


By Mark Robinson, Infrastructure Engineer, Plaid
How to let hundreds of deployments every day work without tears
Plaid is the engine behind the world’s most successful fintech applications, supporting over 10,000 banks globally. To achieve that, our engineering team releases hundreds of times per day, across hundreds of services, with seamless automatic monitoring and rollbacks if needed. In this blog post I’ll share how cloud native tech and Linkerd in particular helped us achieve that.
The Plaid engineering team
Plaid provides a computing infrastructure that allows users to seamlessly access banking systems. Common friction points, such as connecting with thousands of individual banks each with its unique API, are eliminated. Instead, our customers connect to Plaid and Plaid establishes that connection, ensuring a secure and reliable data exchange between financial institutions. Plaid provides easy access to thousands of banks in the US, Canada, Europe, and Great Britain. Today, the world’s most successful fintech apps rely on Plaid, including Venmo, Acorns, Betterment, Chime, and SoFI.
We have about 400 developers and 15 platform engineers responsible for around 250 services running on a dozen clusters distributed across all regions. I’m an Infrastructure Engineer and responsible for improving the deployment experience and how engineers interact with Plaid’s infrastructure.
Deployments were slow and painful. We needed a change!
At Plaid we use a monorepo with several hundred services. While creating changes that touch dozens of services are easy to write, deploying them everywhere was a huge amount of work. That led to services often becoming stale and people deploying even slower because they didn’t have visibility into what they were deploying. That, of course, didn’t incentivize good deployment practices. Instead of lots of small deployments, hundreds of PRs were bundled into a single deployment.
Relying on manual processes that were different for each service, developers would basically deploy blindly. And because of the slow and untransparent deployment process, some software got written but never deployed, while others got deployed accidentally. In short, deploying software was error-prone and a huge pain for everyone. We needed easy, reliable automated deployments.
Our path to zero-touch deployments
In 2021, we started building a system that would enable canary deployments and health metrics checks. It had three main components: Argo Rollouts, Linkerd, and Nginx.
We use Argo CD for our deployment pipeline: for the most part, developers only need to interact with Argo , and they trust it to be able to do smooth deployments anywhere in the call graph of the application. We rely on Argo’s integration with Linkerd to actually provide this capability, allowing Linkerd to actually shift traffic around. This allows us to give our developers a clean, straightforward experience, while still being able to gracefully roll out workloads where NGINX wouldn’t be able to directly control them.
In the diagram below, you can see data traffic represented as black and control traffic in dashed arrows. For traffic coming into the cluster we use the Nginx ingress which handles the TLS termination. At the time, the Nginx traffic shifting was pretty bare-bones. It worked but had to be configured to shift by pod count rather than individual percentage.
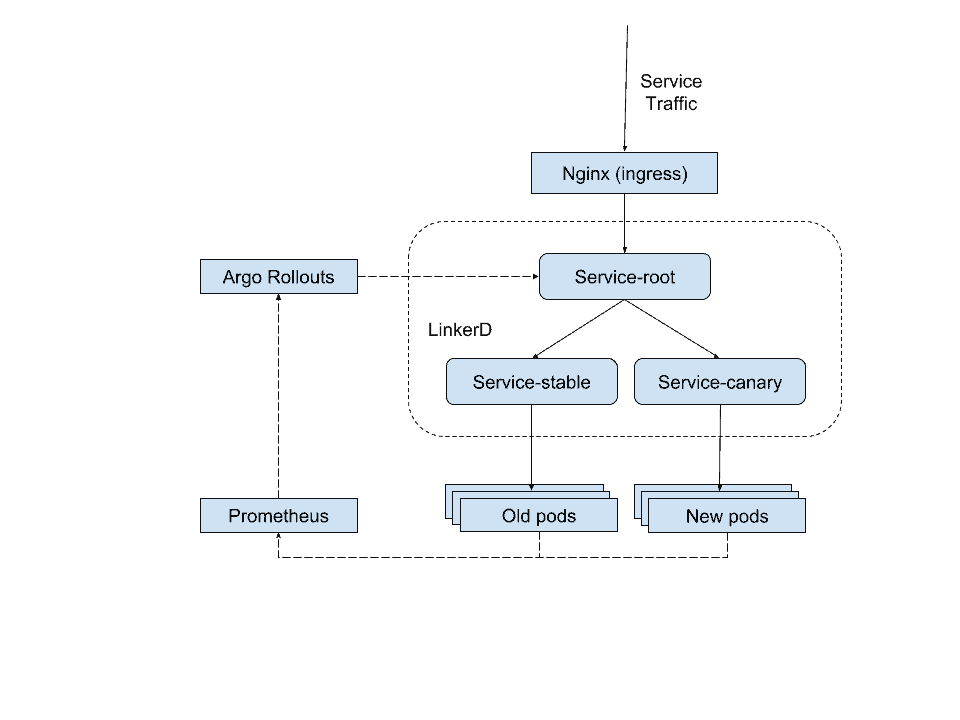
