


Member post originally published on the Buoyant blog by William Morgan
A guide to Kubernetes sidecars: what they are, why they exist, and what Kubernetes 1.28 changes
If you’re using Kubernetes, you’ve probably heard the term sidecar by now. This concept is the foundation of several important building blocks in the cloud native ecosystem, most notably service meshes. What might surprise you, however, is that Kubernetes itself has no built-in notion of sidecars—at least, until now. That’s finally changing with the long-awaited merge of “sidecar KEP” in the upcoming Kubernetes 1.28, which officially introduces sidecars to the Kubernetes API.
But what does this KEP actually mean? In this guide we’ll walk you through all you’ll need to know: what sidecars are, what’s good, what’s bad, and what’s changing about them in Kubernetes 1.28.
Pods, containers, and init containers
Before we dive into sidecars, let’s make sure we understand the basics of how Kubernetes organizes its application components.
The core unit of execution and addressability in Kubernetes is the pod. A pod contains one or more containers. Each pod is assigned a unique IP address, and the containers in a pod all share this IP address. The containers can each listen to different ports, but all containers in a pod are bound to that IP, and are “part” of that pod—when the pod dies, so do they.
Using pods as its basic building block, Kubernetes then provides a huge number of constructs built on top of them. There are ways to replicate pods, organize them, manage changes to them, name them, allow them to talk with each other, and more. But for our purposes today, we don’t really need to understand much about how pods are used; just that they are a core building block of most Kubernetes constructs.
While different pods may have different properties, as far as Kubernetes is concerned, there aren’t different “types” of pods. Pods are pods. The same is not true for containers. Kubernetes recognizes two types of containers: ordinary containers and init containers.
Init containers, as the name suggests, run at pod initialization time, before the pod is ready for action. Init containers are expected to terminate, and once all the init containers terminate in a pod, the ordinary, non-init containers run. Ordinary (non-init containers) start after the init containers are all done, and typically continue running forever until the pod itself is terminated. (There are some exceptions to this behavior for workloads like Jobs, which are expected to terminate when they’re done, but this is the most common pattern.)
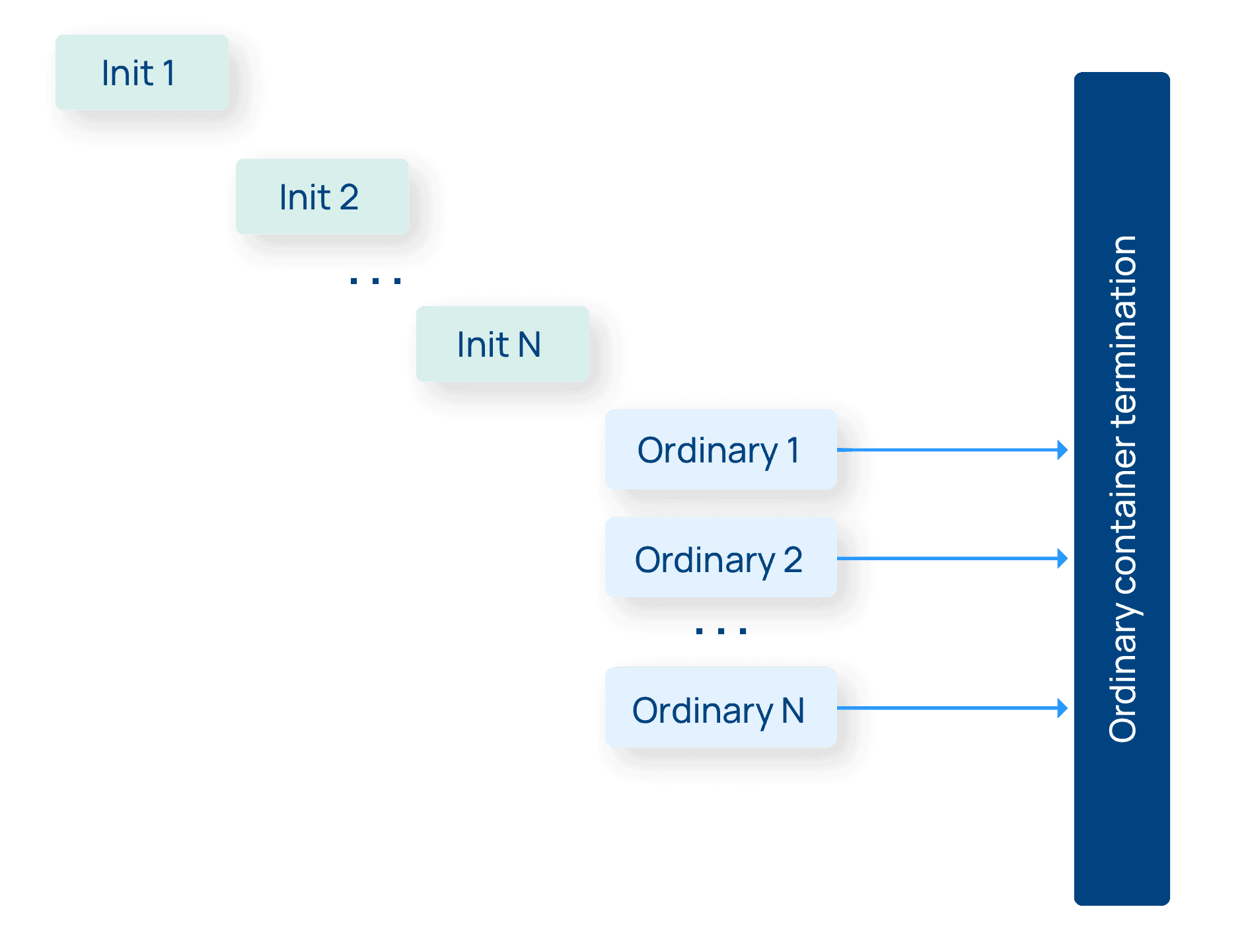
This distinction between init containers and ordinary containers is going to be key to the new sidecar functionality unlocked in Kubernetes 1.28. But before we get into that, let’s finally take a look at sidecars.
So what is a sidecar?
For the entire history of Kubernetes up until now, a sidecar has simply been a name for a pattern, not an actual feature of Kubernetes. A sidecar is a container that runs “next to” a main application container, just like a sidecar attached next to a motorcycle. This has been solely a matter of convention—the only distinction between a “sidecar container” and every other container is what it does.
