
Guest post by Datenlord
Introduction to database isolation levels
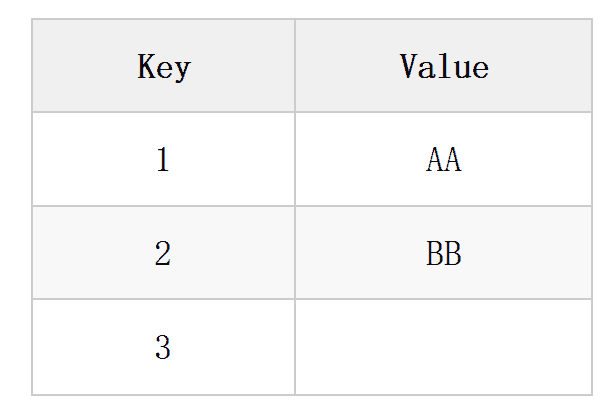
When processing multiple transactions at the same time, the database needs to decide whether the transactions can see each other’s changes, how much they can see, etc. According to the strict level of isolation, they can be classified from strict to loose as Serializable, Repeatable reads, Read committed, Read uncommitted. We use the following example of KV storage to explain these four isolation levels. The initial situations of the KV storage are as follows:
Table1:
Read uncommitted
When two transactions are being executed at the same time, top-down is the order of execution.
Table 2 :
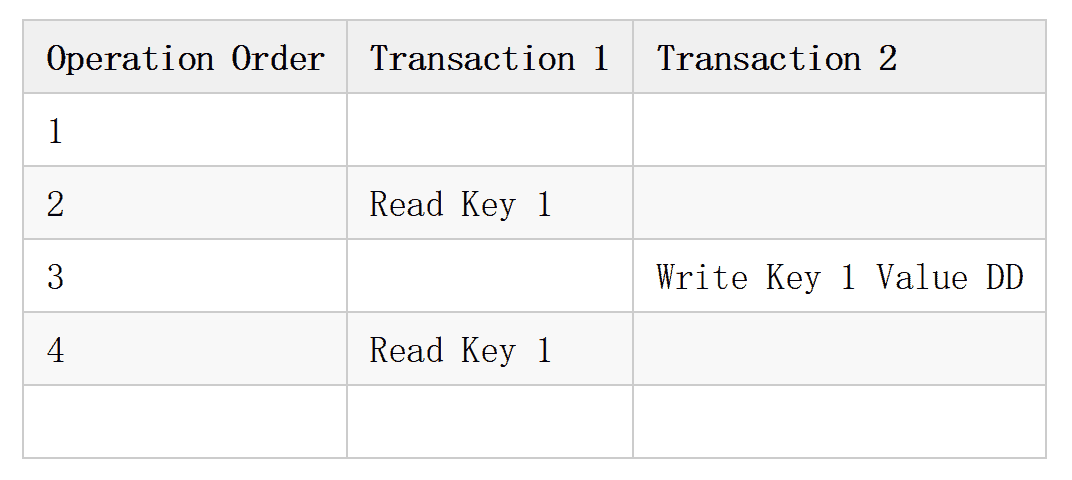
Under the isolation level of Read uncommitted, multiple transactions executing at the same time are able to see each other not committing the writing operations, which can be considered almost useless.
In the above example, Operation 2 reads “AA” and even though the second transaction eventually Rollback, Operation 4 still reads “DD”. When two transactions are being executed simultaneously in the Read committed, they follow top-down order.
Table 3:

Under the isolation level of Read committed, only the result after Commit can be seen. So in the execution order of Table 2, both Operation 2 and 4 can read the value of “AA”, that is, the value of Key 1 is not changed. If two transactions are executed as in Table 3, Operation 2 will read “AA” and Operation 5 will read “DD”, because Transaction 2 has been executed successfully at the time.
Repeatable read
If Transaction 1 in Table 3 has two consecutive read operations while the user wants to guarantee that the same value is read, then the repeatable read isolation level should be used. Under this isolation level, multiple reads of the same data in the same transaction are guaranteed to yield the same value, even if the data is modified by other committed transactions in the process. Of course, there are cases where isolation is not guaranteed in this isolation level, which is shown as follows:
Table 4:

Under the isolation level of repeatable read, Operation 2 returns [“CC”] as result, which means only the value of Key 3 is returned, while that of Operation 5 is [“CC”, “DD”]. To summarize, the isolation level of repeatable read still cannot perfectly handle situations involving multiple pieces of data, especially when new data is inserted or deleted.
Serializable
The strictest isolation level is called Serializable, which is also the most perspicuously defined. The execution result under this level is “as if” all transactions were serialized and executed one by one.
