argoproj.io/write-back-method: git
[!NOTE]
When using thegitwrite back method, credentials configured for Argo CD will be re-used. A dedicated set of credentials can be provided, this and more configuration can be found in the documentation.
Update Strategies
In addition to the choice of which write back method to use we need to decide on a update strategy. This strategy defines how Argo CD Image Updater finds new versions of an image that is to be updated. Currently four methods are supported; semver, latest, digest, name.
Before looking at their respective differences, we’ll need to know what mutable and immutable image tags are. A mutable repository has tags that can be overwritten by a newer image, where as when a repository configuration states that tags must be immutable – it can’t be overwritten by a newer image. From the options below each options expects immutable tags to be used, if a mutable tag is used the digest strategy should be used.
semver: Updates the application to the latest version of an image in an image registry while taking into consideration semantic versioning constraints – following the formatX.Y.Z, whereXis the major version,Yis the minor version andZthe patch version. The option can be configured to only bump, to newer minor or patch versions – it also supports pre-release versions through additional configuration. In the example below the application would be updated with newer patch version of the application, but not upgrading when a newer minor or major version is present.argocd-image-updater.argoproj.io/<alias>.update-strategy: semver argocd-image-updater.argoproj.io/image-list: <alias>=<repository-name>/<image-name>[:<version_constraint>]latest: Updates the application with the image that has the most recent build date. When a specific build has multiple tags Argo CD Image Updater picks the lexically descending sorted last tag in the list. Optionally if you want to consider only certain tags, an annotation with a regular expression can be used. Similarly an annotation can be used to ignore a list of tags.argocd-image-updater.argoproj.io/<alias>.update-strategy: latest argocd-image-updater.argoproj.io/image-list: <alias>=<repository-name>/<image-name>digest: Updates the application based on a change for a mutable tag within the registry. When this strategy is used image digests are be used for updating the application, so the image on the cluster for<repository-name>/<image-name>:<tag_name>appears as<repository-name>/<image-name>@sha256:<hash>.argocd-image-updater.argoproj.io/<alias>.update-strategy: digest argocd-image-updater.argoproj.io/image-list: <alias>=<repository-name>/<image-name>:<tag_name>name: Updates the application based on a lexical sort of the image tags and uses the last tag in the sorted list. Which could be used when using date/time for tagging images. Similar to the latest strategy, a regular expression can be used to consider only specific tags.argocd-image-updater.argoproj.io/<alias>.update-strategy: name argocd-image-updater.argoproj.io/image-list: <alias>=<repository-name>/<image-name>
Implementation:
We’ll start out by creating two repositories as can been seen within the overview, a source code and a cluster configuration repository. Theoretically both could be housed in the same repository, but a separation of concerns is advised.
The next step would be to setup the continuous integration pipeline to create the artifact, i.e. container image, that are to be used as a starting point in the continuous deployment process. In this walkthrough we’ll use GitHub for our repository as well as GitHub Actions for our pipeline. However this setup can be made in most popular version control/pipeline options.
Continuous Integration Workflow
Within the source code repository under the .github/worksflows/ directory we’ll create a GitHub actions workflow, which we name continuous-integration.yaml. This workflow consists of checking out the source code, building the container image and pushing it to the GitHub Packages Image registry.
name: continuous-integration
on:
push:
branches: ["main"]
tags: ["*"]
pull_request:
branches: ["main"]
env:
REGISTRY: ghcr.io
IMAGE_NAME: ${{ github.repository }}
jobs:
build-and-push:
name: build and push container image
runs-on: ubuntu-latest
permissions:
contents: read
packages: write
steps:
- name: checkout source code
uses: actions/checkout@v4
- name: authenticate with repository
uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: image metadata
uses: docker/metadata-action@v4
id: meta
with:
images: "${{ env.REGISTRY }}/${{ env.IMAGE_NAME }}"
tags: |
type=sha,prefix=sha-
type=ref,event=pr,prefix=pr-
type=ref,event=tag,prefix=tag-
type=raw,value=${{ github.run_id }},prefix=gh-
type=raw,value=${{ github.ref_name }}
type=raw,value=latest,enable=${{ github.ref_name == 'main' }}
- name: build and push
uses: docker/build-push-action@v5
with:
context: .
push: true
tags: ${{ steps.meta.outputs.tags }}
labels: ${{ steps.meta.outputs.labels }}For simplicity sake the image registry is made public so that additional authentication from within the cluster isn’t needed. You can discover a detailed tutorial on how to make a GitHub Package public here. If you prefer utilizing a private repository, refer to this guide to enable pulling from the private repository within the cluster.
