

Guest post originally published on the ARMO blog by Rotem Refael, Director of Engineering, ARMO
Kubernetes is a powerful platform for managing containerized applications at scale, but configuring a Kubernetes cluster can be complex and challenging. In this post, we’ll explore various key considerations for optimizing a Kubernetes cluster, including different cluster, node, and tenancy configurations.
Kubernetes is a powerful platform for managing containerized applications at scale, but configuring a Kubernetes cluster can be complex and challenging. With multiple microservices and developers working simultaneously, it’s essential to consider the optimal cluster and node configurations, minimize risks across different applications, and implement sandbox solutions where necessary.
Kubernetes provides excellent scalability and resilience to applications by automatically handling tasks such as load balancing and scaling up/down based on demand. However, achieving optimal scalability and resilience also requires careful consideration of factors such as resource utilization, network topology, and storage requirements.
In this post, we’ll explore various key considerations for optimizing a Kubernetes cluster, including different cluster, node, and tenancy configurations. By the end of this article, you’ll clearly understand the critical factors that can help you make informed decisions to improve your Kubernetes architecture’s security, efficiency, and ease of management.
Why is your Kubernetes configuration so important?
Kubernetes is designed for managing large-scale containerized applications. Suppose your organization serves 1,000 concurrent users with 10 microservices and 30 developers. You have to ensure each application team can access the resources they need while also mitigating risks for different applications sharing compute resources.
This is because 1,000 users will connect and share their data, like addresses or credit card information, with the application instances running inside containers on the same servers. You also need to set up multiple environments, including dev, staging, and production, to make sure changes are tested before going live.
Achieving all of this requires careful consideration of your cluster and node configuration, including the number and size of nodes, sandbox solutions, and limited communication between services. Below, we’ll delve into these and other best practices to optimize your Kubernetes architecture.
Single or multiple cluster
When designing your cluster architecture, one of the first decisions is whether to use a single cluster or multiple clusters. Each approach has its pros and cons. Using a single cluster can simplify management and reduce resource overhead, but it can also increase the risk of a single point of failure. In the case of failure, this will lead to a large blast radius, along with the possible consequences of prolonged downtime, data loss, and damage to the organization’s reputation. It is therefore important to carefully consider the trade-offs and design a cluster architecture that balances the need for simplicity with the need for fault tolerance.
In contrast, using multiple clusters can provide greater fault tolerance but can increase management complexity and resource overhead.
Cluster size: nodes
Another critical consideration for Kubernetes cluster architecture is determining the number and size of nodes within the cluster. Both factors will impact the overall capacity of the cluster, as well as its ability to handle upgrades and outages.
For managing multiple applications that require different resources, one approach is to use affinity and scheduling configuration to restrict certain applications to specific nodes. Another way is to set appropriate resource requests and limits for each application, ensuring that it has access to the necessary resources for optimal operation.
Node size and quantity
You will also have to consider if you need fewer large VM nodes or more small VM nodes. Fewer but large nodes can be more efficient for per-node overhead but can be challenging to handle during upgrades and outages. For instance, the rolling update approach will update the nodes sequentially; if there are a small number of nodes, it could be a disaster when a node cannot connect to the cluster or has to wait for its volume to be attached.
On the other hand, a larger number of smaller nodes can improve bin-packing efficiency but can lead to higher per-node management overhead. Mitigating these risks requires careful planning, including having backup plans in case of failures and taking a more cautious approach to rolling updates.
The advantages and disadvantages of VM dispersion can be summarized in the following table:
| Many Small Nodes | Few Large Nodes | |
| Availability | ✅ | ⚠️ |
| Scheduling Efficiency | ✅ | ⚠️ |
| Management Complexity | ⚠️ | ✅ |
| Scalability and Resilience | ✅ | ⚠️ |
Table 1: Impact of quantity and size of nodes
Organizations can also implement sandbox technologies like gVisor or Firecracker VMs to help reduce risks and improve security in a cluster. These solutions make sure that workloads are isolated from each other and run in a secure and protected environment. In addition, there are some considerations for large clusters in Kubernetes, as it is designed for no more than 110 pods per node and no more than 5,000 nodes in total.
Cluster Segmentation: namespaces for teams vs. namespaces for tenants
Another critical consideration for Kubernetes cluster architecture is determining the appropriate namespace configurations for different teams or tenants. Namespaces are a way to divide a cluster into smaller pieces and provide isolation between other teams or tenants.
There are two main approaches to namespace configuration: namespaces for teams and namespaces for tenants. Namespaces for teams involve creating a separate namespace for each development team within the organization. This approach can improve resource utilization and ease of management, but it can also lead to more complex management and resource allocation.
