Guest post originally published on Netris’ blog by Alex Saroyan, CEO/co-founder at Netris
This is a continuation of Article 1. If you want to learn why we spend so much time thinking about High Availability, go there. Otherwise, if you want to see under the hood of HOW we do it, well, here you go.
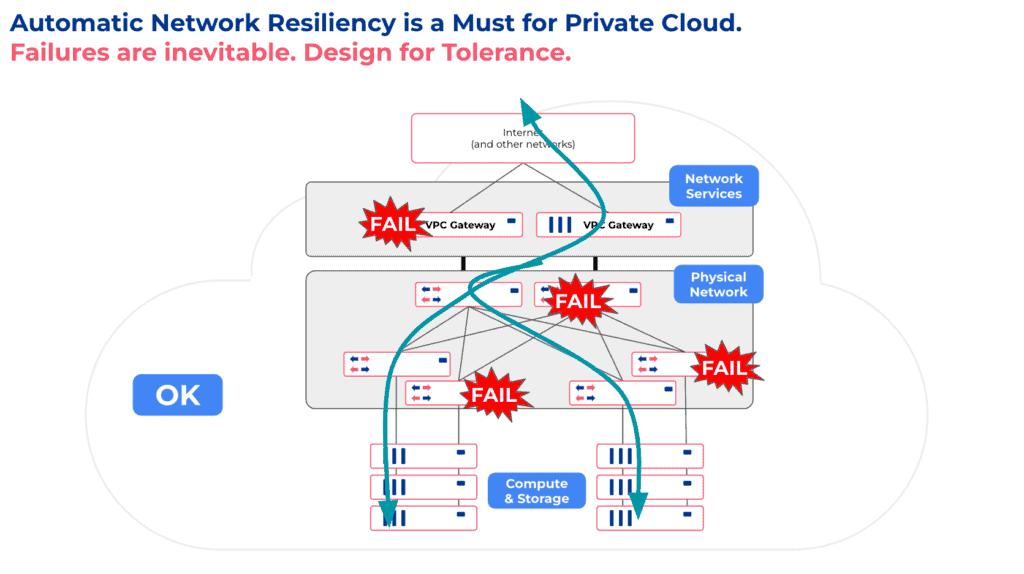
I like to think about private cloud network architecture in a single region through 3 layers:
- Network Services layer (or VPC Networking): Provides Routing, Elastic Load Balancing, Firewalling, NAT, DHCP, and VPN services.
- Physical Network layer: Provides physical connectivity between servers. It can be network switches in a colocation facility or API-driven Layer-2 service provided by a bare-metal-as-a-service provider.
- Compute & Storage layer: Physical servers, storage, virtual machines, and containers – everything with an IP address.
How do we achieve high availability going top-down, layer by layer?
High Availability of VPC Gateway – the Network Services layer.
Routing, Elastic Load Balancing, Firewalling, NAT, DHCP, and VPN are the minimum network services required by private cloud. In traditional networks, these services are provided by using two (or more) nodes of specialized network equipment for each service. A couple of routers (like Cisco ASRs or Juniper MXes), a couple of firewalls, a couple of load balancers, etc.
Most of our customers use our Netris SoftGate technology which turns generic Linux servers into highly optimized VPC gateways for the private cloud. In this case, the entire suite of network services is served via two generic servers instead of 8+ units of expensive and complicated network devices.