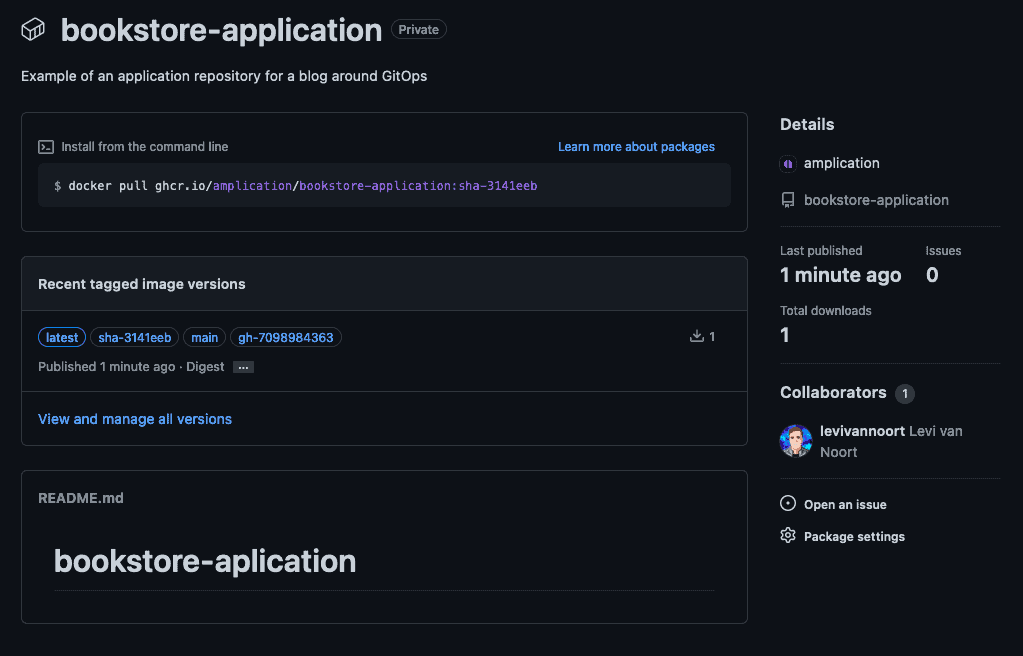
We can see that after we commit to our main branch that packages are automatically pushed to our GitHub packages image registry.
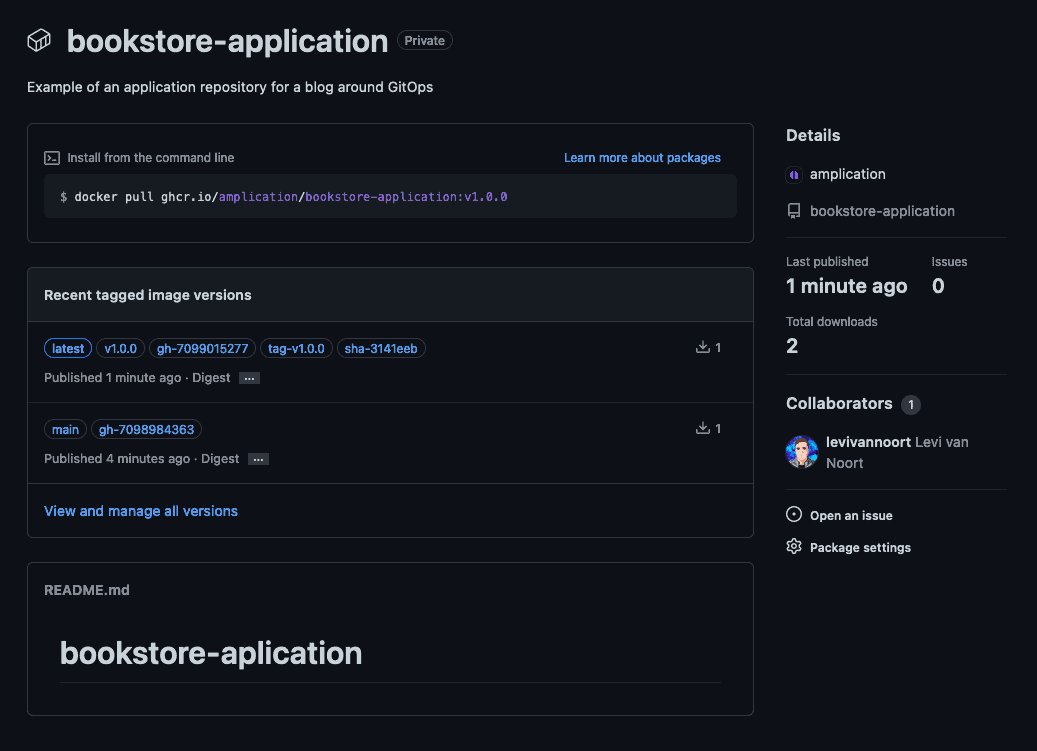
If we now release everything that is in the main branch with a semantic version of v1.0.0 we can see the newer version of the application image, where the sha-<number> is also placed on the newer image as no new commit was made between the previous push on main and the tag.
Cluster Configuration
For our application’s Kubernetes resources we’ll create a Helm chart. In the cluster configuration repository, under the charts directory run the following command:
helm create <application-name> charts/<application-name>
├── .helmignore # patterns to ignore when packaging Helm charts.
├── Chart.yaml # information about your chart
├── values.yaml # default values for your templates
├── charts/ # chart dependencies
└── templates/ # template files
└── tests/ # test filesArgo CD & Argo CD Image Updater Installation
Start by setting up a Kubernetes cluster, for this demonstration a local cluster is be used, created through minikube – other tools like kind or k3s can also be used. After installing minikube the following command can be ran to start the cluster:
minikube startThe next step would be to setup Argo CD within the cluster, this can be done by running the following commands:
kubectl create namespace argocdkubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yamlTo get access to the running Argo CD instance we can use port-forwarding to connect to the api server without having to expose the service:
kubectl port-forward svc/argocd-server -n argocd 8080:443An initial password is generated for the admin account and stored under the password field in a secret named argocd-initial-admin-secret. Use this to login with the username value admin and change the password for the user in the ‘User Info’ . Another safer option would be to use SSO.
kubectl -n argocd get secret argocd-initial-admin-secret -o jsonpath="{.data.password}" | base64 -dIn addition we also go ahead ad install Argo CD Image Updater into the cluster, this could also be done declaratively as we’ll see in the upcoming paragraphs.
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj-labs/argocd-image-updater/stable/manifests/install.yamlNow that we have access to the Argo CD user interface, we’ll look at the configuration of Argo CD Applications.