But why is the idea that a container can run next to another container so interesting and so deserving of a special name? Because the sidecar pattern provides something really powerful: a way of augmenting an application at runtime without requiring code changes, while running in the same operational and security context as the application itself. That statement is key to understanding the power of sidecars and, I think, the power of Kubernetes’s pod model.
A way of augmenting the application at runtime without code changes. Sidecars give you a way to add functionality to an application, without needing to recompile the application, or link against new libraries, or change it in any way. This means that not only do the developers not need to be involved, but that the sidecars can work with applications written in any language.
While running in the same operational and security context as the application itself. This is the really powerful part. Because the sidecars run in the same pods (as opposed to elsewhere in the system), they are effectively treated as part of the application. If a sidecar fails, it’s equivalent to failure of the pod it’s running in. If a sidecar has a security breach, that breach is limited to the pod. If a sidecar consumes a crazy amount of resources, it’s as if the application itself consumed those resources. All of the Kubernetes mechanisms for handling these situations are applicable to sidecar-enabled applications without change.
This combination of “I can augment an application without requiring the developers to get involved” with “I can treat these augmentations the same way as I’m treating the applications in the first place” has been a boon to platform owners—especially since most of the augmentations that sidecar-based projects like services meshes provide are platform features rather than business logic.
Common examples of sidecars in Kubernetes include metrics agents that instrument the application containers and report data back to a central metrics store, or log aggregators that capture container logs and relay them elsewhere. But probably the biggest example of sidecars in action is the service mesh.
A service mesh uses the sidecar model to add a network proxy to every pod. These sidecars intercept all TCP connections to and from the application, and “do things” with the requests on those connections to accomplish an impressive list of features—these proxies can provide features like mutual TLS between pods, fine-grained HTTP metrics per component, request retries, transparent cross-cluster communication, and much more. What these proxies are, exactly, can vary across implementations. Many service meshes use the popular Envoy project, but Linkerd for example uses ultralight “micro-proxies”, written in the Rust programming language, an approach that improves performance and security while greatly reducing complexity and resource consumption. (You can read more about our decision to adopt Rust.)
