


Community post by Bill Mulligan
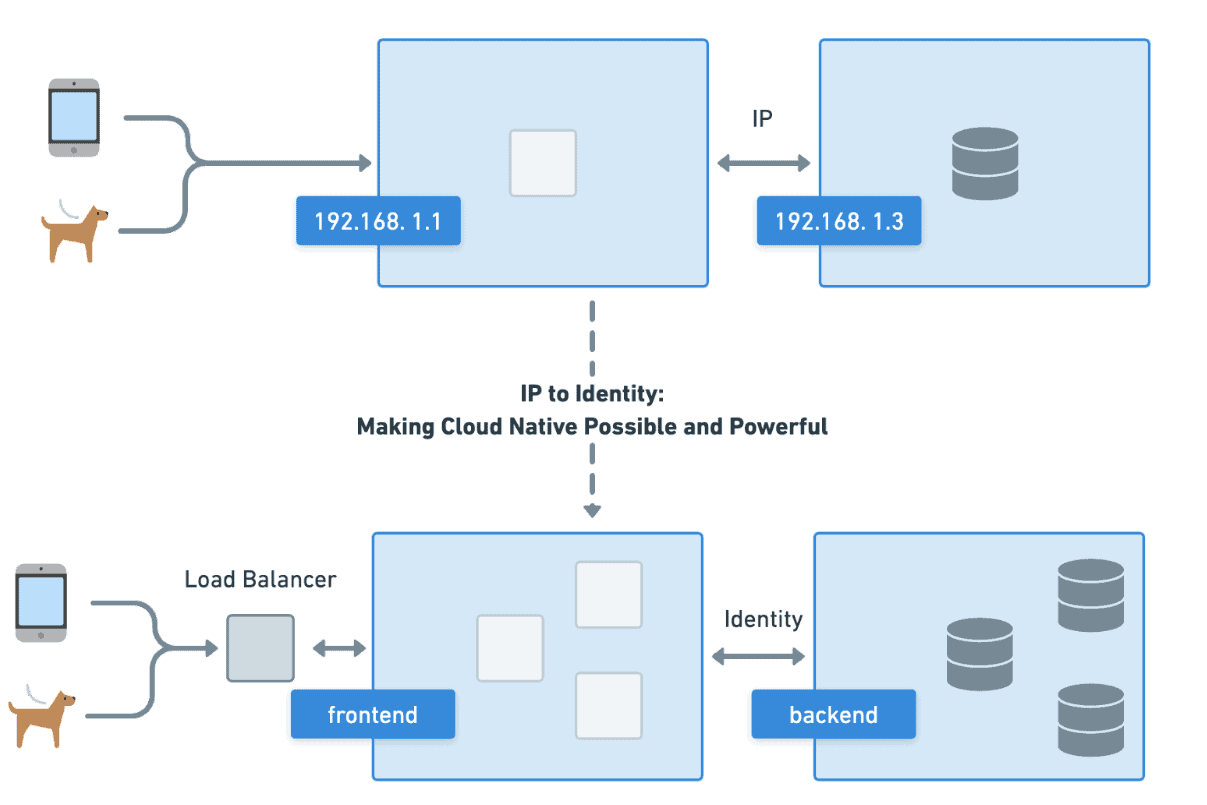
From one bit modifying the next to frontend talking to backend, IT is fundamentally about identity, who is talking to what and what is the outcome of their interaction. This concept of identity brings order to what would otherwise be a chaotic stream of information, transforming it with technology into what we know as IT (information technology). However, as the scale and complexity of the industry has grown, so have the challenges around identity. The DevOps movement was in part founded on the idea that we need to move away from treating machines like pets with individual names and memorized IPs towards cattle where they were interchangeable, scaling identity from the individual to the indistinguishable group.
Cloud natives’ most fundamental and powerful abstraction is moving from static IPs and machines to identities backed by replaceable pieces based on workload metadata. By abstracting away from the individual workload towards an identity backed by a group of things, we can transform from managing pets to herding cattle, making cloud native possible and powerful. By associating low-level constructs like IP and process ID with high-level constructs, like Kubernetes labels, cloud native has been able to revolutionize how we think about, architect, and run our IT systems and infrastructure. While many of the fundamental concepts have remained the same, the scope at which we can now operate has drastically changed thanks to identity in the cloud native era.
