


Ambassador post by Zou Nengren
With the announcement of CentOS discontinuation by the CentOS community , along with the set dates for service termination, we have put the switch to a new container operating system on our agenda. Based on factors such as migration cost, smoothness of transition, and maintenance difficulty, we have chosen AlmaLinux from the RHEL series as an alternative solution.
NOTE: AlmaLinux is just one of the replacement options available within the RHEL ecosystem. Our choice is based on our specific production needs and does not necessarily apply to everyone.
AlmaLinux 9 defaults to using cgroup v2, and this configuration affects some underlying components. Therefore, certain adaptations and compatibility work need to be done. This article presents the best practices for migrating Kubernetes cluster nodes from CentOS to AlmaLinux which involves removing dockershim and utilizing cgroup v2 for node resource management.
Why Cgroup v2?
Effective resource management is a critical aspect of Kubernetes. This involves managing the finite resources in your nodes, such as CPU, memory, and storage.cgroups are a Linux kernel capability that establish resource management functionality like limiting CPU usage or setting memory limits for running processes.
When you use the resource management capabilities in Kubernetes, such as configuring requests and limits for Pods and containers, Kubernetes uses cgroups to enforce your resource requests and limits.
The Linux kernel offers two versions of cgroups: cgroup v1 and v2.
Here is our comparison between the two versions based on our research:
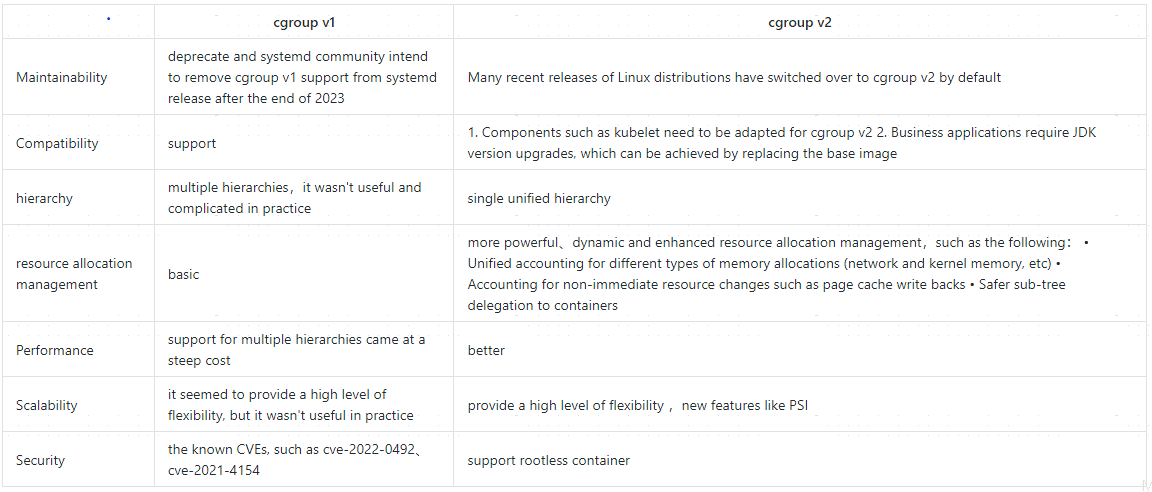
cgroup v2 has been in development in the Linux Kernel since 2016 and in recent years has matured across the container ecosystem. With Kubernetes 1.25, cgroup v2 support has graduated to general availability.
What issues were encountered?
Java applications
JDK-8146115 added Hotspot runtime support for JVMs running in Docker containers. At the time Docker used cgroups v1 and, hence, runtime support only includes cgroup v1 controllers.
JDK-8230305 extended functionality of JDK-8146115 to also detect cgroups v2. That is iff cgroups v2 unified hierarchy is available only, use the cgroups v2 backend. Otherwise fall back to existing cgroups v1 container support.
require version:jdk8u372, 11.0.16, 15 and later
Kubernetes
Currently, the version of Kubernetes in production is 1.19 and enabling cgroup v2 support for kubelet is proving to be challenging. While a comprehensive upgrade of Kubernetes is being researched and prepared, we are currently focusing on implementing cgroup v2 support specifically for kubelet. This approach allows for a shorter implementation time while laying the foundation for the subsequent comprehensive upgrade.