It is worth emphasizing the word “as if” in the above sentence. To improve performance, few databases use serial execution on the real meaning of physical to ensure Serializable, but only to achieve a similar effect, which can be achieved in a variety of ways. There is a subcategory under the Serializable level called Snapshot, which is similar to Serializable but slightly less constrained. It is because of the relaxation of constraints that gives a better-performed implementation and makes it the default supported isolation level by most databases.
Let’s talk about Snapshot, and by extension, the MVCC implementation.
Snapshot isolation level and MVCC
To distinguish between the strictest Serializable and Snapshot, let’s look at the following two transactions as examples.
Table 5:
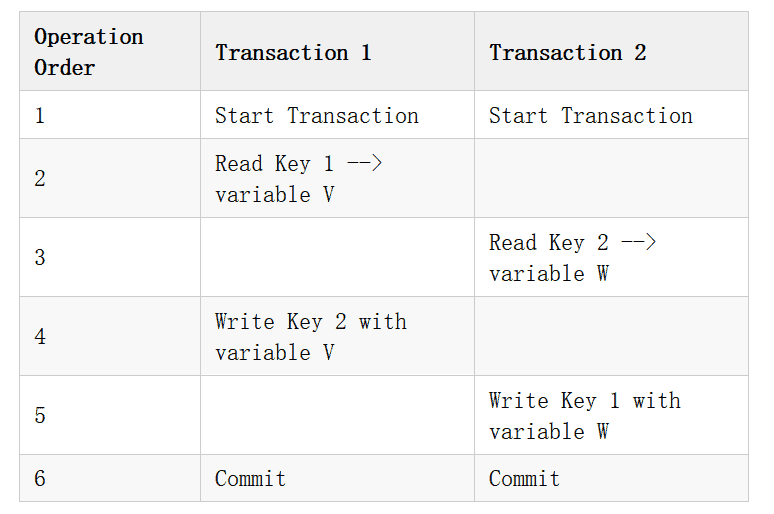
If strictly following the Serializable isolation level, regardless of either Transaction 1 or 2 is executed first, the ultimate value of Key 1 and 2 is the same, either “AA” or “BB”.
However, when executed under the Snapshot level, the result is that the values of Key 1 and 2 are swapped.
The isolation power of Snapshot is obviously weaker in this case. Isolation seems helpless in dealing with the order of transactions with read-write intersections, while only ensuring the order of transactions with write conflicts.
While the above example looks specifically at the differences between the Snapshot isolation level and Serializable, we have not yet fully described the characteristics of Snapshot:
- Transactions in Snapshot have two important timestamps, a read timestamp R and a write timestamp W. All read operations after R can only read the data committed before R.
- Snapshot allows two transactions that do not have a write intersection to execute simultaneously and in parallel.
In order to satisfy both of these features, it is natural to think of saving multiple versions for each data, so that when a write operation is committed, the new data is saved in the new version while the old one is not covered, which is what we call MVCC (Multiversion concurrency control).
We know that there is no conflict between read operations, and write operations cannot be executed simultaneously under the Snapshot level (or Roll back if a conflict is found), so MVCC works mainly when there is a conflict between read and write operations, allowing two seemingly conflicting transactions to execute concurrently.
MVCC also requires garbage collection, otherwise too much old version data will take up unnecessary storage space. The next question is, how do you determine whether a version of data can be deleted? The answer is that it can be deleted when all read operations involved in such version of data are completed, provided that there is a newer version of data ahead.
Some little thoughts
In the process of introducing MVCC we can easily capture the following key points:
- Multiple versions.
- Garbage handling.
- Improving the efficiency of concurrent operations.
In a previous article by DatenLord titled “Memory Management for Rust Language Lock-Free Data Structures”, we introduced another technology related to these keywords, which is the “epoch-based memory management” (epoch) method for lock-free data structures. Epoch maintains the memory state of two generations, and when the memory of the oldest generation is no longer accessible, then the corresponding memory will be reclaimed and released, and a new generation will be opened. The purpose of doing this is also to allow the operation of modifying the data of the new generation and the operation of reading the data of the old generation to be parallelized, also to achieve read-write concurrency optimization. Of course, in addition to these similarities, there are also differences in that MVCC can simultaneously exist in many versions, while epoch always exists in two versions. This can be interpreted as epoch’s memory management being more granular, so when contention is heavy epoch can sometimes cause an increase in memory pressure.
In general, MVCC and epoch are similar in the central idea of using multi-version memory control technology to solve the problem of concurrent read/write conflicts.
Summary
In this paper, we introduced the four isolation levels of the database and the differences between the different isolation levels with examples.
Later, we dug into details about Snapshot, a most widely used insolation level and its most frequently used implementing method MVCC.
Finally, compared and discussed the memory management mechanisms of MVCC and lock-free data structures.
DatenLord project Xline focuses on cross-cloud metadata management KV storage and is currently using MVCC for database isolation in practice. If you want to learn more about it, please refer to the Xline GitHub link: https://github.com/datenlord/Xline