Argo CD Authentication
Before we can configure Argo CD to start managing the application’s Kubernetes resources, we need to make sure that Argo CD can access the cluster configuration repository. Repository details are stored in secret resources. Authentication can be handled in different ways, but for this demonstration we’ll use HTTPS.
syntax
apiVersion: v1
kind: Secret
metadata:
name: <repository-name>
namespace: argocd
labels:
argocd.argoproj.io/secret-type: repository
stringData:
type: git
url: https://github.com/<organization-or-username>/<repository-name>
password: <github-pat>
username: <github-username>Before we can declaratively create the secret used for authentication we need to create the GitHub Personal Access Token (PAT) used in the password field of the secret. Navigate to Settings on the profile navigation bar. Click on Developer settings > Personal access tokens > Fine-grained token & Generate new token. Set a token name, e.g., argocd-repository-cluster-configuration and set an expiration, I would suggest for a year.
Set the Resource owner to the user or organization that the cluster configuration repository is in. Set the Repository access to ‘only select repositories’ and set it to access only the cluster configuration repository. Lastly we need to give the token scoped permissions, for the integration to work we need the following: Contents - Access: Read and write & Metadata - Access: Read-only.
./secret/cluster-configuration-repository.yaml
apiVersion: v1
kind: Secret
metadata:
name: blog-cluster-configuration
namespace: argocd
labels:
argocd.argoproj.io/secret-type: repository
stringData:
type: git