The power of the sidecar model means that not only can a service mesh like Linkerd add these features transparently, but they also scale with the application and avoid introducing single points of failure to the cluster.
Do we really need sidecars? Can’t, like, the network do this?
Despite their popularity, sidecars have always been something of a controversial topic. To those coming to the service mesh from, say, the application or platform owner background, the value of the sidecar model is clear: you get the benefits of a shared library with effectively none of the drawbacks. This is essentially the perspective I’ve shared above.
For someone whose perspective is that the service mesh is a networking layer, however, the idea that L7 network logic should be placed close to the application rather than “in the kernel”, or at least “somewhere where I can’t see it when looking at my application” runs counter to the traditional relationship between application and network. After all, every time you look at a pod, the service mesh sidecar is there staring back at you! From the networking perspective, that can feel like a weird and unwelcome violation.
In fact, this division has come to a head with the introduction of “sidecar-free” service meshes. Leaving aside the breathless marketing that is delivered with these approaches (we will “solve service meshes” using miracle technologies with names like eBPF or HBONE), these service meshes ultimately all work by moving the core logic to per-node or per-namespace proxies rather than sidecars. In other words, the proxies are still there— just not in your pods any more.
We’ve looked at these approaches closely and ultimately haven’t adopted them in Linkerd. There’s a lot to say about the tradeoffs here and if you are interested in falling asleep to that particular topic, I cover much of it in my long evaluation of eBPF and its utility to service meshes. Suffice it to say that L7 traffic is not like L4 traffic, and that you lose critical isolation and security guarantees that you get with sidecars and I think you end up taking a big step backwards operationally and security-wise.
But for the purposes of this article, we can ignore all of my many opinions. We’re here to talk about sidecars! And all is not perfect in sidecar-land. Sidecars do come with some real downsides and annoyances. Let’s see why.
What are some of the complications of sidecars?
The same powerful pod model that allows Kubernetes to give us pods is also the source of several of the annoyances around sidecars. The major ones are:
- Upgrading sidecars requires restarting the entire pod. Because Kubernetes pods are immutable, we can’t change one container without restarting the entire pod, including the application. Now, Kubernetes applications are supposed to be built to handle arbitrary pod restarts and shutdowns, and Kubernetes provides all sorts of mechanisms like rolling restarts that allow this to happen with zero downtime for the workload as a whole—but it’s still annoying.
- Sidecars can prevent Jobs from terminating. Remember my note about Jobs above? Jobs are one type of Kubernetes workload that is expected to terminate by itself after completion. Unfortunately, Kubernetes does not provide a way to signal to the sidecar that it should terminate, meaning that by default the Job pods will run forever. There are workarounds to fix this (ours is called linkerd-await) but they require changes to the application container that violate the transparency of the service mesh.
- Sidecars can race with the application at startup. While Kubernetes runs init containers in a specific order, it doesn’t provide an ordering guarantee for regular containers. This means that during startup the application isn’t guaranteed that the sidecar is ready, which can be problematic if you need that sidecar to, say, make network connections to the outside world. (There are some hacks to get around this which Linkerd uses.)
None of these are showstoppers, really, but they’re all annoying and in some cases require hacks or workarounds.
What kind of hacks? To give you a taste: for preventing race conditions, it turns out there actually is a postStart hook for containers which, while this isn’t really in the spec, will block the next container from starting until the hook is complete. So, Linkerd adds its proxy as the first container in the pod and uses a postStart hook to ensure it is up and running before the other applications. Race condition averted! However, because Linkerd is now the first container in the pod spec, tools like kubectl logs will emit Linkerd proxy logs by default rather than application logs. This is a huge annoyance for users! But not to fear, in Kubernetes 1.27 there is a notion of default containers which can be set on the application container. That can be used to help kubectl do the right thing. But not every cluster is on 1.27… etc. The whole setup is messy and fragile but that’s the state of the art today.
Like I said: hacks.
To date, that has been the state of using sidecars in Kubernetes—things mostly work, but there are some rough edges that you occasionally cut yourself on. But now Kubernetes 1.28 is here to save the day!
What’s happening in Kubernetes 1.28?