Kubernetes, Cilium, and other cloud native projects have taken the idea of scalable identity and made it a core concept of their platform. Instead of hard coding IPs into applications, “frontend” can now talk to “backend” even if the machine or network behind either is updated or changed. Services and applications are no longer Pets that need to be individually tended to, but are now cattle abstracted behind a cloud native identity. This article traces the evolution of identity in systems programming to the current cloud native era and shows how identity is now key to how cloud native projects, like Kubernetes and Cilium, create powerful platforms in the real world today.
Identity as a Core Systems Concept
At its most basic level identity helps operating systems keep track of who is doing what on a system with things like process ID and user ID. With basic identity in place systems can use them to start implementing higher order ideas like security, debugging and troubleshooting, and resource allocation. Let’s walk through each of these to understand why identity is so important to each of them for systems programming.
To make themselves secure for use, systems need to ensure that only authorized users and processes have access to system resources, such as memory, files, and devices. Process isolation prevents one process from interfering with another. With identity, the system can differentiate between different processes and stop them from accessing or modifying each other’s data and is crucial for implementing access controls and preventing unauthorized use, which would otherwise lead to security vulnerabilities, exploits, and misuse of resources. Next, when things go wrong, we need to be able to identify the source of a problem and track its progress through the system. Identity can be used to identify and track different processes and their interactions, allowing for more effective debugging and troubleshooting.
With everything secured and working properly, systems next need to determine the proper distribution of resources. System resources, such as memory, CPU time, and network bandwidth need to be managed and allocated to different processes and users. Identity is used to associate and track resource usage to different processes and users, allowing for more efficient resource allocation and management.
Combining security and resource allocation with identity also allowed us to create containers through the use of cgroups and namespaces. Expanding beyond a single machine to a network of devices, identity becomes even more imperative. Without identity, machines won’t know who to talk to or where to find them. Automatically giving an identity to flows through a network has been an implicit goal of networking for a long time to solve this exact problem. From a single machine to a multitude, identity is the cornerstone upon which we build our systems and platforms.
The Limits of Memorizing IPs and Naming Machines
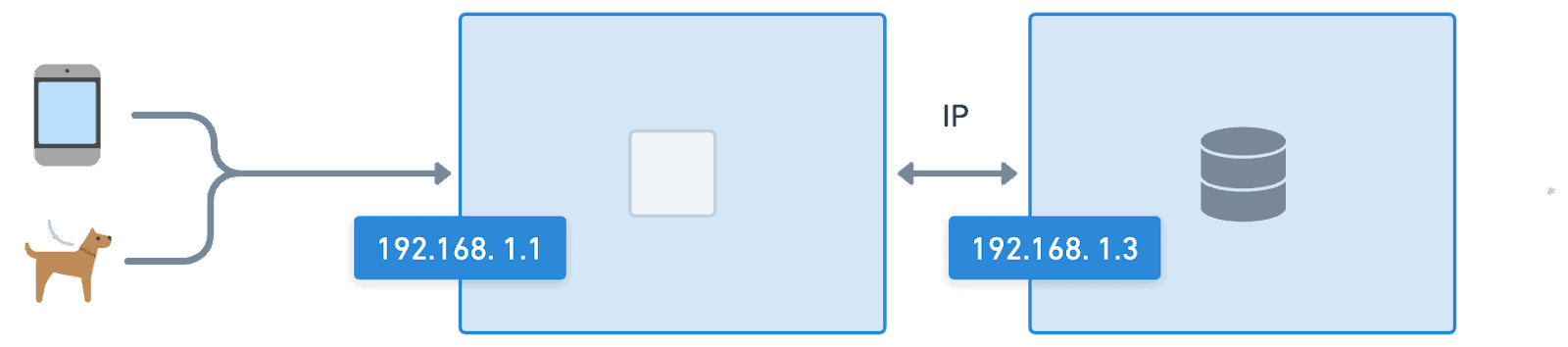
As we started to scale our IT systems, machines on a network were given an identity in the form of an address where other devices can reach them, usually in the form of an IP address. In a world where people could memorize IPs and gave machines names in a spreadsheet (based on their favorite video game or show) this approach works. However, static IPs and DHCP reservations only scale so far due to human error, system complexity, and operational overhead.
As the number of machines and devices on a network grows, relying on humans to remember and enter IP addresses and machine names can lead to errors, such as typos and transpositions, resulting in connectivity issues and security vulnerabilities. It also becomes increasingly difficult to remember the IP addresses and names of every machine as the complexity of the environment grows. If those weren’t large enough challenges, updating and maintaining a list of IP addresses and machine names is a time-consuming and error-prone task. This can lead to inconsistencies and inaccuracies impacting system performance or even crashing it completely.