url: https://github.com/amplication/bookstore-cluster-configuration
password: <github-pat>
username: levivannoortApply this secret against the cluster by using the following command:
kubectl apply -f ./secret/cluster-configuration-repository.yamlWhen looking at the Argo CD user interfaces, we can see under the settings > repositories whether the authentication against the GitHub repository has succeeded. We should now be able to start using the repository definition in our Argo CD application.

Argo CD Configuration
Now that we’re able to authenticate against GitHub to get the content from the cluster configuration repository. We can start defining our Argo CD applications and start managing the application’s Kubernetes resources. This can be done in an imperative or declarative manner. For this demonstration we’ll configure the Argo CD application declaratively. Lets look at the following manifest:
syntax
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: <application-name>
namespace: argocd
finalizers:
- resources-finalizer.argocd.argoproj.io
spec:
project: default
source:
repoURL: https://github.com/<organization-name>/<repository-name>.git
targetRevision: main
path: charts/<application-name>
destination:
server: https://kubernetes.default.svc
namespace: <application-name>
syncPolicy:
automated:
prune: true
selfHeal: true
allowEmpty: false
syncOptions:
- CreateNamespace=trueFor instrumenting Argo CD Image Updater we’ll need to add the previously mentioned annotations. We’re going for the semver update strategy with a argocd write back. As both the chosen update strategy as well as the write back method are the default we don’t need to specify these annotations.
