
Member post by Cheryl Hung, Senior Director, Infrastructure Ecosystem, at Arm
A recent trend in cloud-native development is the use of multi-architecture infrastructures, which can run workloads on either x86 or Arm architectures. At a high level, the goal of running a multi-architecture infrastructure on a public cloud is to have workloads run on the best hardware for the task, without developers being concerned with the underlying architecture. But that doesn’t mean it’s an easy goal to obtain.
Is migration worth it?
Adding a second hardware architecture to your development infrastructure is a major undertaking since it has implications for just about every aspect of development. But we think it’s worth the effort, for two reasons: affordability and flexibility.
- Better Price/Performance Ratios
Controlling the cost of cloud computing remains a challenge. Prices can change quickly and unexpectedly, suddenly making it less affordable to run the same workloads. Modifying a workload can trigger unanticipated charges, and even small inefficiencies can add to infrastructure costs over time. Having a second architecture to work with can help optimize the price/performance ratio of individual hardware operations, making it easier to generate savings.
- More Choice, More Flexibility
Since 2018, when Amazon Web Services (AWS) launched their first 64-bit Arm-based CPU, Graviton, on the Elastic Computing Cloud (EC2), the ecosystem for Arm-based development has continued to expand. Today’s developers have a much wider selection of options to choose from, so it’s easier to find the best hardware option – x86 or Arm – for a given workload. And, since the latest options may only be available for one architecture and not the other, using a multi-arch infrastructure can increase flexibility and help accelerate innovation.
A Framework for Migration
From a planning standpoint, one of the biggest challenges for multi-arch migration is that it’s not just one thing – it’s pretty much everything. Consider the infrastructure for a sample e-commerce website, shown below.
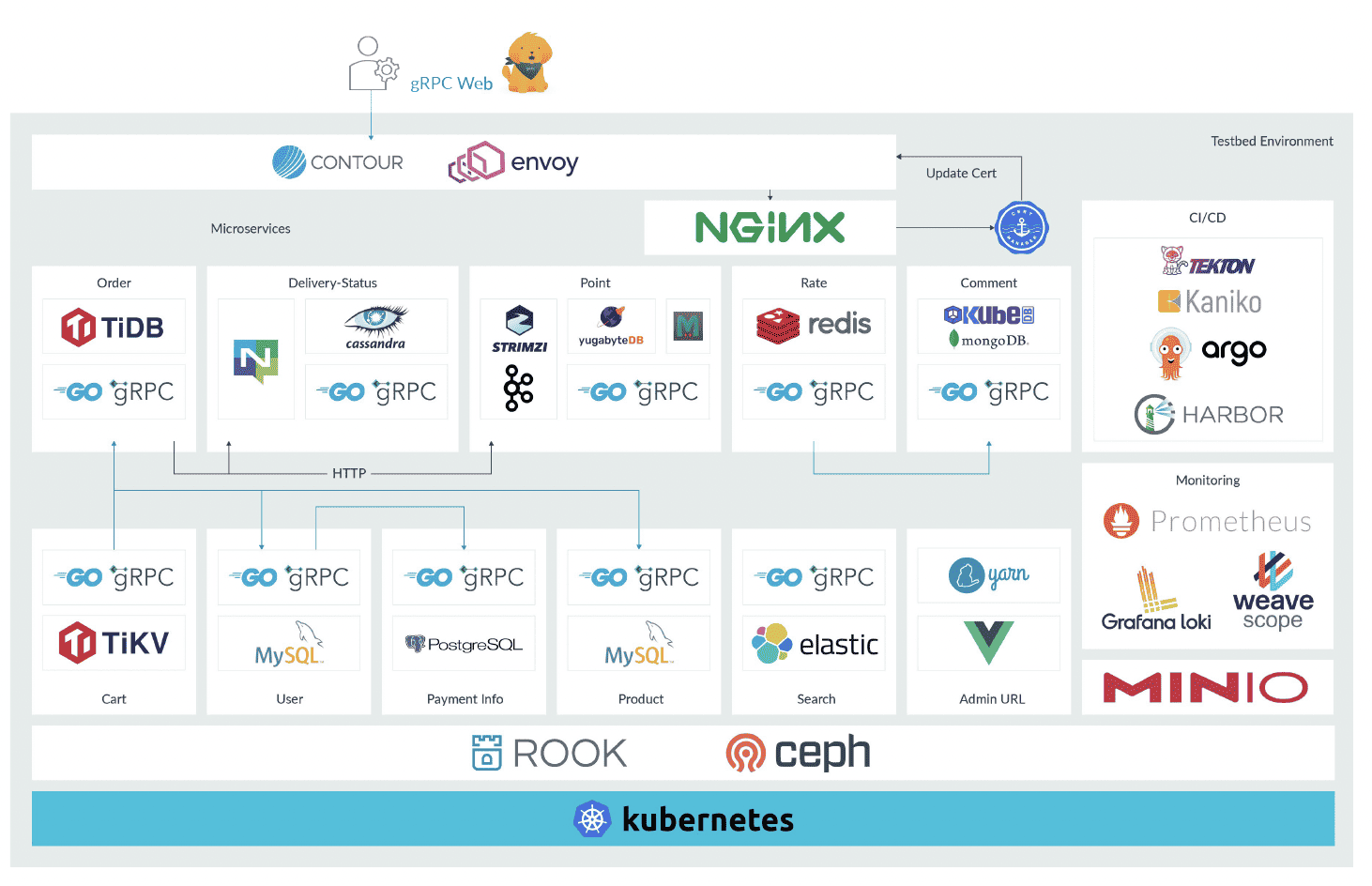
The Kubernetes platform, for container orchestration, is a foundational element, but you also have a CI/CD pipeline, monitoring functions, and a series of container-based microservices. The setup is also likely to include storage of some kind, with or without statements attached.