Memorizing IPs and naming machines only works when you can tend to each of them like your favorite pet. When a few pets turn into hundreds or thousands, a way to manage these as cattle instead is needed to mitigate operational risks or even just make it possible.
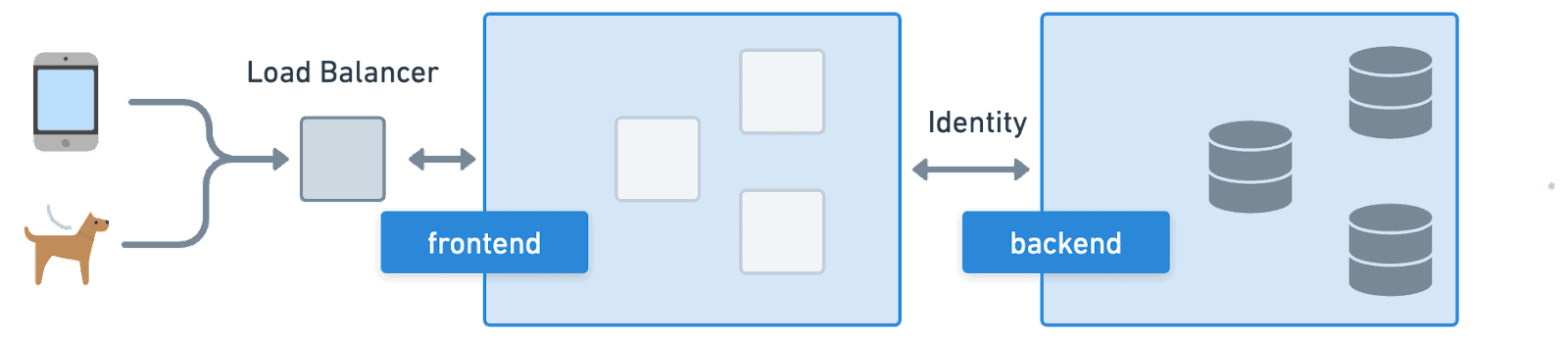
Making Cattle out of Pets with Identity in Cloud Native
In the cloud native world, dynamic and scalable environments are no longer the outliers, but the norm. IP addresses come and go (and are reused) so fast that they’re no longer useful for identity of a source or destination and almost the same can be said for machines. Cloud native environments needed a new abstraction for identity to transform these pets into cattle.
Instead of thinking about the individual, cloud native abstracts them behind an identity that is backed by disposable and replaceable resources rather than unique and persistent entities. Treating infrastructure like cattle with abstracted identity plays a crucial role in the cloud native approach because it provides a standardized way of identifying and authenticating resources. Rather than relying on manually assigned IP addresses or naming machines, groups of resources behind a single identity can be managed and orchestrated in an automated way.
This enables more efficient and scalable infrastructure management, as resources can be easily added, removed, and replaced without requiring manual intervention and in an almost transparent manner to the end user. It also enables more effective security and compliance, as identity-based access controls and auditing can be implemented at scale. By treating resources and systems as disposable and using standardized identity mechanisms, cloud native projects can provide greater efficiency, scalability, and security for infrastructure management. Let’s dive into a few examples to understand how cloud native is changing identity in the real world.