Add the following annotations:
argocd-image-updater.argoproj.io/image-list: bookstore=ghcr.io/amplication/bookstore-applicationexample-application.yaml
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: bookstore
namespace: argocd
annotations:
argocd-image-updater.argoproj.io/write-back-method: argocd
argocd-image-updater.argoproj.io/bookstore.update-strategy: semver
argocd-image-updater.argoproj.io/image-list: bookstore=ghcr.io/amplication/bookstore-application
finalizers:
- resources-finalizer.argocd.argoproj.io
spec:
project: default
source:
repoURL: https://github.com/amplication/bookstore-cluster-configuration.git
targetRevision: main
path: charts/bookstore
destination:
server: https://kubernetes.default.svc
namespace: bookstore
syncPolicy:
automated:
prune: true
selfHeal: true
allowEmpty: false
syncOptions:
- CreateNamespace=trueApply this configuration against the cluster by using the following command:
kubectl apply -f <manifest-name>.yamlDemonstration:
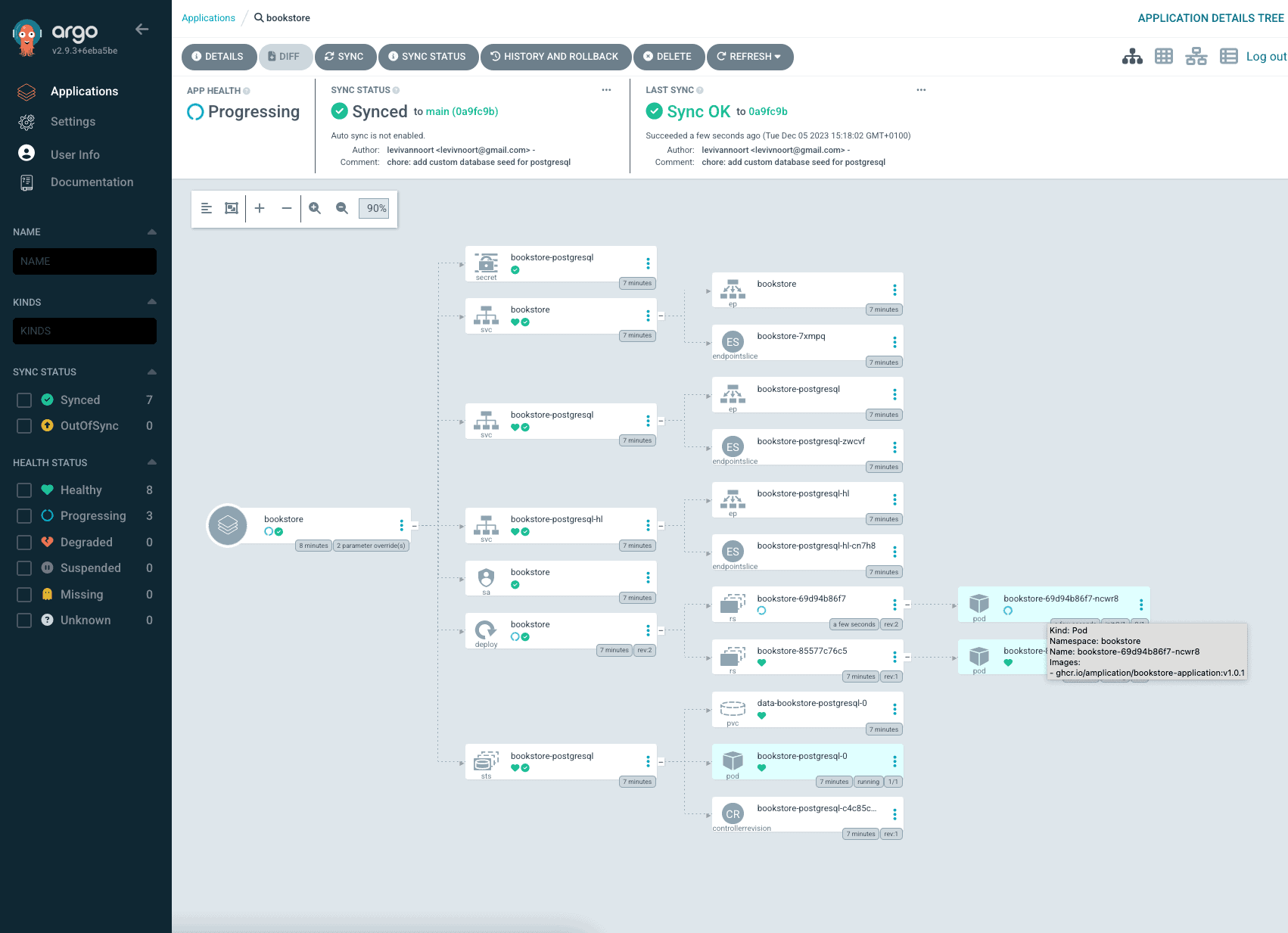
After creation of the Argo CD application we can see that the application is healthy and running within the cluster. As our application needed a database to be able to run we added a dependency to a postgresql helm chart for running a database in the cluster as well – so additional resources can be seen next to the default Helm chart Kubernetes resources.
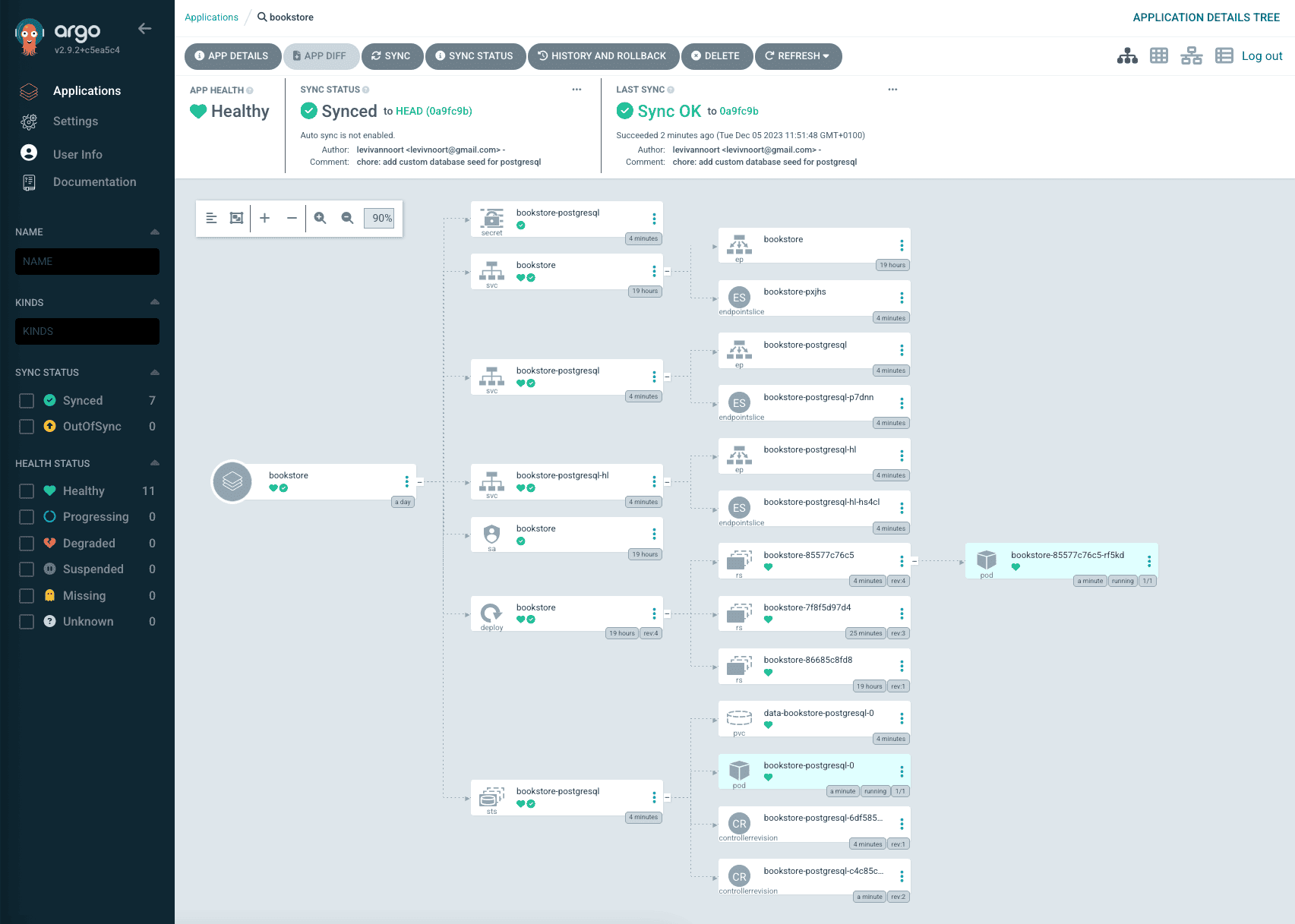
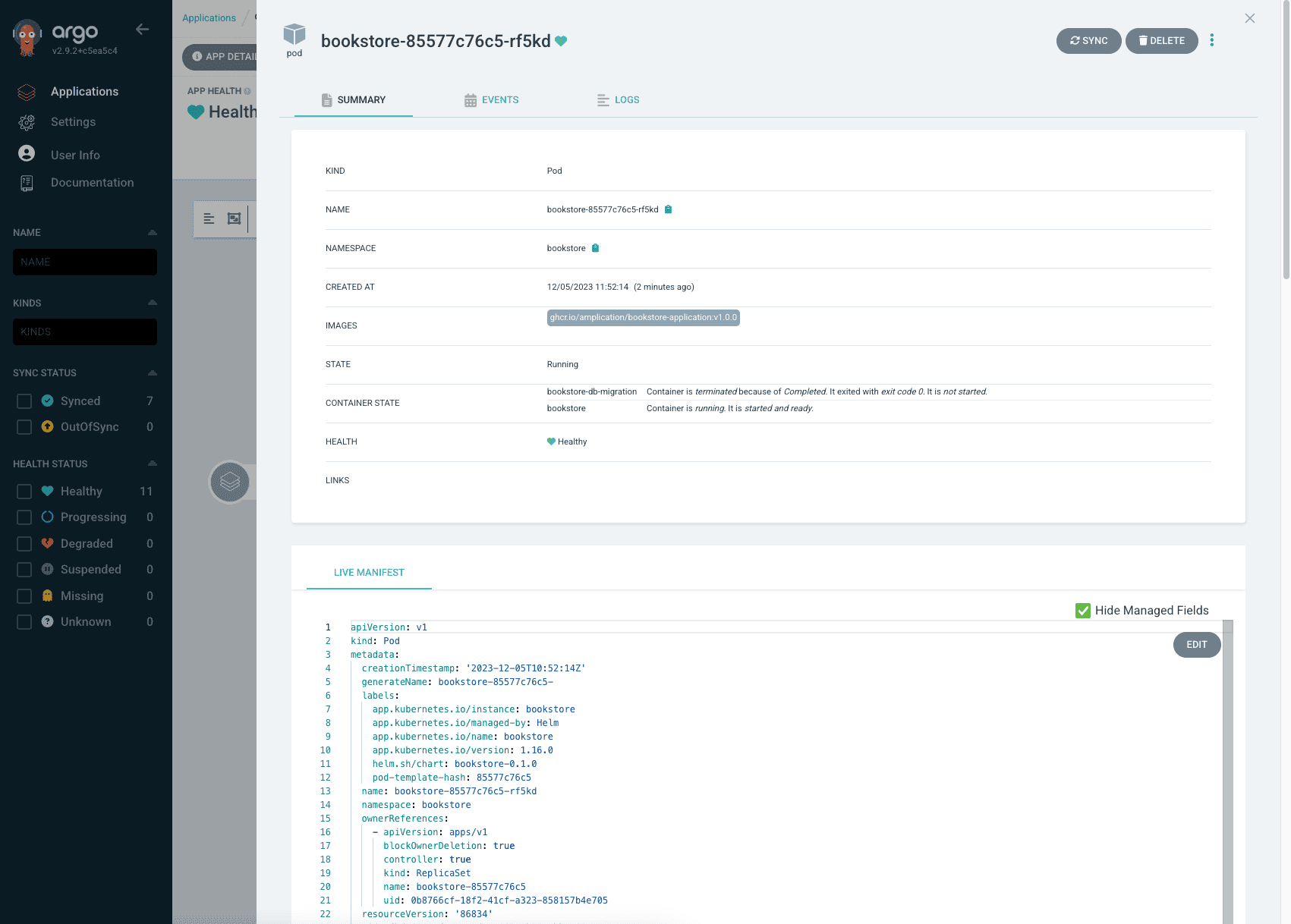
If we take an in-depth look on the deployment object we’ll see the image tag currently used by the deployment, which is the current last release within the repository – v1.0.0.