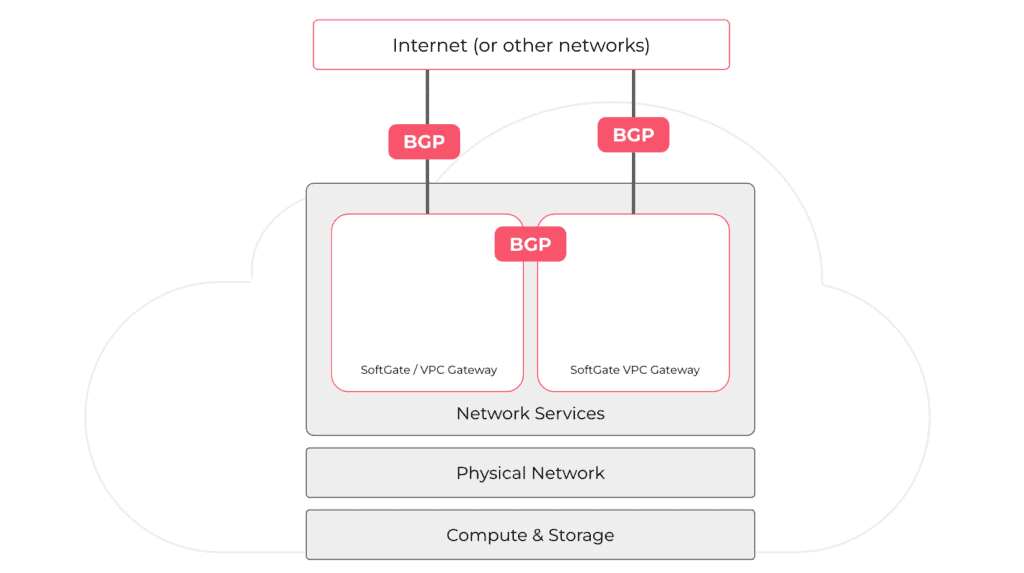
The private cloud needs network connectivity with an upstream network. Some users connect their private cloud to an existing traditional network statically or dynamically. Most customers use BGP to peer directly with Tier 1/2/3 Internet upstream providers and IXPs (Internet exchange points).
To auto-configure BGP upstream connectivity, Netris needs to get the minimal information, link IP information (usually /30 provided by the upstream provider), and how to reach that upstream provider physically (which port is the cable plugged). Based on that minimal user input or in some environments based on metadata, we automatically configure BGP peering with upstreams from each VPC gateway. We enable BFD, so if the remote end supports it, it improves failover. We start advertising the public IP prefix equally and expect upstream to distribute inbound traffic equally across all VPC gateways.
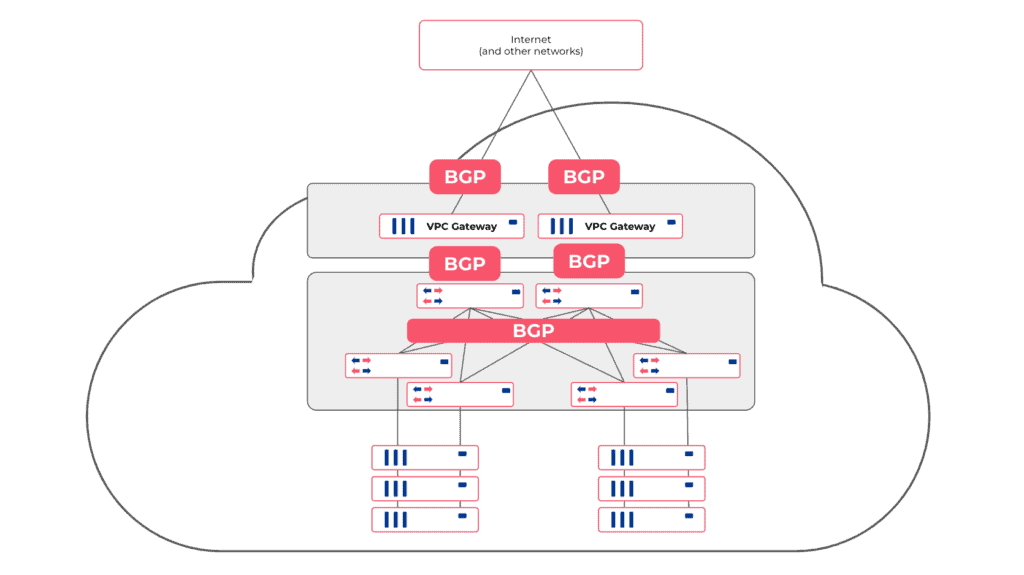
Netris software also configures a mesh of BGP adjacencies between VPC gateways and towards the switch fabric (if the switch fabric is managed with Netris and supports EVPN/VXLAN). So once incoming traffic hits any of the VPC gateways, the gateway can figure out whether to forward that packet toward compute & storage hosts, to one of neighboring VPC gateways, or to service that particular traffic locally (NAT or Load Balancer).
Network Services without IP connection tracking
Network Access Control Lists, Destination NAT, L4 Load Balancing – these services can work without IP connection tracking. So the user requests such services in the Netris web console or API then Netris automatically configures services on every VPC Gateway. No matter which VPC Gateway network packets enter, each gateway node can service that traffic, i.e., load-balance, DNAT, or drop/permit. And so, in the case of VPC gateway failure, traffic re-distributes and continues flowing.
