
Member post originally published on the Bytedance blog by Gary Liu
Project link: https://github.com/kubewharf/kubeadmiral
Since its release in 2014, Kubernetes has become the de facto standard for cloud native orchestration and scheduling systems, delivering substantial value to infrastructure developers around the world. As an increasing number of corporations embrace cloud native technologies and migrate their workloads to Kubernetes, the scale of their clusters grows rapidly. The community edition of Kubernetes, capped at 5000 nodes per cluster, is no longer able to keep up with the scale requirements of large-scale enterprise applications. Moreover, many companies are adopting multi-cloud architectures to achieve cost reduction, increased resource and operational efficiency, geographical disaster recovery, and environment isolation. As a result, the demand for multi-cluster orchestration and scheduling tools is on the rise.
Brief History of Kubernetes at ByteDance
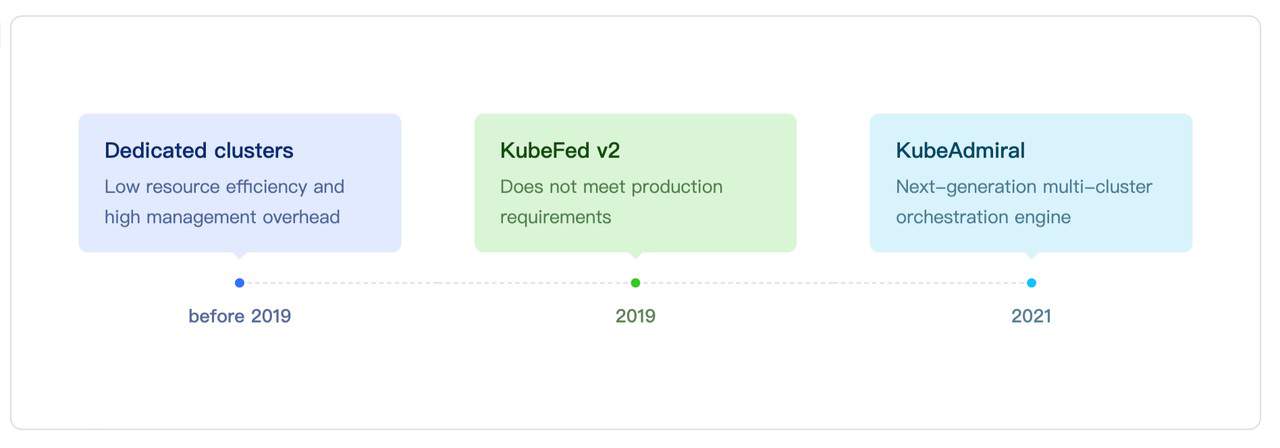
Dedicated Clusters
In the early years of ByteDance’s cloud native adoption, each business line operated in separate dedicated clusters due to isolation concerns. However, this led to low resource elasticity and efficiency, observed in several ways:
- Each business line had to maintain independent resource buffers for scaling and upgrading.
- Applications were tightly coupled to specific clusters, and manual resource transfer was required to balance resource utilization as applications scale.
- SRE teams had to deeply understand both the businesses and the clusters in order to manage resources efficiently.
Consequently, this resulted in inefficient resource management and suboptimal overall deployment rate.