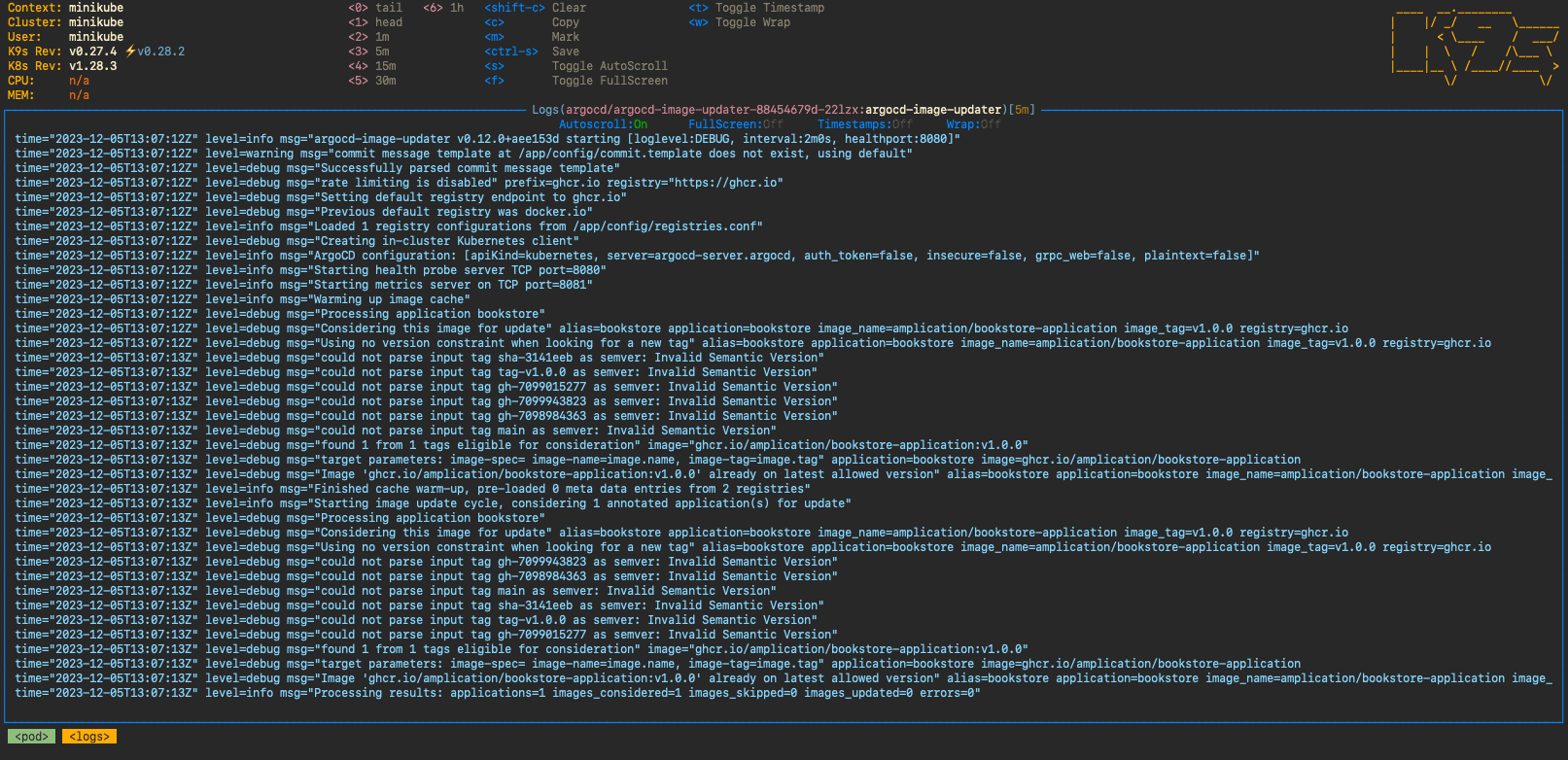
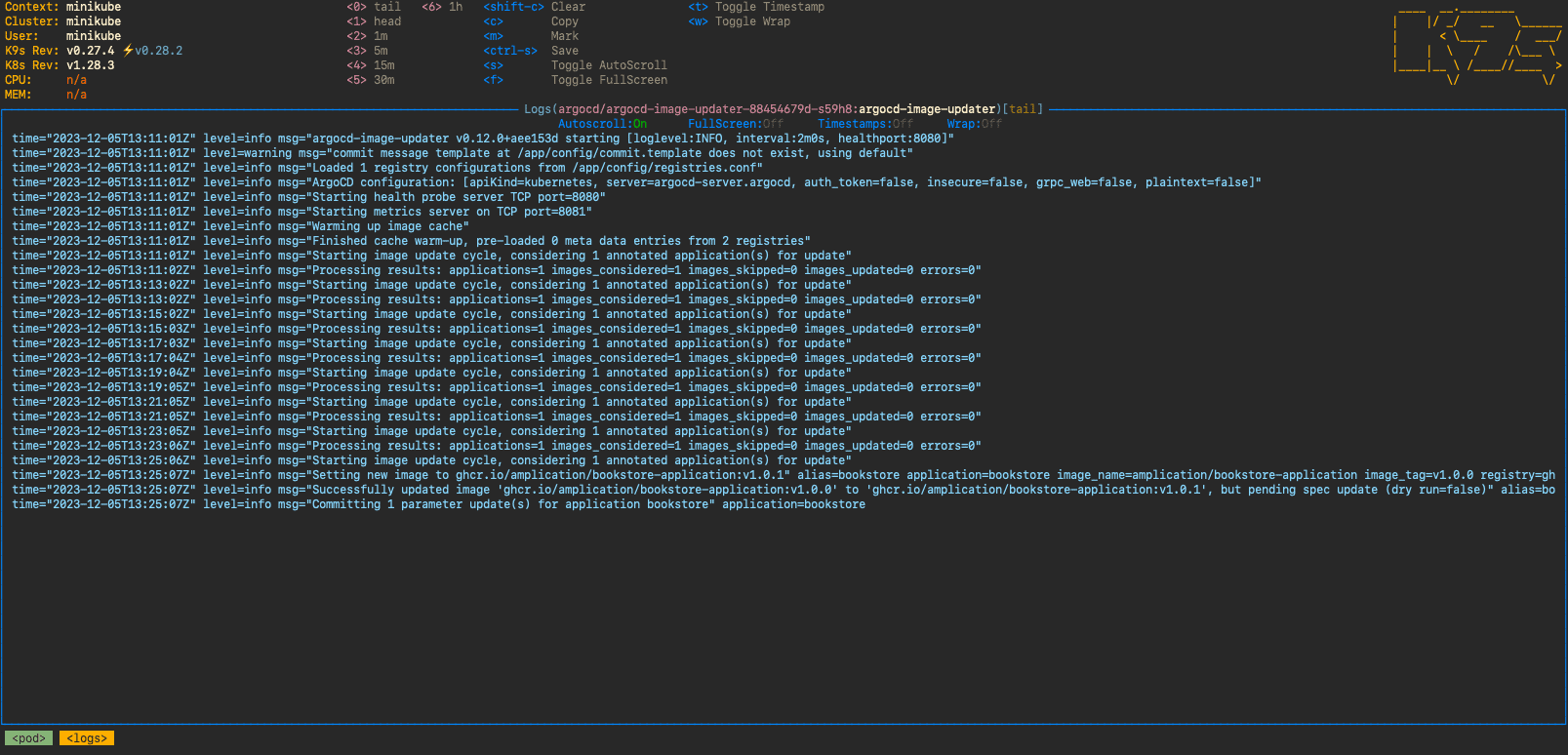
When looking at the Argo CD Image Updater logging, we can see that it has picked up the fact that we want to continuously update to the latest semantic version. By setting log.level to debug instead of the default info we get more information around which images are being considered and which do not match the constraints.