Identity in the Real World with Kubernetes
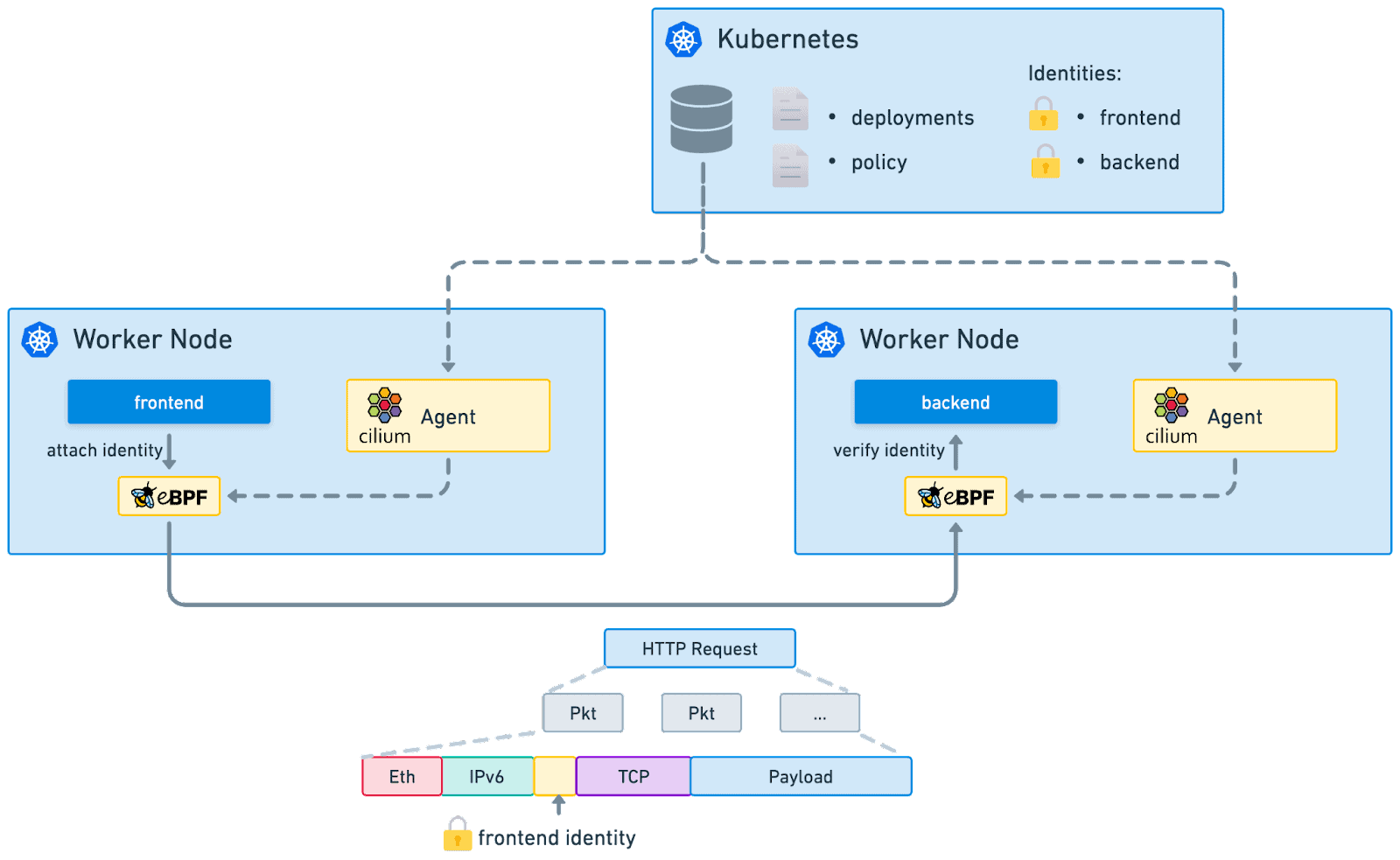
Kubernetes transformed the infrastructure management space because it allowed users to declare what they wanted and the system would take care of the rest and if anything went wrong, it would work to automatically bring it back to this desired state. Suddenly, users could just declare “I want three replicas of `frontend`” and Kubernetes would take care of setting up the application and making it available to others through things like services. Kubernetes’s killer feature is creating and managing the identity metadata that can be leveraged by other parts of Kubernetes and tools in the cloud native ecosystem to interact with the application.
Walking through a very simple example will make this even more clear. Let’s say we have a web application that allows users to access information in a database. In a traditional infrastructure management model, we would set up the frontend and the database on two machines. For a user to make a request, they would need to know the domain where the application is available which would route to a machine with an IP. The front end would then need to access the database through its IP (usually hardcoded into the application). If any of these machines or IPs changed, there would need to be a maintenance window where the identities could be updated. Multiple instances of the frontend or database could be added for resilience, but this information would still need to be kept up to date.
In the Kubernetes world, this is drastically different. Users will still access the application through an IP, but that IP can be backed by a Kubernetes service which maps to a replica set with interchangeable pods. The Kubernetes service, using labels on pods and cluster IPs, will automatically keep identity information up to date, allowing the user to access the application and the application to access the database even as pods, machines, and IPs change. The Kubernetes service provides an identity which abstracts away the underlying pods and their IPs.