KubeFed v2
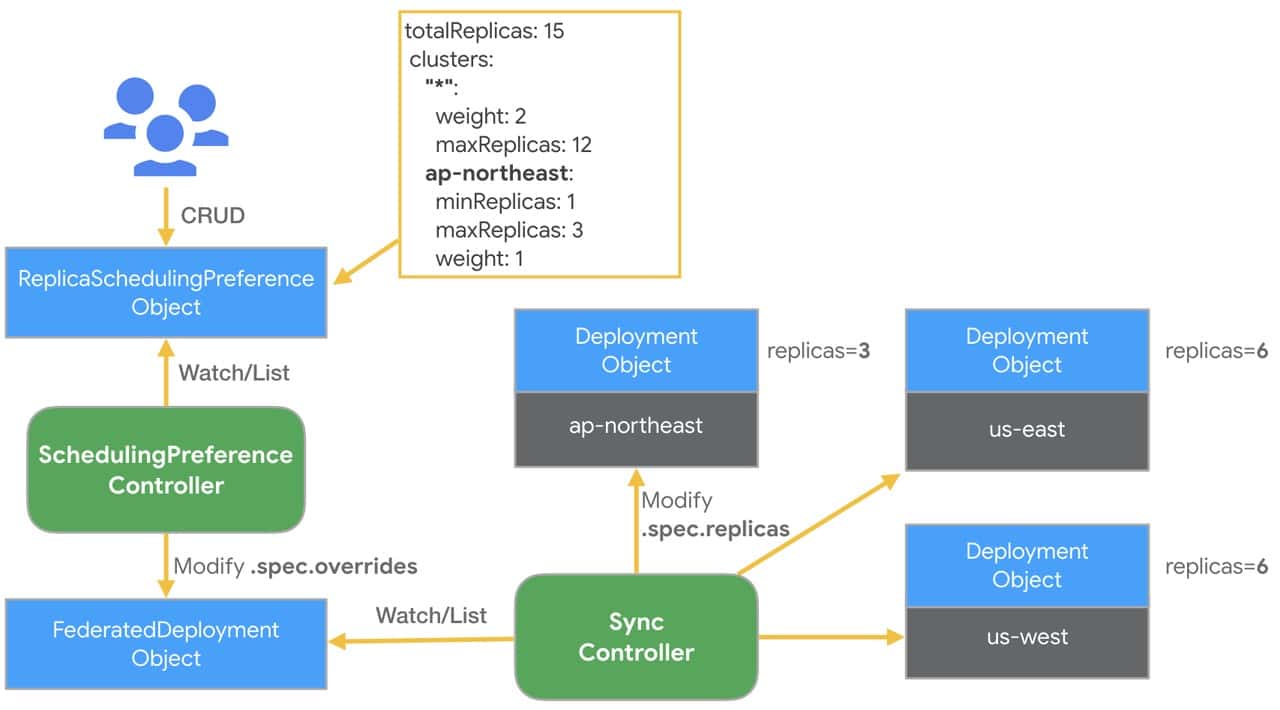
To address these challenges, the technical infrastructure team at ByteDance started exploring cluster federation based on KubeFed v2 in 2019. The goal is to pool resources across business lines, reduce unnecessary buffers, and improve the efficiency of resource management. KubeFed v2 introduces the concept of host and member clusters. Users create federated workloads (e.g. FederatedDeployment) in the host cluster, and KubeFed schedules and dispatches workloads in the member clusters based on these federated workloads. Each federated workload contains three primary fields: Template (specifying the workload to be dispatched to member clusters), Placement (designating target member clusters), and Overrides (indicating how the template should be varied in some clusters). For example, the following FederatedDeployments instructs KubeFed to create a Deployment in cluster1 and cluster2 with 2 and 3 replicas respectively.
apiVersion: types.kubefed.k8s.io/v1beta1
kind: FederatedDeployment
metadata:
name: test-deployment
spec:
template:
metadata:
labels:
app: nginx
spec:
replicas: 5
# more Deployment fields...
placement:
clusters:
- name: cluster1
- name: cluster2
overrides:
- clusterName: cluster1
clusterOverrides:
- path: /spec/replicas
value: 2
- clusterName: cluster2
clusterOverrides:
- path: /spec/replicas
value: 3For Deployment and ReplicaSet, KubeFed supports dividing the desired replicas across multiple clusters based on ReplicaSchedulingPreference (RSP). Users can configure the weights, minimum replicas, and maximum replicas for each cluster, and the RSP controller computes a valid replica distribution and updates the Placement and Overrides fields of FederatedDeployment or FederatedReplicaSet.
KubeFed laid the foundation of Kubernetes cluster federation at ByteDance. However, we soon found KubeFed unable to meet our production requirements. The primary pain points were:
- Uneven resource utilization across clusters – KubeFed’s RSP only supports static cluster weights and lacks the ability to adapt to fluctuations in cluster resources dynamically.
- Service disruption after rescheduling – During rescheduling, replicas might be abruptly migrated between clusters, disrupting service availability.
- Limitations in scheduling semantics – KubeFed supports stateless, replica-based resources through RSP, but lacks support for more diverse resources such as stateful workloads and jobs. Moreover, extending the existing scheduling semantics is difficult.
- High onboarding cost – KubeFed requires the creation of federated objects and is incompatible with the native Kubernetes API. Users and downstream platforms need to completely overhaul their usage patterns.