It’s trickier with services that need connection tracking
Source NAT service has to track IP connections (to map local ip:port with global ip:port). One way of organizing high availability would be to synchronize IP connection tracking info between VPC gateways – We don’t like that because if data is corrupt on one node, then conntrack synchronization may copy that garbage and corrupt the other node too.
Instead, we elect one of the available VPC Gateways as an active node for Source NAT service. The VPC Gateway that is elected as active is using BGP to signal other VPC Gateways (hey, I am servicing this SNAT service that has XYZ global IP address), so if ingress traffic destined to the public global IP address of that SNAT service enters any other VPC gateway, it knows where to forward that packet. If VPC Gateway, which is an active master for SNAT service, fails, then another VPC Gateway will be elected as an active master for the SNAT role.
Traditional VRRP is too old school, but we have an unconventional use case for it.
VRRP was created to allow a group of routers to work together to present the appearance of a single virtual default gateway to the hosts on a LAN. If one router fails or becomes unavailable, another router takes over the function of the default gateway. We are NOT using VRRP for default gateway redundancy because VRRP is wasting a dummy IP address on each node and is not designed well for Active/Active and horizontal scalability.
We use Keepalived, an open-source implementation of VRRP, but we do not use the VRRP itself. We use only the health check and election functions of Keepalived. We use it for monitoring the liveness of VPC Gateway nodes. See, we view VPC Gateways as ephemeral nodes, and for some strictly stateful network services (like SNAT) we need a way to elect primary, secondary, tertiary, etc.. We need a way that every node can deterministically learn, monitor, and react accordingly if a particular node becomes the active master.
In traditional VRRP, you should run VRRP instances on every interface looking down towards the servers. We don’t do that because we don’t need the virtual IP function of VRRP. We only need it’s health check and election mechanism. So we run Keelapived on the interface shared between VPC Gateways, where we also run iBGP.
This way, Netris achieves active/active redundancy for most services if possible and active/standby redundancy otherwise.
Where is the default gateway located, and how is its HA organized?
When Netris operates both the VPC Gateways and the switch fabric, Netris configures the default gateway on every physical switch, leveraging anycast default gateway technique available through EVPN and VXLAN. In this case, each switch is also a default gateway. When the switch receives traffic from a server that needs to travel outside the private cloud, the switch will look up the EVPN/BGP routing table to find out the default route, the VPC Gateways. In case of a VPC Gateway failure, the BGP routing table will converge accordingly, and other VPC Gateways will continue serving the traffic.
Traffic in the opposite direction that has entered the private cloud from the outside through VPC Gateway will use the EVPN/VXLAN BGP routing table to look up behind which switches the particular destination host is located to route the traffic to. In case of a switch failure, the BGP routing table will change, and every server will be routable through another switch.
In setups where Netris do not drive switch-fabric, for example, in bare-metal-as-a-service providers like Equinix Metal and PhoenixNAP, Netris automatically recognizes the environment and acts differently. We use bare-metal-as-a-service providers’ API to request Layer-2 plumbing between customers’ bare-metal servers and VPC Gateways. In this case, Netris configures the default gateway IP address directly on VPC Gateways.