Finally, let’s talk about the Kubernetes 1.28 and the sidecar KEP. This KEP, or Kubernetes Enhancement Proposal, was first kicked off in 2019 and has faced years of argumentation, stagnation, redesign, and close calls. It has become something of an in-joke in the Kubernetes world!
Now, four years later, it seems like sidecar KEP has finally made it into an alpha feature in the upcoming 1.28 release. And what this KEP changes actually all goes back to init containers.
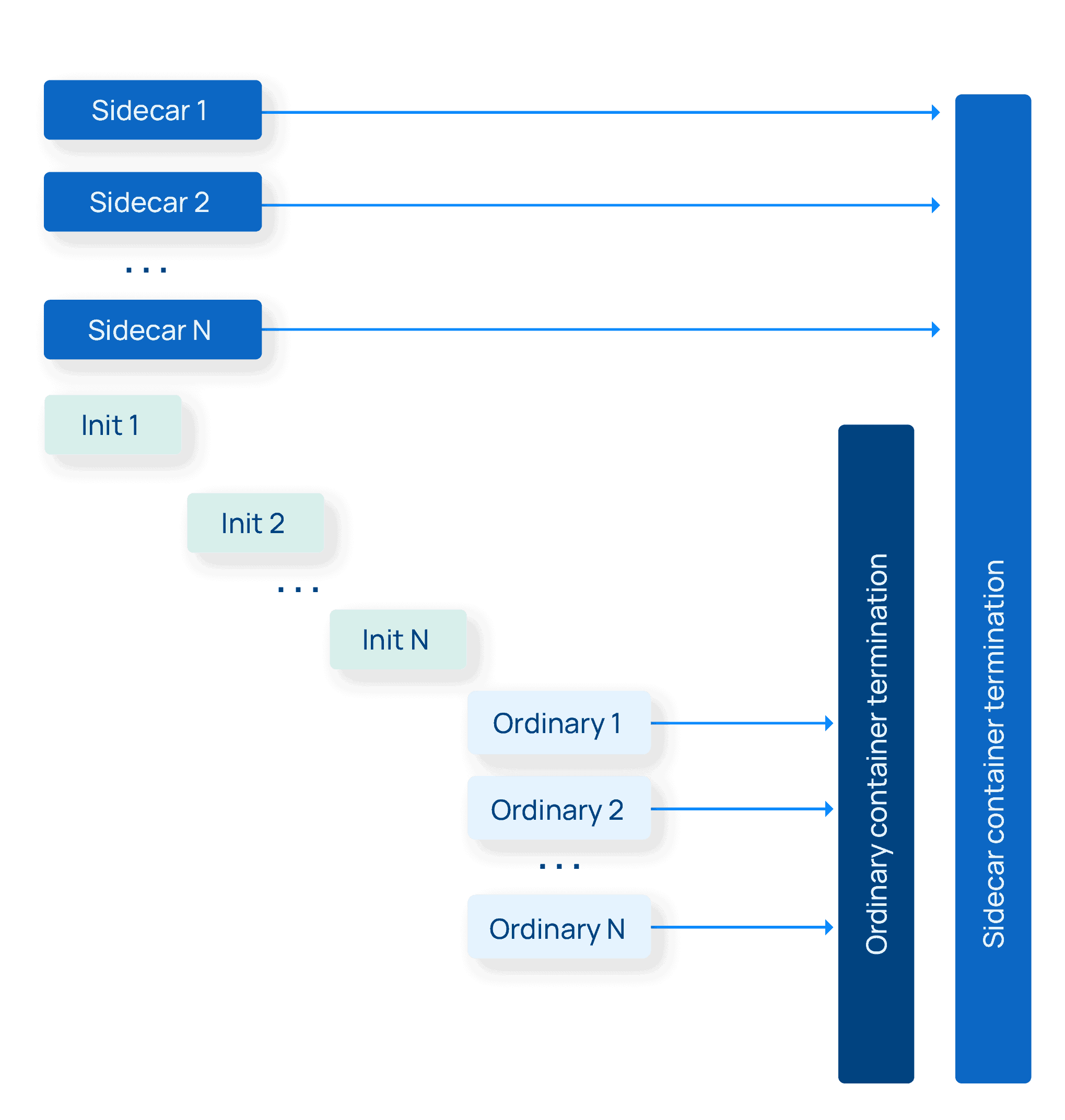
The KEP introduces a new RestartPolicy field to the specification for init containers. Here’s the description of this field:
RestartPolicy defines the restart behavior of individual containers in a pod. This field may only be set for init containers, and the only allowed value is “Always”. For non-init containers or when this field is not specified, the restart behavior is defined by the Pod’s restart policy and the container type. Setting the RestartPolicy as “Always” for the init container will have the following effect: this init container will be continually restarted on exit until all regular containers have terminated. Once all regular containers have completed, all init containers with restartPolicy “Always” will be shut down. This lifecycle differs from normal init containers and is often referred to as a “sidecar” container. Although this init container still starts in the init container sequence, it does not wait for the container to complete before proceeding to the next init container. Instead, the next init container starts immediately after this init container is started, or after any startupProbe has successfully completed.