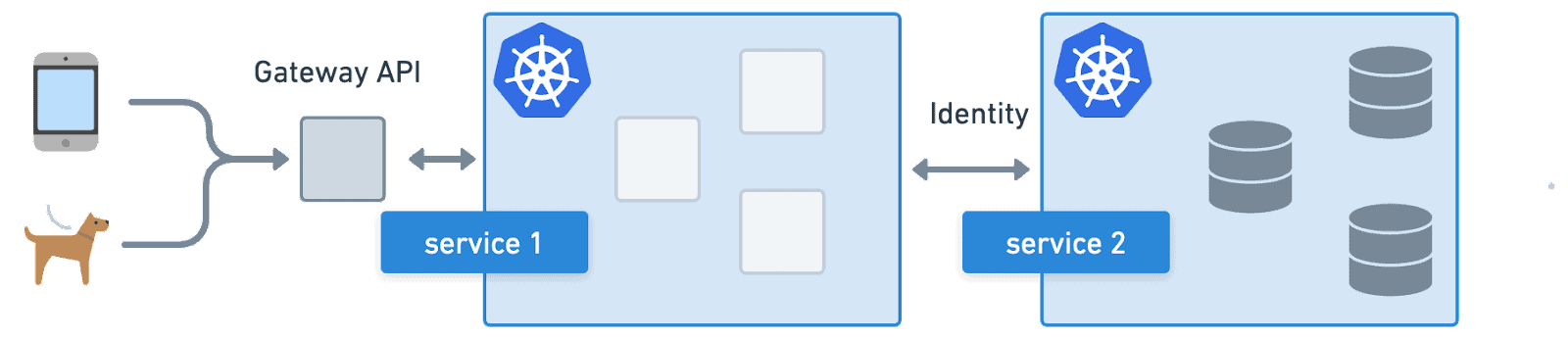
Kubernetes is powerful because it abstracts away the underlying infrastructure, making developers only have to deal with higher level identity like letting the frontend talk to the database. With this meta data in place, other cloud native tools can reuse these abstract identities to transform other parts of the platform from pets into cattle.
Cilium Identity for Networking, Observability, and Security
Cilium is a platform for networking, observability, and security that takes low-level network constructs like IP with high-level Kubernetes constructs like labels, joining them together to create the Cilium Identity. Leveraging Cilium Identity as the core of the platform allows Cilium to flexibly address multiple problems across the cloud native world like meshing multiple clusters together, simplifying observability, providing service mesh functionality, and even extending cloud native beyond just Kubernetes.
Cilium began as a simple networking CNI, but since then Kubernetes deployments have grown to often encompass multiple clusters. Because Cilium already gives an identity to everything in the cluster, identity can also be extended across clusters in a seamless fashion. Suddenly, your application isn’t backed by a single database, but by multiple databases across different clusters. This can be useful for scenarios when the local database is unavailable due to outages or upgrades. The application will continue to deliver results because it can “failover” to a remote cluster. Network policies can also be applied in a global fashion, enabling things like blocking cross cluster traffic between tenants, but allowing traffic to ingress from different clusters.
Cloud native switched to a cattle management model because things can go wrong and when they do, we need a way to spot the problem and remediate it. Hubble provides observability by once again connecting low-level constructs like IP to high level ones like pods or Kubernetes namespaces. When traffic isn’t being routed correctly between two IPs, rather than reading through tcpdump and matching IPs, it can tell you which pods are problematic and what network policies have been applied to the namespaces they are running in. This information can also be exported and associated with the identity to provide a consistent observability view across metrics, logs, and traces.
A service mesh, for all of its hype around features like weighted routing, rate limiting, and mTLS, is all built on top of the idea that the config identifies the workload. In a traditional service mesh, a sidecar was required to provide identity to the workload and do things like attesting the identity via a TLS keypair for mTLS. However, since Cilium already provides a network identity to workloads, it can provide service mesh features to users without sidecars and in a completely transparent manner to the end user. For example, Cilium’s mutual authentication implementation associates Cilium identities with TLS keypairs automatically.
Finally, expanding outside the world of just Kubernetes and integrating into legacy workloads, Cilium Mesh adds Cilium Identity to any workload on a network to connect Kubernetes clusters, virtual machines, and physical servers running in the cloud, on-premises, or at the edge. Cilium Mesh extends the reach of Cilium-based networking, observability, and security beyond cloud native environments by using non-Kubernetes metadata as a part of the Cilium Identity. The datapath of Cilium has always been generic and applicable to use cases beyond Kubernetes because of how it handles identity on the network. In fact, several users have been using Cilium as a pure vSwitch in environments such as OpenStack and Cilium Mesh just officially enlarges this scope.