Next we update the application with some changes and release the component again with an incremented version 1.0.1:
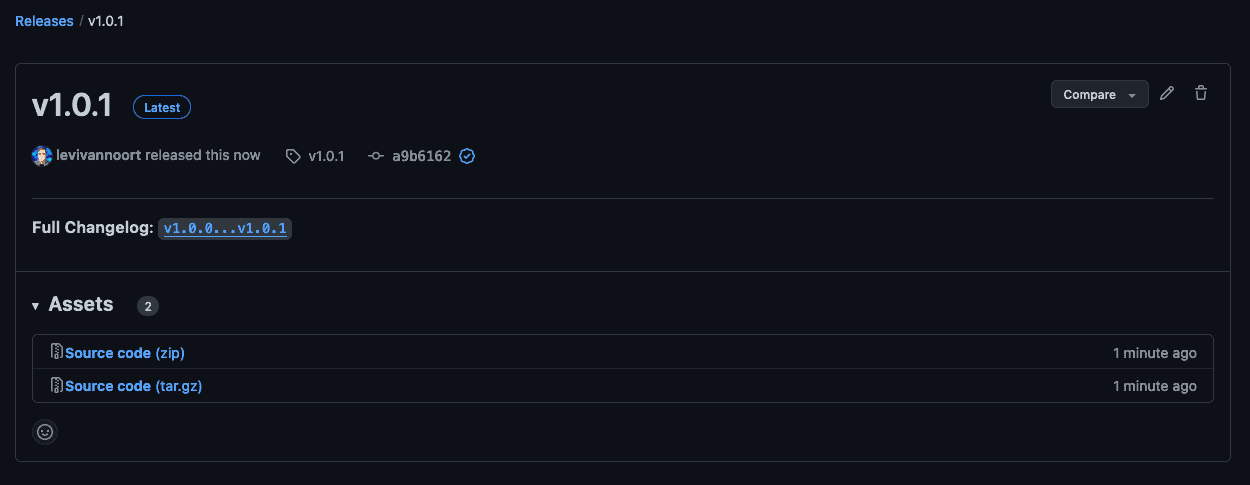
After the workflow has concluded this newer version should be present within the image registry:
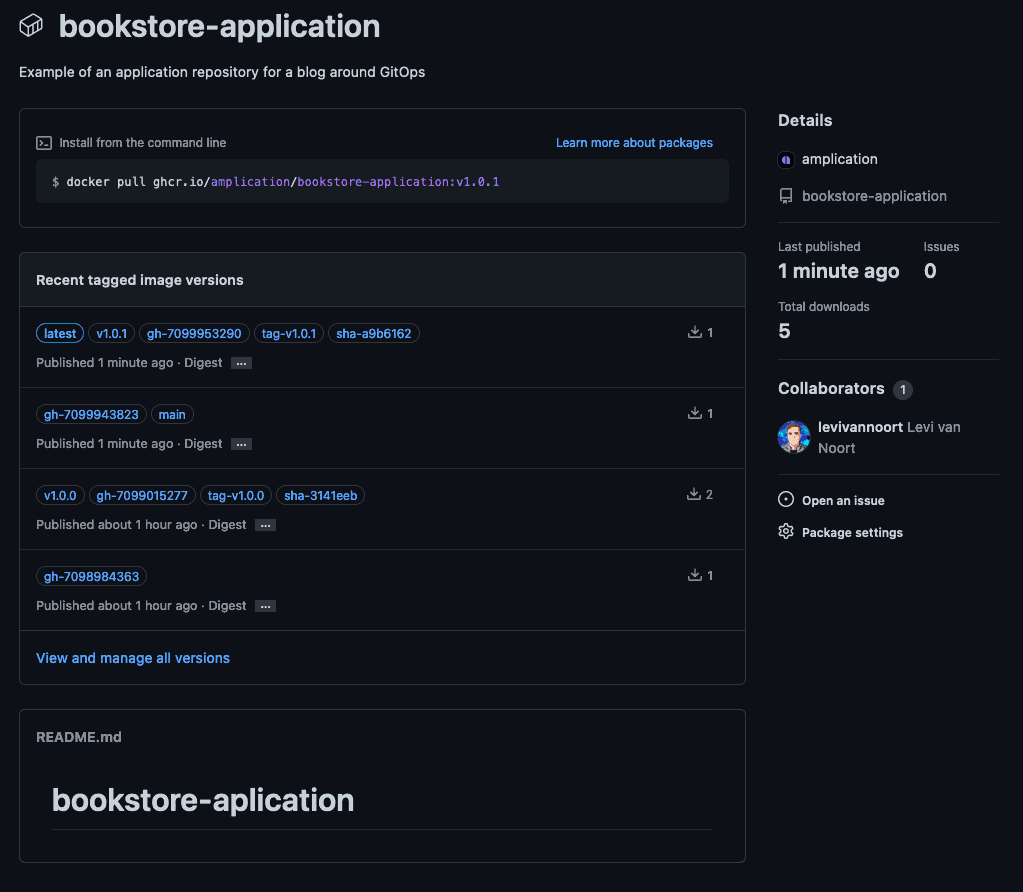
ArgoCD image updater periodically checks the image registry for newer versions per the constraints and finds the v1.0.1 image.