Let’s break this down:
- You can now specify a new RestartPolicy: Always configuration for an init container.
- If you add that new config, you now have a sidecar container.
- A sidecar container starts before all ordinary containers (because it’s an init container), and—this is the big part—it now terminates after all the ordinary containers all terminate.
- If for some reason your sidecar container dies while ordinary containers are running, it will be restarted automatically. (This is the “Always” bit.)
- Finally, unlike with normal init containers that each wait in turn to complete before the next starts, the other init containers do not wait for sidecar containers to complete before starting. Which is good, because they’re not going to complete until much later.
In essence, this KEP introduces a mode that is almost like a “background container” (or as the ancients called it a “TSR container”). These new sidecar containers start before the ordinary containers and terminate after them. In one fell swoop this solves numbers 2 and 3 from our sidecar annoyances list: we can now terminate automatically when the Job terminates, and we no longer have a startup race condition vs ordinary containers, and we can back out all the silliness with postStart hooks and default containers.
Victory! With this new feature, sidecars are cool again. Or are they?
The glorious future that awaits us in Kubernetes 1.28
I titled this article “Revenge of the Sidecars,” but obviously that’s a bit of hyperbole. The sidecar KEP does remove two of the biggest warts on sidecar usage in Kubernetes: support for Jobs and race conditions around container startup. Both of those issues have workarounds today, but these workarounds impose some unfortunate consequences on the mesh owner; in Kubernetes 1.28 and beyond we can remove those workarounds entirely.
Does that mean that all is well in sidecar land now? Personally, I think there are still some challenges to a more general acceptance of sidecars. The biggest of these are (ironically enough) around visibility: because you can see sidecars in every pod, a) that doesn’t sit right with our traditional view of networking, and b) the resource impact of sidecars is very visible. If a shared library used 200 megs of memory and 5% of your CPU, you probably wouldn’t notice; if a sidecar does it, it’s very noticeable. (Happily, Linkerd resource usage is extremely minimal, in part because of Rust’s excellent memory allocation controls.)
Last year I made a joking claim that we were going to remove sidecars from Linkerd… by hiding them from the output of kubectl (using eBPF, no less)! Unfortunately for me, responses to this idea were so enthusiastic and excited that I had to post a followup tweet explaining the joke. We were not actually going to fork kubectl. But like all good (?) jokes, there’s a kernel of truth in there, and I wonder how much of the “we need to kill sidecars” sentiment would diminish if the sidecars were there but simply invisible or hidden behind a flag.
All that said, our job with Linkerd is to provide the fastest, lightest, and simplest (read: lowest TCO) service mesh on the planet, and nothing has yet convinced us that sidecars aren’t the best way to do that. So for the foreseeable future, the glorious future that awaits Linkerd users, at least, is more sidecars and fewer warts. And hopefully, no forking of kubectl.
Get mesh-y with Linkerd!
If you’re on the market for a service mesh, I hope you give Linkerd a try. Companies like Adidas, Plaid, Microsoft (Xbox Cloud), and many more rely on Linkerd to power their critical production infrastructure. We’d love to help you get started, whether through pure open source means or as a commercial partner. We’ve helped companies around the world cut through the hype and deploy rock-solid service meshes to production, whether for zero trust security policies, mutual TLS, FIPS-140-2 compliance, or more. Contact us today!