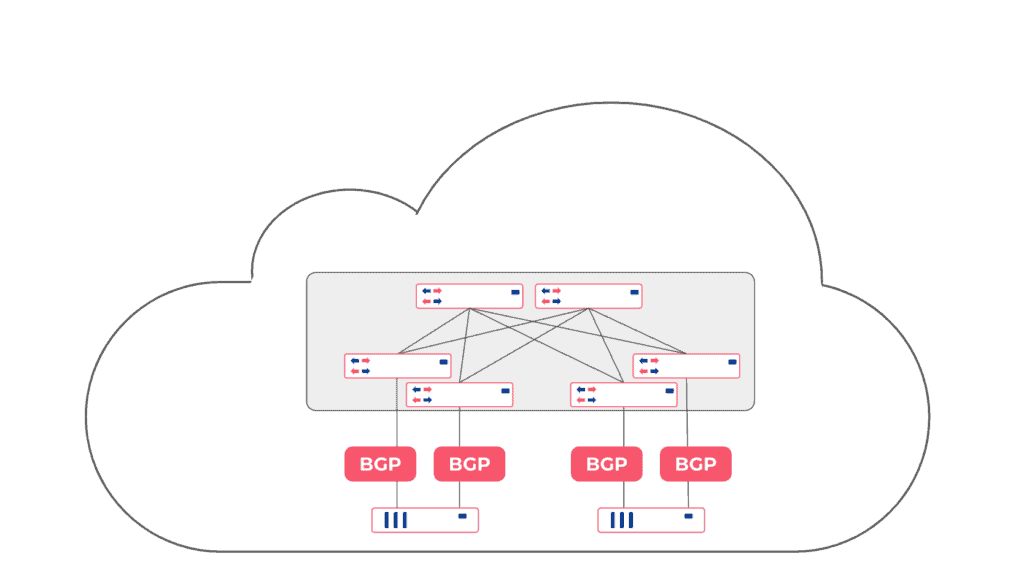
Network to Network links redundancy. (switch to switch to VPC Gateway and to Upstreams)
Netris automatically configures BGP on all network-to-network links, relying on BGP multipath capability for equally distributing traffic across all available links and relaying on BFD and port link state for fast failover in case of a link failure.
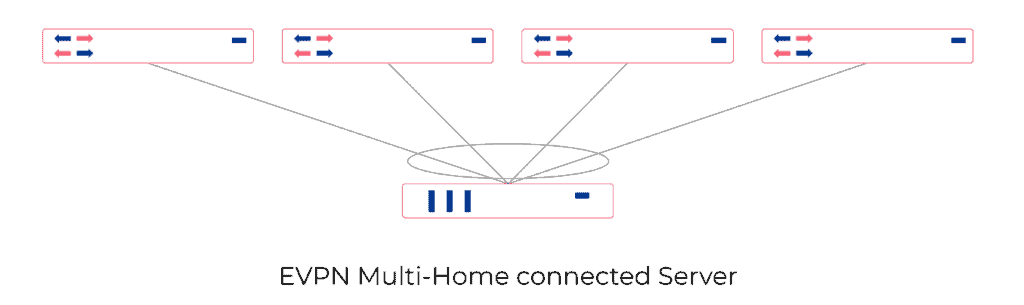
Server Multi-Homing
EVPN Multi-Homing (EVPN-MH) offers robust support for an all-active redundancy model for servers. This means that all connections from a server to multiple switches are concurrently active and operational, ensuring high availability, load balancing, and seamless failover capabilities. As a result, EVPN-MH enhances network resilience and continuity of service.
Automatic Multi-Homed LAG with LACP is designed to provide easy and automatic physical network link redundancy for servers. There is no need for the network and systems engineers to negotiate the LAG and LACP settings manually anymore. Netris-managed switch-fabric monitors LACP messages coming from servers and, by leveraging powerful EVPN/VXLAN capabilities of modern switches, will automatically make appropriate pairs of switch ports form a Link Aggregation with active/active configuration.
Layer-3 Server to Network Redundancy. (aka ROH – routing on the host)
Around 20% of our customers are using this relatively new and highly performant method, and we see more users planning to adopt this. In this scenario, each server is running an open-source BGP daemon (FRR) that forms BGP adjacencies with every network switch it is connected to. While this can be done using standardized BGP config across all servers, it still requires individual configuration on the network switch side. Not a complicated configuration – but it’s tough to manage when you have thousands of those. To address that, we have created easy ROH configuration tools in the Netris controller, where every server administrator can easily get network setup through the web console or Terraform without introducing any risk of breaking the network. Once you create two or more links, the BGP multihop capability will equally distribute traffic across all links and will reroute the traffic if any link or switch failure occurs.
Some users are using BGP Anycast Load Balancing to the host on a global scale to balance traffic across multiple regional data centers and all the way to the server. We have special Layer-3 load-balancing functionality with health checks, but that topic is worth a whole separate blog post.
Conclusion
What we do is not magic (although some of our users call it so). You can configure Linux networking and switch fabrics on your own, as are most of our users. We make your network automatic to give you and your internal users a cloud-like user experience through VPC-like Web Console & APIs.
We uncomplicate your private cloud networking so that you can spend more time on everything else.