KubeAdmiral
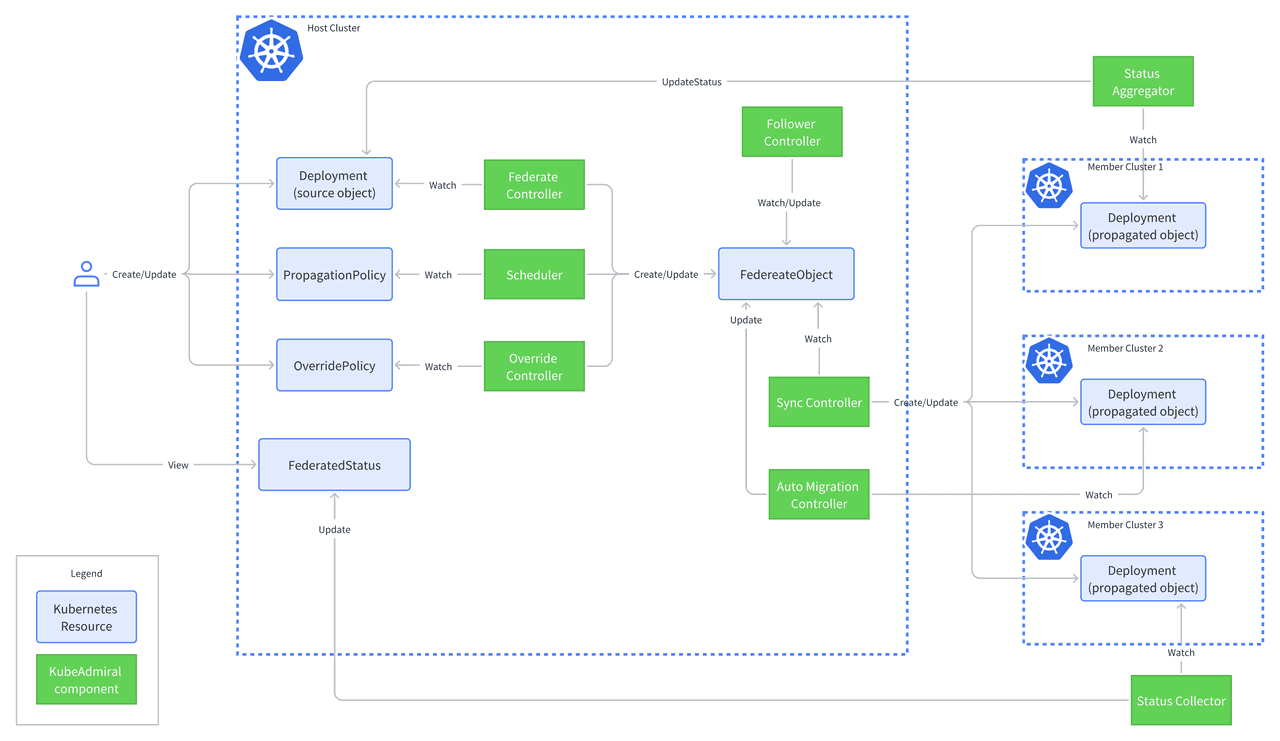
With the evolution of cloud native infrastructure at ByteDance, we raised our standards for efficiency, scalability, performance, and cost. Meanwhile, the size and number of our Kubernetes clusters continue to grow phenomenally along with the businesses. Additionally, workloads beyond stateless microservices, including stateful services, storage, offline and machine learning jobs, started embracing cloud native technologies. Against this backdrop, the limitations of KubeFed became increasingly difficult to manage. Therefore, at the end of 2021, we began our endeavor to develop the next generation cluster federation system, building upon KubeFed v2’s foundation. We named it KubeAdmiral to capture our aspiration for it to manage multiple clusters as effectively as a seasoned navy admiral commands a fleet.
KubeAdmiral offers enhanced multi-cluster orchestration and scheduling capabilities for various mainstream business scenarios. Today at ByteDance, KubeAdmiral manages more than 100,000 microservices with more than 10,000,000 pods running on dozens of federated Kubernetes clusters. It supports upwards of 30,000 upgrade and scaling operations daily, and maintains a stable deployment rate of 95-98% without the need for manual intervention.
KubeAdmiral Feature Highlight
KubeAdmiral not only supports native Kubernetes resources and third-party custom resources, but also offers a rich and extensible scheduling framework. Moreover, it refines numerous aspects of scheduling and dispatching, backed by years of practical production experience.
- Rich Multi-Cluster Scheduling Capabilities
The scheduler is a core component of KubeAdmiral responsible for computing the desired placement of workloads in member clusters. When scheduling replica-based workloads, it also computes the appropriate replicas for each cluster. Functioning as KubeAdmiral’s “brain”, its decisions directly impact critical aspects such as fault tolerance, resource efficiency, and stability.