Our main concern was to achieve high control over how traffic was routed in our Kubernetes cluster. Today we’ve implemented a zero-touch deployments (ZTD) approach, deploying each change and monitoring for problems that require rollbacks.
Adopting a service mesh
Whenever we adopt a new technology, we do extensive research. Our service mesh evaluation process was no different. We looked into Linkerd, Istio, and some other Envoy-based meshes. While we were able to get the other service meshes up and running, they were a lot more complex than Linkerd. Ultimately, we didn’t see sufficient benefit for accepting that operational overhead. At the end of the day, Linkerd’s reliability and operational simplicity made the difference. It basically just worked from the get-go.
We had some simple Go services running in a matter of days. A little more difficult was figuring out what breaks when you turn on the mesh. We had to tweak some gRPC settings in Node, for example. But over all, it took us a few weeks to get everything sorted and to be able to start the main production migration.
Besides helping us to route traffic to specific services, we also encountered a very responsive and welcoming community. On a few occasions, we needed help and asked questions on the Linkerd Slack channel and got answers fairly quickly. We submitted a few bug reports and a PR, and the maintainers were always responsive.
Reducing friction and developer cycle time
Our new deployment process minimized friction and decreased cycle time. And that is business-critical for Plaid. After all, we are a tech company, and when there’s an issue or a feature request, we must move at a tech-industry pace. With hundreds of services and hundreds of developers, that means supporting a self-service deployment pipeline that’s still safe enough for the financial sector.
Today, deployments don’t require manual intervention, and we minimized the number of bugs that reach production by automatically rolling bad code back without requiring human intervention.
We are all open source fans and use multiple CNCF projects, including Kubernetes, of course, Cilium for our CNI, Helm for some installation management, Prometheus and Thanos for monitoring, and Argo Rollouts for CD. We also use NGINX as our ingress, and Atlantis (with Terraform) for infrastructure configuration.
Hundreds releases per day across hundreds of services
Today, we are doing hundreds of releases a day, across hundreds of services, with seamless automatic monitoring and rollbacks if needed. For most developers, this means they can simply submit a pull request, and the new version of their service is active and running with no further attention from them. All that in less than 30 minutes from merging to production. And This happens worldwide, across AZs, with no additional effort. We’re confident that, what is in git, is running in production. Preventing state drift has saved us from many problems. We’ve also caught several configuration bugs that are detectable only in production.
We achieved that by using Linkerd’s Argo Rollouts integration, allowing for smooth, automated canary releases for every service, every time. Developers interact with Argo. it’s rare for them to even need to think about the mesh. The mesh just transparently provides everything that Argo needs to do clean canary deployments anywhere at all in our call graph.
This setup has been great. And the fact that we are able to safely deploy code later in the day or on weekends has reduced our team’s stress levels immeasurably.