To enable cgroup v2 support, several adjustments need to be made to various components:
1. Kernel Version: We are currently using kernel version 5.15, which meets the minimum requirement for cgroup v2 (4.14). However, it is recommended to use kernel version 5.2 or newer due to the lack of freezer support in older versions.
2. Systemd and Runc: It is highly recommended to run runc with the systemd cgroup driver (`runc –systemd-cgroup`), although it is not mandatory. To ensure compatibility, it is recommended to use systemd version 244 or later, as older versions do not support delegation of the `cpuset` controller.
3. Kubelet : The vendor for kubelet needs to upgrade the runc version. Currently, the latest fully supported version of runc for cgroup v2 is rc93. To minimize changes, we have chosen rc94 and modified the kubelet code to internally maintain runc rc94. This allows us to merge the necessary cgroup v2-related pull requests. However, in rc95, there are significant changes to the cgroup.Manager interface, which does not align with the principle of minimal changes.
metrics-server retrieves resource usage information of nodes and pods using kubelet summary and other interfaces. This data is crucial for Horizontal Pod Autoscaling (HPA) based on resource scaling. To eliminate dockershim, the kubelet should utilize the systemd cgroup driver and configure the runtime accordingly.
--container-runtime=remote --container-runtime endpoint=unix:///run/containerd/containerd.sock4. Containerd : starting from version 1.4, containerd supports cgroup v2. We have successfully validated the removal of dockershim and conducted thorough testing of business operations in the testing environment. With the successful testing, we will proceed with the production rollout. Similar to kubelet, containerd also requires the systemd cgroup driver. Use the following configuration for the systemd cgroup driver:
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = trueThe configuration of the sandbox image and registry can be customized based on specific requirements.
Systemd with cilium
SystemD versions greater than 245 automatically set the rp_filter value to 1 for all network interfaces. This conflicts with Cilium, which requires rp_filter to be 0 on its interfaces, leading to a disruption in out-of-node IPv4 traffic.
Therefore, it is crucial to exercise caution before upgrading SystemD, as demonstrated by the failure experienced by Datadog, which served as a significant warning.
on March 8, 2023, at 06:00 UTC, a security update to systemd was automatically applied to several VMs, which caused a latent adverse interaction in the network stack (on Ubuntu 22.04 via systemd v249) to manifest upon systemd-networkd restarting.Namely, systemd-networkd forcibly deleted the routes managed by the Container Network Interface (CNI) plugin (Cilium) we use for communication between containers. This caused the affected nodes to go offline.
Additionally, when container runtimes are configured with cgroup v2, the Cilium agent pod is deployed in a separate cgroup namespace. For example, Docker container runtime with cgroupv2 support defaults to private cgroup namespace mode. Due to cgroup namespaces, the Cilium pod’s cgroup filesystem points to a virtualized hierarchy instead of the host cgroup root. Consequently, BPF programs are attached to the nested cgroup root, rendering socket load balancing ineffective for other pods. To address this limitation, work is being done in the Cilium project to revisit assumptions made around cgroup hierarchies and enable socket load balancing in different environments.
Don’t worry, these issues have already been fixed by the community.
Conclusion
During the testing process of Cgroup V2 and removing dockershim in our testing environment, we conducted extensive adaptation and stability tests. Our long-term analysis revealed that the benefits of adopting this technology roadmap far outweigh the initial investment. As part of our plan, we intend to promote the adoption of Cgroup V2-based machines in production. This will involve a meticulous testing and validation process, followed by a gradual rollout in production environments. We will start with offline applications such as logging and big data applications.
The Cloud Native Computing Foundation’s flagship conference gathers adopters and technologists from leading open source and cloud native communities in Shanghai, China from 26-28 September, 2023. We are considering submitting a proposal for a presentation at KubeCon 2023, where we will have the opportunity to share the latest developments and insights with the conference attendees.
https://bugs.openjdk.org/browse/JDK-8230305
https://kubernetes.io/blog/2022/08/31/cgroupv2-ga-1-25/
https://www.kernel.org/doc/html/latest/admin-guide/cgroup-v2.html
https://github.com/cilium/cilium/issues/10645