KubeFed provides the RSP scheduler for replica-based workloads, but its customizability and extensibility are very limited, and modifying its behavior requires code modification. Additionally, it lacks support for stateful services, job-like resources, etc., which require different sets of scheduling semantics.
KubeAdmiral introduces more comprehensive scheduling semantics. It supports more flexible and fine-grained mechanisms to select clusters via labels, taints, etc, and score clusters based on resource utilization, affinity, and so on. Beyond just replica-based workloads, it also supports scheduling stateful workloads and job-like resources. Additionally, it brings about convenient features such as automatic dependency scheduling (dependencies such as ConfigMaps can automatically follow their Deployment to corresponding member clusters). The scheduling behavior can be configured using a PropagationPolicy object, as shown below:
apiVersion: core.kubeadmiral.io/v1alpha1
kind: PropagationPolicy
metadata:
name: mypolicy
namespace: default
spec:
# Many different ways to select clusters.
placement:
# Manually specify desired clusters and replica weights, if required.
- cluster: cluster-01
preferences:
weight: 4
- cluster: cluster-02
preferences:
weight: 3
- cluster: cluster-03
preferences:
weight: 4
# Filter clusters based on label selectors.
clusterSelector:
IPv6: "true"
# Filter clusters based on affinity.
clusterAffinity:
- matchExpressions:
- key: region
operator: In
values:
- us-east
# Filter clusters based on taints and tolerations.
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
# Mode of scheduling - divide or duplicate.
schedulingMode: Divide
reschedulePolicy:
# Only schedule on creation and do not reschedule afterwards.
# Suitable for stateful workloads.
disableRescheduling: false
# When rescheduling should be triggered.
# More triggers: reschedule more frequently - favor agility.
# Fewer triggers: reschedule less frequently - favor stability.
rescheduleWhen:
policyContentChanged: true
clusterLabelsChanged: false
# Whether to rebalance replicas on reschedule.
# Enabling rebalance results in optimal placement, but at the potential cost
# of disrupting existing replicas.
replicaRescheduling:
avoidDisruption: true
# Limit propagation to a single cluster.
# Suitable for job-like workloads.
maxClusters: 1Instead of writing Overrides manually, KubeAdmiral supports generating Overrides based on OverridePolicy:
apiVersion: core.kubeadmiral.io/v1alpha1
kind: OverridePolicy
metadata:
name: example
namespace: default
spec:
# Flexible ways to select target clusters.
overrideRules:
- targetClusters:
# Select clusters by name.
clusters:
- on-prem-1
- edge-1
# Select clusters by label.
clusterSelector:
region: us-east
az: az1
# Select clusters by affinity.
clusterAffinity:
- matchExpressions:
- key: region
operator: In
values:
- us-east
# Change the container image in the target clusters using jsonpatch.
overriders:
jsonpatch:
- path: "/spec/template/spec/containers/0/image"
operator: replace
value: "nginx:test"- Scheduler Extension
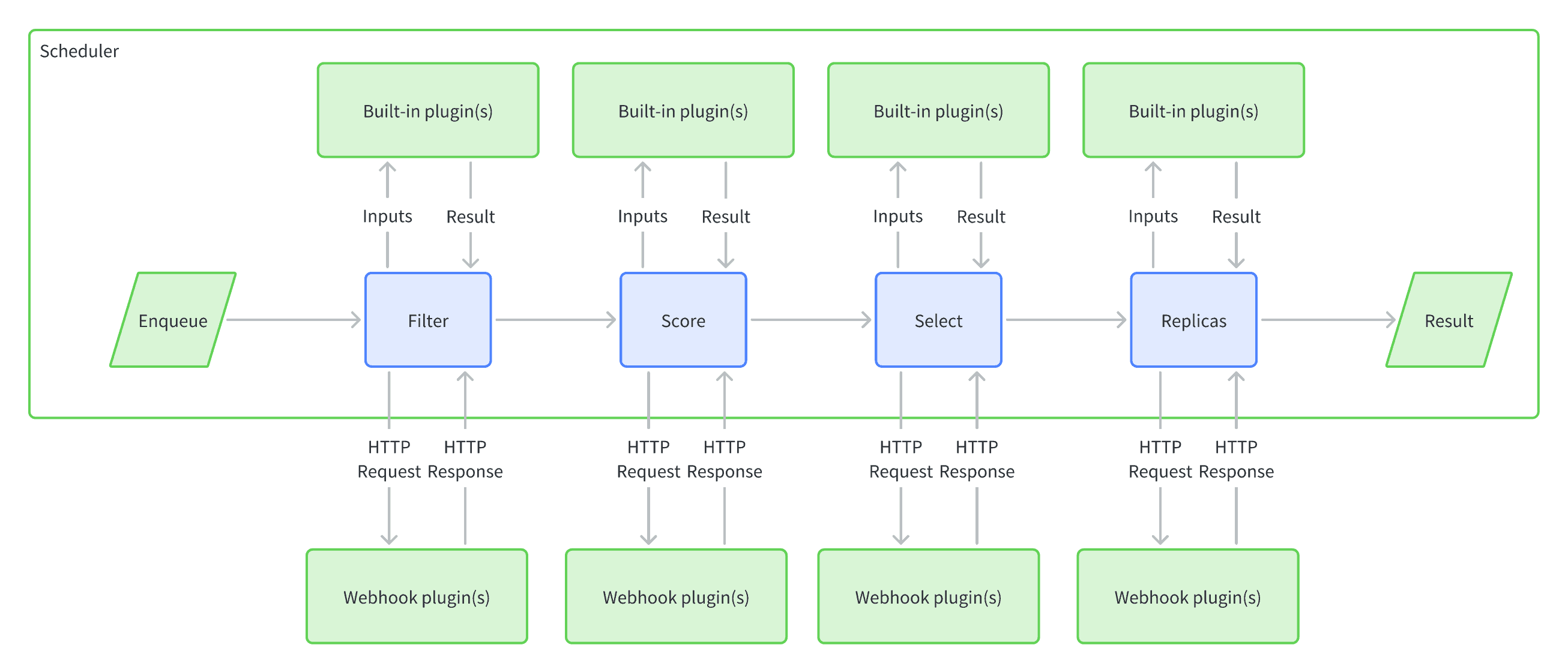