Upgrading the Kubernetes instance is likely to be an important step of any migration, but it’s only part of what needs to be considered. There are a number of other things to think about, such as the details of your Infrastructure as Code (IaS) setup, the nature of your CI/CD pipeline, and your process for creating reproducible builds. What do your packaging, binaries, images, and registries look like? What are your processes for testing, scheduling, rollouts, and performance evaluations? Also, you may have already optimized your setup to create a good balance between price and performance. Will migration, and the fact that you’re touching so many elements of the setup, change that balance?
The actual mechanics of how you implement your multi-arch infrastructure will obviously depend on your individual setup. Some migrations will be more involved than others. But there are some general guidelines we can recommend, based on our own experience and what we’ve learned from early adopters.
Building on Best Practices
Our recommendations borrow from one of the best in the industry – the FinOps Project of the Linux Foundation. We like their approach to cloud-based management, and like how they divide complex operational tasks into three stages – inform, optimize, and operate.
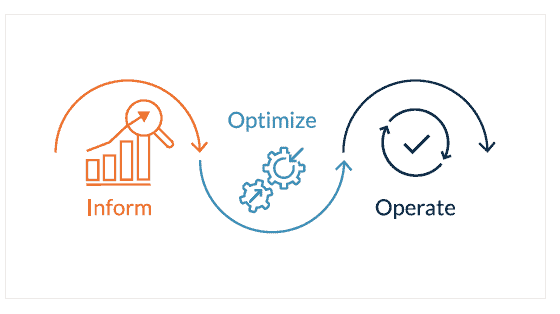
For our purposes, the inform step is where you identify what you’re running. The next step, optimize, is where you pick a subset of workloads to experiment with, and the third step, operate, is where you actually do all the necessary upgrades and begin deployment.
Let’s take a closer look.
- Inform
Make a list of everything involved in your existing development infrastructure. Start with a complete inventory of your entire software stack. What operating systems do you use and what images are you running? What resources do they rely on? Which libraries do you access, and what frameworks do you use to build, deploy, and test? How do you monitor or manage key aspects of operation, such as security?
Capture everything – your list is likely to be quite long – and check that every item has x86 or Arm support. When verifying Arm support, keep in mind that different sources have different names for the 64-bit extensions of Arm. For example, the GNU Compiler Collection (GCC) categorizes them as AArch64, but the Linux kernel lists them under arm64.