Namespaces for tenants involve creating a separate namespace for each tenant using the cluster. This approach can be beneficial for multi-tenant environments, as it provides greater isolation between tenants and allows for more fine-grained resource allocation. However, it can also lead to higher per-tenant overhead and be more challenging to manage.
In the following diagram, Team A and Team B share the cluster via multi-team tenancy, while Team C implements a multi-customer tenancy approach:
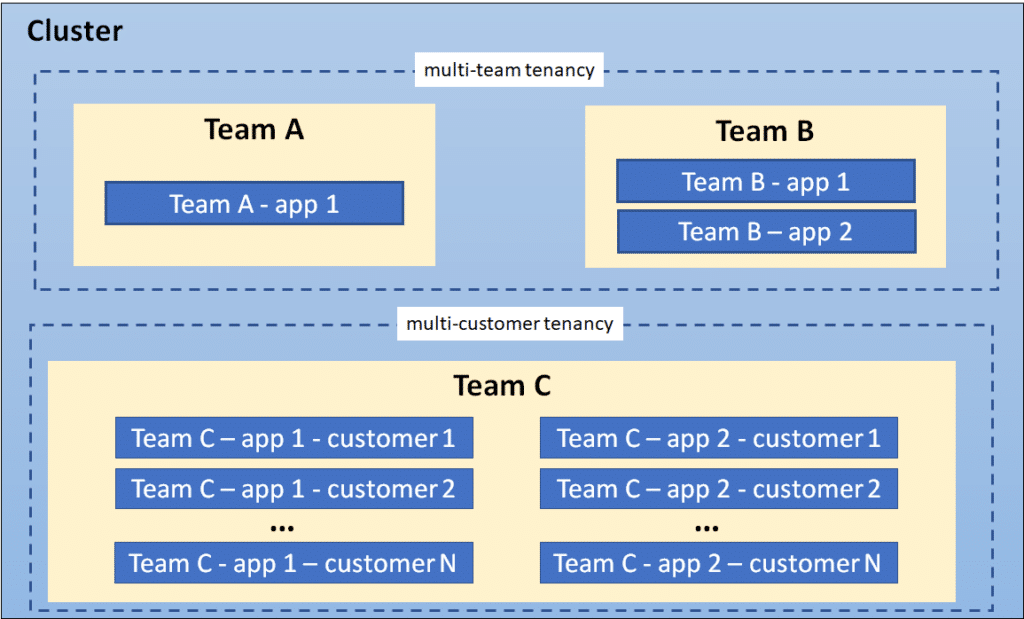
When determining the appropriate namespace configuration, it’s crucial to consider factors such as resource utilization, ease of management, and the number of teams or tenants using the cluster.
Limiting services from talking to each other
Another vital consideration for Kubernetes cluster architecture is how to limit communication between different services within the cluster. This can reduce the risk of security breaches and also help improve overall performance and stability.
One approach to limiting communication is through network policies, which can restrict the traffic between services at the network layer. They define rules for how traffic flows between different parts of the cluster and ensure that only authorized traffic is allowed to pass between services.
Another method is to use service mesh solutions like Istio. These tools provide additional features for managing communication between services, including traffic routing, load balancing, and service discovery. They also offer other security features, for example, requiring identity verification for communication between services.
Operations and deployment
In addition to choosing the right cluster/node configurations and implementing sandboxing solutions and network policies, organizations must pursue the best operations and deployment practices. This includes ensuring security and compliance in Kubernetes environments and improving collaboration between development and operations teams.
One best practice is image scanning, which involves analyzing images for vulnerabilities and compliance issues. By scanning images before deployment, organizations can ensure that only safe and compliant images are used in their clusters. Software bill of materials (SBOM) vulnerability scanning and cluster configuration scanning are also essential for maintaining security and compliance in Kubernetes environments.
A useful tool for deployments is GitOps, which manages deployments and infrastructure as code. By following this framework, all changes to the cluster are made through pull requests to a Git repository, which serves as a single source of truth for the system’s desired state. This helps improve collaboration between development and operations teams and ensures that deployments are consistent and auditable. The automation inherent in GitOps can help alleviate the challenges that arise from the architectural complexity of Kubernetes. By using Git as a single source of truth, developers can more easily manage complex deployment pipelines and maintain consistency across environments.
Conclusion
Optimizing Kubernetes cluster architecture requires careful consideration of various factors, including the choice of cluster and node configurations, sandboxing solutions, network policies, and best practices for operations and deployment. By making informed decisions in these areas, organizations can improve the security, efficiency, and ease of management of their Kubernetes environments.
Whether you’re managing a single cluster or multiple clusters, or are adopting a multi-tenant or single-tenant approach, it’s essential to carefully weigh the benefits and drawbacks of different configurations and choose the method that best meets your needs. Once on the right path, organizations can unlock the full potential of Kubernetes and achieve their goals for modern, cloud-native infrastructure.