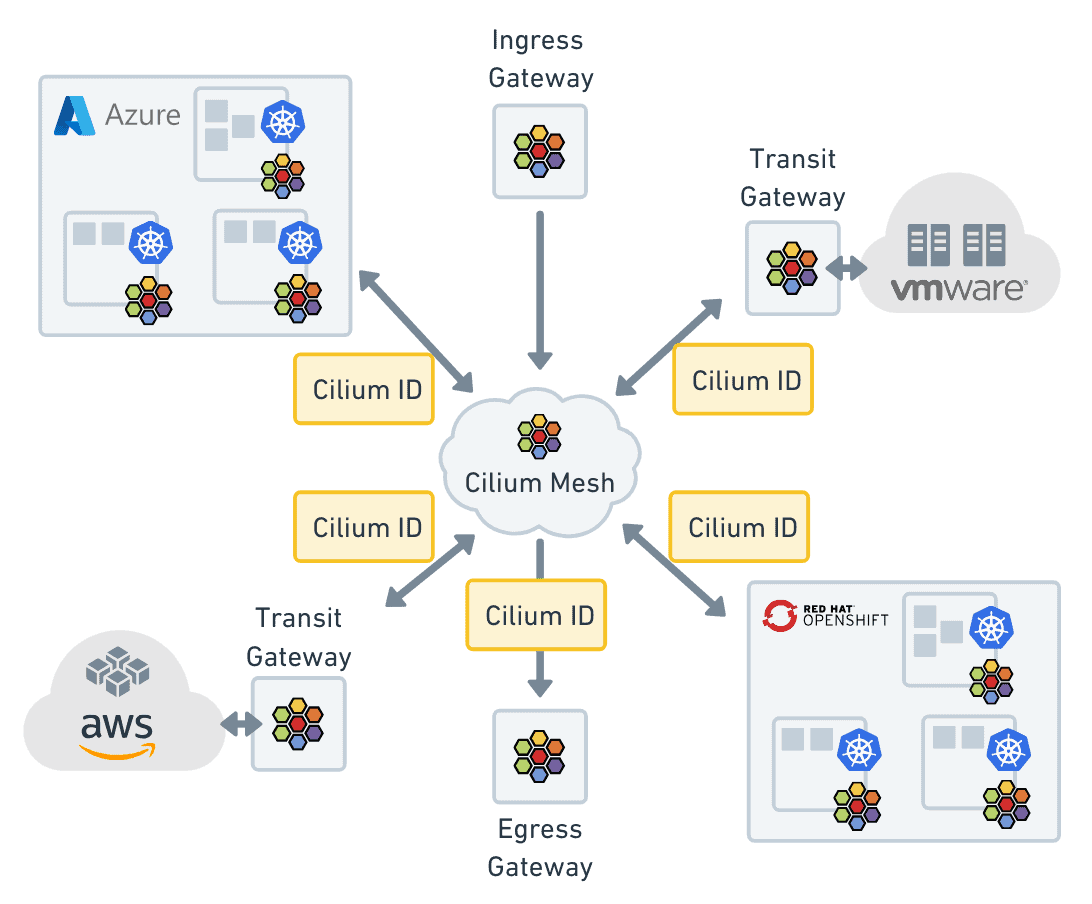
Across clusters, observability, service mesh, and extending beyond Kubernetes, Cilium is able to provide a consistent management experience because it treats identity as a first class citizen in its platform. With identity, cloud native networking, observability, and security has gone from healing pets to herding cattle.
Identity Constructs Cloud Native Cattle
The evolution of identity in systems programming has enabled the development of cloud native platforms that are more dynamic, scalable, and efficient than ever before. From the basic concepts of process and user ID to the modern abstraction of workloads backed by replaceable resources, identity has played a critical role in the development of IT systems, infrastructure, and platforms. With the advent of cloud native technologies like Kubernetes and Cilium, we can now think of services and applications as cattle rather than pets, abstracted behind an identity that enables scalability, simplified operations and troubleshooting, more secure systems, and efficient resource allocation. As the industry continues to evolve, identity will undoubtedly remain a crucial concept for systems programming, enabling us to build even more powerful and innovative platforms for the future.
If you want to hear more about the evolution of cloud native from Bill Mulligan, follow him on Twitter or LinkedIn.