Having created your inventory, check for hotspots. What are your most expensive compute items? Where do you spend the most in terms of your existing setup? Knowing where you’ll find the highest proportion of executed instructions can help you understand which aspects of migration will offer the greatest opportunities for savings. - Optimize
Choose a few workloads and provision them to a test environment. To keep things manageable, start small. Update a few container images and test syntax, check your performance tests, and modify your CI/CD pipeline to enable reproducible builds.
Spin everything up to your public cloud and begin working on all the minor upgrades, changes, and “if statement” additions needed to run an additional architecture. There’s no need to upgrade the entire environment before migrating an individual workload. For example, you can make changes without modifying the Kubernetes platform.
- Operate
This is where it gets interesting, because you’ll be building your Kubernetes cluster, revising the infrastructure, and rolling out your new processes.
The first decision is likely to be how you’ll migrate your control plane and worker nodes. You probably don’t want to move everything at once, and you’ll want to think through the options. You might, for example, move control nodes first and work nodes second, or you might move them together, in small batches. The trade-offs for creating each cluster will reflect your software stack, node availability, and the nature of your workloads.
You’ll also want to go through your scripts for cluster creation, adding in the changes for each hardware architecture. Having a mixture of x86 and Arm scripts will affect anything running in a DaemonSet controller. Make sure the correct image is pulled down for the architecture you’re using.
With your new Kubernetes clusters in place, you’re ready to start deploying. We recommend starting with a small subset, as part of a canary deployment, or running the new release candidates alongside the active production environment, in a blue/green deployment. Either way, it’s best to start gradually, monitoring as you go.
When checking if scheduling is working as planned, the Kubernetes concept of node affinity can help streamline the setup. Using a combination of taints and tolerations, you can ensure that the right workloads are running on the right nodes. You may also want to adjust the number of requests for each architecture, finetuning the limits to optimize performance.
A good way to experiment
Looking over these three stages of migration, you probably noticed that what you’re doing in the first two stages – inform and optimize – is basic prototyping. That is, you’re identifying functionality and using a small set of workloads as a proof of concept, to see if your test environment yields good results. It shouldn’t take more than a few spare afternoons to complete these first two stages. As an experiment, it might even be worth doing the first two stages on their own, even if you’re not sure you want to proceed with a full migration.
A Real-World example
FusionAuth, a leading supplier of identity and user-management solutions, was an early adopter of the multi-arch approach and they continue to run a mix of architectures today. FusionAuth was one of the first organizations to provide a developer-focused API for authorization, and that’s the functionality their migration focused on.
The migration was prompted by a community member, looking to experiment with authorization on a Raspberry Pi development board. FusionAuth is a Java shop, which meant they had to find a Java Virtual Machine (JVM) that supported Arm (Java 17 was the first version to do so). FusionAuth added Java 17/Arm support to the code, and then updated Docker to target the Arm architecture with jlink and multi-arch builds. Because they run on Java, the FusionAuth lift was relatively small. The biggest hurdle was finding a JVM built for Arm. After that, it was a matter of working out any remaining kinks.
When FusionAuth was in development (2021/2022), the number of public-cloud regions running Arm was still fairly limited, so they had to be selective when spinning up their new SaaS offering. As a final step, they updated their application to expose the underlying architecture. After loading tests onto AWS Graviton, they began official support for Arm in June of 2022. The expansion was quick, and as of March 2023, more than 70% of their Saas instances were running Arm.
For their load tests, FusionAuth chose logins, since password hashing makes logins an especially CPU-intensive process. Having tested 50,000 logins in the EC2 environment, they found the Arm architecture handled between 26% and 49% more logins per second, and cost between 8% and 10% less than the equivalent setup with an x86 architecture.
Conclusion
In light of the rising cost of cloud computing, and the increasing presence of Arm-based hardware architectures in a wider variety of applications, it can make sense for development teams to consider a multi-arch infrastructure. In many cases, the upfront work saves time and effort down the road, since having a multi-arch infrastructure in place makes it easier and faster to create, introduce, and maintain new features.
To learn more about the benefits of multi-arch infrastructures in public clouds, and to see more case studies of successful multi-arch migrations, visit www.arm.com.