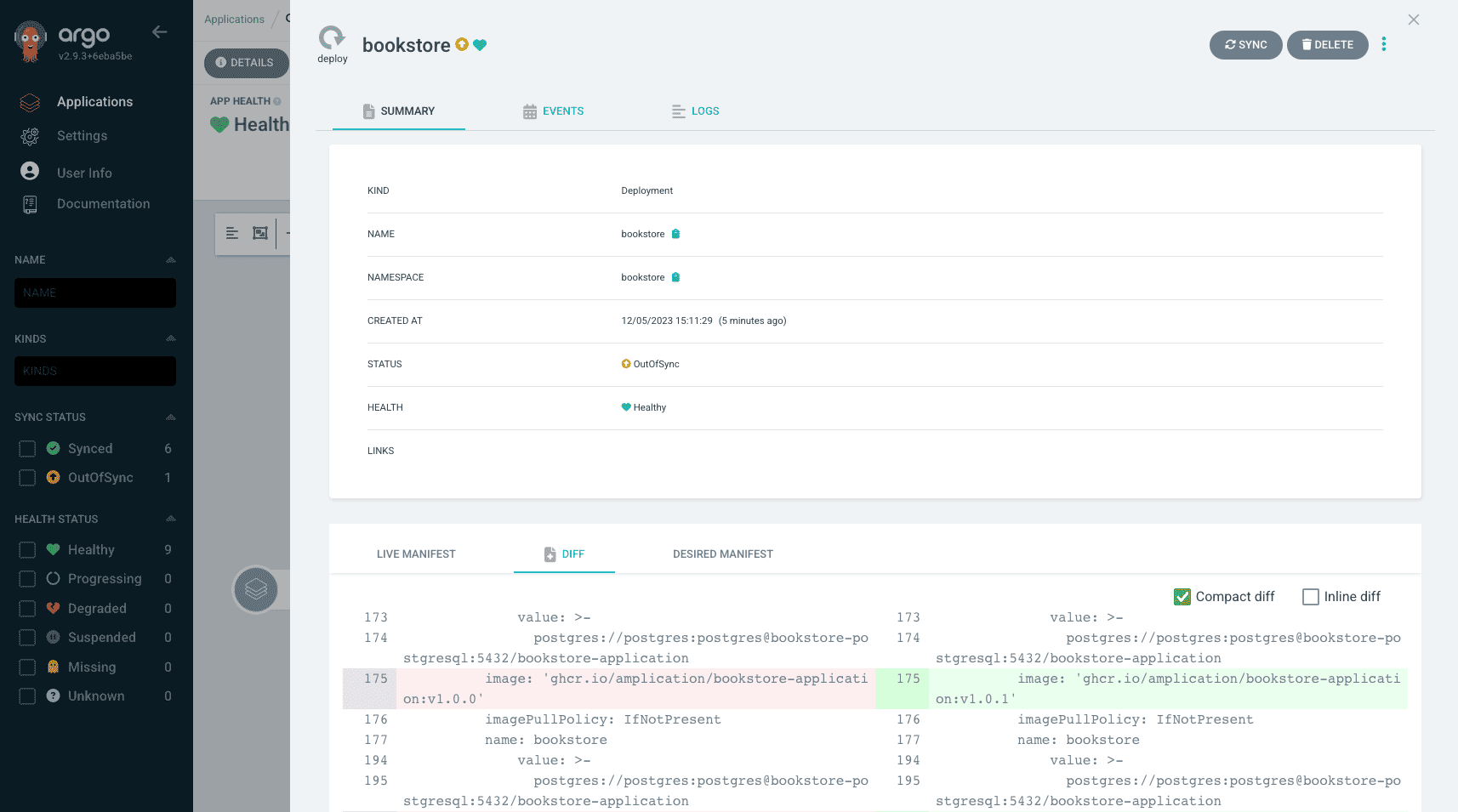
For the demonstration I decided to disable the automated synchronization policy. As you can see Argo CD Image Updater changed the image tag from v1.0.0 to v1.0.1.
Conclusion:
We managed to successfully configure the extended GitOps setup. Any changes made on the application side should be reflected by outputting a container image to the artifact registry, successfully completing the Continuous Integration side. After which in a detached manner the Continuous Deployment process is started by Argo CD Image Updater finding a newer container image in the image registry and updating the declaratively defined image tag for the application. In turn triggering Argo CD to update the application’s Kubernetes resource, serving the newer version of the application by updating the deployment with the new image tag.
A possible improvement to the setup demonstrated, would be to switch over to the git write back method, improving the setup by being more reproducible as well as having a clear audit trail.
The application used in this demonstration was generated through Amplication, which allows you to generate production-ready backend services – reliably, securely, and consistently.
[!NOTE]
As of writing the blog the Argo CD Image Updater project does not honor the Argo CD’s rollback feature and thus automatically updates the application back to the latest version found in the image registry. A solution to this would be to temporary disable the indexing of Argo CD Image Updater for the application and set theimage.tagin the Helm chart to the desired version.