Taking inspiration from kube-scheduler’s design, KubeAdmiral offers a flexible scheduling framework. It simplifies the scheduling process by dividing it into four distinct stages: Filter, Score, Select, and Replica. Each stage is handled by individual plugins, creating a logical separation that promotes modularity. For instance, in the provided PropagationPolicy example above, most behaviors are implemented through built-in scheduling plugins. The beauty of this approach is that plugins can be easily added or removed, without any impact on the remaining plugins. This greatly simplifies the scheduler logic and reduces its overall complexity. Although the built-in plugins in KubeAdmiral offer versatile features that cater to common use cases, users have the flexibility to enhance the functionality by creating their own custom scheduling plugins for specific niche scenarios. This empowers users to seamlessly integrate with internal or existing systems. The KubeAdmiral scheduler interacts with external plugins via the HTTP protocol, enabling users to extend the scheduling logic with minimal effort and without having to modify the KubeAdmiral control plane. The plugin only needs to output the desired placement, and KubeAdmiral takes care of binding and enforcing those results.
- Automatic Migration of Unschedulable Workloads
For replica scheduling, KubeAdmiral calculates the number of replicas that each member cluster should receive and overrides the replicas field in the template before distributing the resources to the member clusters. After the resources are distributed to member clusters, the kube-scheduler in each member cluster assigns the corresponding pods to available nodes. Thus, a full scheduling chain is completed.
Occasionally, there are cases where the kube-scheduler fails to find suitable nodes for pods due to reasons including node outages, resource shortages, and unmet node affinity requirements. If left unaddressed, the unschedulable pods will remain pending. KubeAdmiral resolves this by automatically migrating the unschedulable pods to other clusters, enabling better resource utilization overall.
As an illustration, consider three clusters A, B, and C with an equal weight distribution for six replicas. After the initial scheduling by KubeAdmiral, each cluster receives two replicas. If the two replicas in cluster C fail to be scheduled by kube-scheduler after a while, KubeAdmiral automatically shifts them to clusters A and B, ensuring the desired availability of 6 replicas across all clusters.
| Cluster | A | B | C |
| Weight | 1 | 1 | 1 |
| Initial replica distribution | 2 | 2 | 2 |
| Number of unschedulable replicas | 0 | 0 | 2 |
| Rebalanced replica distribution | 3 | 3 | 0 |
- Dynamic Replica Distribution Based on Real-Time Resource Availability
In a multi-cluster setup, the resource utilization of each cluster fluctuates as machines go online or offline. Relying solely on the static weight replica scheduling provided by KubeFed RSP can easily lead to skewed resource utilization. Clusters with a high deployment rate are prone to pod pending during upgrade, while clusters with a low deployment rate have idle resources that are wasted.
As a solution to this, KubeAdmiral introduces dynamic weight scheduling based on real-time cluster resource utilization. It calculates the amount of available resources by collecting the total and allocated resources of each cluster, and uses it as the weight for replica scheduling. This ultimately achieves dynamic load balancing across all member clusters. In practice, we are able to maintain a stable deployment rate of 95-98% or above in all member clusters with this approach.
- Refined Replicas Rescheduling
KubeFed’s replica rescheduling algorithm usually results in less than ideal distributions for scaling operations. As an illustration, consider 30 replicas currently distributed to 3 member clusters A, B, and C with equal weights. If the workload is scaled down to 9 replicas, KubeFed has 2 possible behaviors depending whether the user enables rebalance:
- If
rebalance = false, KubeFed retains existing replicas, disregarding cluster weights. - If
rebalance = true, KubeFed disregards current distribution and rebalances replicas based on weights.
As seen above, KubeFed is unable to devise a distribution that satisfies fault tolerance and load balancing requirements without compromising service availability. To address this, KubeAdmiral developed a refined replica rescheduling algorithm that guarantees service availability and produces distributions that are as close to the optimal distribution as possible. The gist of the algorithm is to distribute the increment or decrement in replicas, instead of the total replicas.
Using the same scenario of scaling down from 30 replicas to 9 replicas above, the refined algorithm roughly proceeds as follows:
- Current distribution = [15, 15, 0]; total current replicas: 30
- Desired distribution = [3, 3, 3]; total desired replicas: 9
- Distance = desired – current = [-12, -12, 3]; total distance: -21
- For scaling down, remove any positive distance terms; distance = [-12, -12, 0]
- Distribute the total distance -21 using the distance vector [-12, -12, 0] as weights; adjustments = [-10, -11, 0]
- Final distribution = current + adjustments = [15, 15, 0] + [-10, -11, 0] = [5, 4, 0]
| Cluster | A | B | C |
| Weight | 10 | 10 | 10 |
| Replicas before scaling down | 15 | 15 | 0 |
| Change | -10 | -11 | 0 |
| Replicas after scaling down | 5 | 4 | 0 |
- Support for Native Kubernetes Resource API
Unlike KubeFed, which requires users to use an incompatible “federated” API, KubeAdmiral caters to the usage habits of single-cluster Kubernetes users by providing support for native Kubernetes APIs. After the user creates a native resource (such as Deployment), KubeAdmiral’s federate-controller automatically converts it into an internal object for use by downstream KubeAdmiral controllers. This enables users to quickly transition from a single-cluster to a multi-cluster architecture with low onboarding cost.
However, KubeAdmiral doesn’t stop there. In a single cluster, Kubernetes controllers update the status of resources to reflect their current state. For example, a Deployment‘s status reflects its rollout progress and number of replicas it currently has. Users or upper-layer systems often rely on such status. In a multi-cluster environment, the status is populated on individual Deployments propagated to member clusters. Users must check the status of resources in each cluster individually, leading to a fragmented perspective and reduced operational efficiency.
To solve this problem and seamlessly support native resources, KubeAdmiral introduces status aggregation. The KubeAdmiral status-aggregator collects and aggregates the status of individual resources from member clusters and writes it back to the native resources. This allows users to observe the global resource status at a glance.
Final Thoughts
KubeAdmiral has been incubating within ByteDance for a while, and has been an integral part of ByteDance’s internal PaaS platform TCE. Battle-tested by large-scale applications, it has accumulated many valuable practical experiences. To give back to the community, KubeAdmiral has officially been open-sourced on GitHub.
Looking forward, we plan to continue working on KubeAdmiral, especially in the following areas:
- Continue to improve the orchestration and scheduling capabilities of stateful and job-like workloads, and develop advanced capabilities such as automatic migration and cost-based scheduling to embrace the new era of multi-cloud batch computing.
- Improve user experience and further reduce users’ cognitive burden, striving for a pleasant out-of-the-box experience.
- Improve observability, optimize logging and metrics, and enhance the scheduler’s explainability.
- Explore features such as one-click migration from single cluster, further smoothening the onboarding experience.
Multi-cluster orchestration and scheduling is not a simple topic. We hope our experience and solution could be useful to the community. We look forward to more friends joining the KubeAdmiral community, and welcome everyone to try KubeAdmiral and give us suggestions!